





В данной работе представлены результаты исследования и использования асинхронных SQL-запросов с помощью скриптового языка PHP, которые позволят значительно ускорить выполнение массивного SQL-запроса с помощью использования логических ядер процессора. Сам PHP является интерпретируемым языком программирования, и в нем нет возможности управления потоками. Результат ускорения выполнения скрипта достигается за счет разбиения типового запроса на множество подзапросов, в зависимости от количества ядер сервера, выполняя их асинхронно. После выполнения всех подзапросов, результирующий ответ собирается из полученных данных и отправляется пользователю.
Ключевые слова: PHP, SQL, cURL, многопоточная обработка, потоки, логические ядра процессора
Значимость параллельного выполнения кода в наше время достигает максимального значения. Все современные приложения, написанные на разных языках программирования, так или иначе используют потоки. На сегодня многими производителями процессоров дальнейшее увеличение числа ядер процессоров признано как одно из приоритетных направлений увеличения производительности, так как улучшение архитектуры процессоров не дают такой прирост производительности, которую дает увеличение количества ядер.
Язык PHP с помощью Apache также работает с потоками, создает их при получении сообщений от пользователя, но управлять этими потоками нельзя, сами по себе они изолированы друг от друга. Из-за этого приходится искать обходные пути для создания нескольких процессов обработки данных. Такие решения нельзя назвать полноценными многопоточными приложениями, но они все равно выполняют свою задачу по минимизации времени выполнения скриптов.
Одной из реализаций асинхронного выполнения скриптов в PHP является cURL. Это свободная, кроссплатформенная служебная программа командной строки, позволяющая взаимодействовать с множеством различных серверов по множеству различных протоколов с синтаксисом URL. Достоинство такой реализации в том, что она может работать как с самим сервером, так и с внешними ресурсами, а также позволяет контролировать процессы и перехватывать ошибки каждого процесса отдельно, и, если один процесс завершится с ошибкой, остальные продолжат работать и вернут результат. Данная программа добавляет возможность использования мульти-функций, которая позволяет использовать асинхронную обработку множества cURL-дескрипторов. Каждый cURL-дескриптор несет в себе адрес ресурса и дополнительные параметры передачи сообщения, которые хранятся в заголовке сообщения. Все используемые функции для асинхронного выполнения продемонстрированы в таблице 1.
Таблица 1
Мульти-функции программы cURL
|
Функция |
Описание |
|
curl_init |
Инициализирует новый сеанс cURL и возвращает дескриптор, в качестве параметра может использоваться адрес ресурса |
|
curl_setopt |
Устанавливает параметр для указанного сеанса cURL, помещая параметры в заголовок сообщения |
|
curl_multi_init |
Создает набор cURL-дескрипторов и позволяет использовать асинхронную обработку множества cURL-дескрипторов. |
|
curl_multi_exec |
Запускает подсоединения текущего дескриптора cURL |
|
curl_multi_add_handle |
Добавляет обычный cURL, созданный с помощью функции curl_init, дескриптор к набору cURL дескрипторов |
|
curl_multi_strerror |
Возвращает текст сообщения об ошибке, соответствующей заданному коду ошибки CURLM |
|
curl_multi_getcontent |
Возвращает результат операции выбранного дескриптора, если была установлена опция CURLOPT_RETURNTRANSFER, которая отвечает за получение результата |
|
curl_multi_remove_handle |
Удаляет указанный cURL дескриптор из набора cURL дескрипторов |
|
curl_multi_close |
Закрывает набор cURL дескрипторов |
Таким образом асинхронное выполнение сводится к тому, что создается пустой набор cURL-дескрипторов, к нему добавляется нужное количество дескрипторов, используя функцию curl_multi_add_handle, созданных с помощью curl_init и curl_setopt. Следующий шаг — запуск подсоединения (curl_multi_exec). В бесконечном цикле ведется проверка на выполнение (curl_multi_exec сообщает о количестве подсоединений в обработке) или получение ошибки (curl_multi_strerror) каждого дескриптора. После выполнения все подсоединений программа выходит и цикла и начинается обработка результата с помощью функции curl_multi_getcontent для каждого дескриптора отдельно. После получения результата необходимо удалить дескриптор из стека (curl_multi_remove_handle). Последним шагом после обработки все дескрипторов внутри стека необходимо закрыть набор (curl_multi_close). Данный метод отличается своей простотой и имеется возможность отслеживать выполнение подсоединения и получения ошибки. При определении количества созданных подсоединений лучше всего руководствоваться количеством логических ядер процессора, на котором будут производиться вычисления. Так как выполнение скрипта происходит изолированно в одном потоке, то, если использовать меньшее количество подсоединений, не будут задействованы все логические ядра процессора. Если подсоединений будет больше, чем логических ядер, то они все равно не будут выполняться параллельно, и увеличатся накладные расходы на сбор избыточных подсоединений, таким образом, общее время выполнения запроса увеличится. Алгоритм выполнения асинхронных операций показан на рисунке 1.
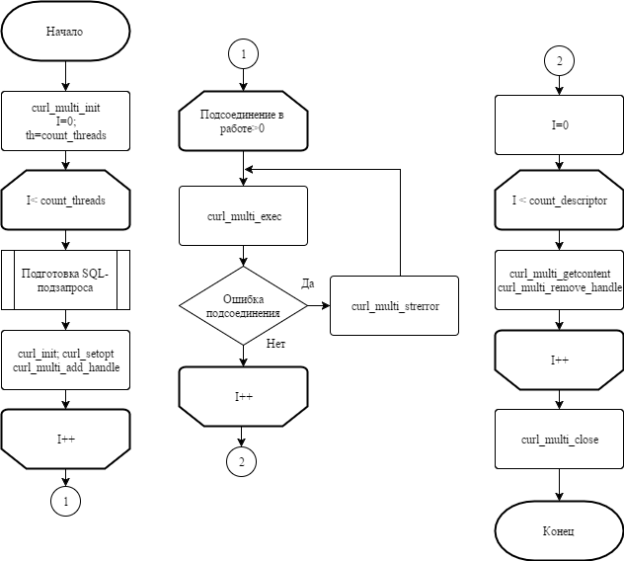
Рис. 1. Алгоритм выполнения асинхронных операций
Блок подготовки SQL-подзапроса описан далее. В результате использования такого подхода теоретически можно достигнуть ускорение работы приложения в n раз, где n — количество логических ядер и подсоединений. Но на практике дают о себе знать накладные расходы приложения, о чем будет сказано далее.
Далее в качестве СУБД будет использоваться PostgreSQL, но возможность использовать описанный метод не ограничивается только выбранной СУБД. Если необходимо выполнить массивный запрос, то можно его разделить на несколько подзапросов, выполнить их параллельно, а потом объединить в конечный результат. Речь идет именно о крупных SQL-запросах, иначе такая техника не имеет смысла, так как накладные расходы (создание подзапросов, создание дескрипторов, отправка, сборка) будут занимать больше времени, чем работа выполнение самого запроса.
Методов разбора SQL-запроса может быть несколько, речь идет о SELECT запросах:
– Горизонтальный — балансировка идет с помощью разбиения записей SELECT оператора, где используется большое количество возвращаемых колонок. Зная общее количество колонок запроса (k) и количество логических ядер процессора (n), на котором работает сервер. Создается n дескрипторов, и в качестве входного параметра для SELECT оператора помещается k/n+z записей, где z — остаток от деления. После завершения работы всех дескрипторов возвращаемый данные каждого из них добавляются в результирующий массив.
– Вертикальный — данный метод основан на балансировке, используя операторы LIMIT и OFFSET, которые позволяют получать данные из таблицы частями. Для получения информации о том, сколько в результате запроса вернется строк, необходимо воспользоваться count-запросом для получения количества строк в таблице (k). Далее алгоритм подсчета схож с предыдущим методом. Зная количество логических ядер (n), создаются n дескрипторов, в которые помещаются в качестве входных аргументов параметры операторов LIMIT и OFFSET. После выполнения всех подсоединений формируется результирующий массив.
Метод следует выбирать, основываясь на том, где больше возвращаемых колонок или строк. При делении числа строк или колонок может появиться остаток от деления. Этот остаток в качестве пропущенных записей можно добавить в последнее подсоединение или добавить по 1 записи в каждый подзапрос, если это возможно. В целом оба метода схожи и различия имеют только в формировании результирующего массива. Алгоритм методов подготовки SQL-запроса показана на рисунке 2.
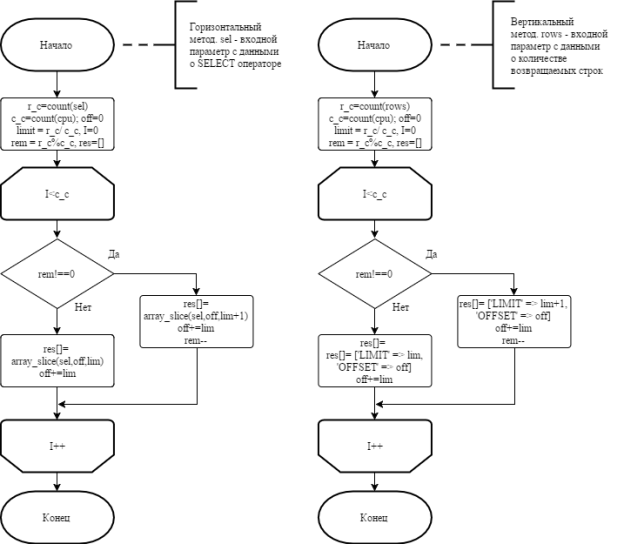
Рис. 2. Алгоритм подготовки SQL-запроса
На практике такой подход выполнения крупных SQL-запросов дает значительный прирост производительности, ускоряя выполнение запроса. Для примера можно выполнить один крупный SQL-запрос стандартным методом и с использованием асинхронного выполнения. Типовой запрос имеет следующий вид: SELECT calc_func(1), … calc_func(8) FROM table, где каждая возвращаемая колонка — функция с долгими подсчетами. Диаграмма загрузки логических ядер процессора при выполнении SQL-запроса стандартными средствами показана на рисунке 3.
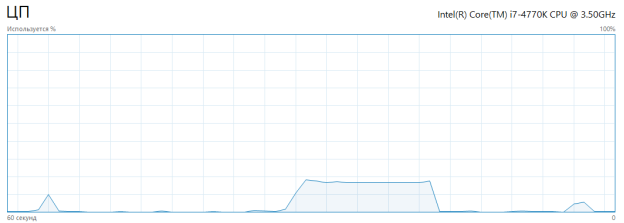
Рис. 3. Загрузка ядер процессора при обычном выполнении запроса
Запрос выполнился за 11.09 сек. Из диаграммы, показанной на рисунке 3, можно увидеть, что при выполнении запроса стандартными средствами, запрос обрабатывается на одном логическом ядре процессора, что дает ограничение по производительности. Но если выполнить данный запрос с использованием асинхронных SQL-подзапросов, то результат будет следующий (рисунок 4).
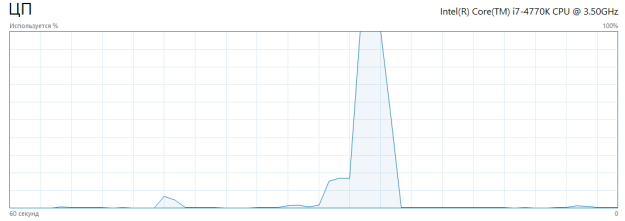
Рис. 4. Загрузка ядер процессора при асинхронном выполнении запроса
Запрос выполнился уже за 3.46 сек. Также можно увидеть, что во время выполнения все логические ядра процессора были максимально загружены. Это достигается путем выполнения каждого SQL-подзапроса на отдельном логическом ядре процессора, при этом, все подсоединения изолированы друг от друга. Если учесть, что процессор имеет 4 логических ядра (технология Hyper Threading была отключена во время тестирования), то с помощью данного метода удалось уменьшить время выполнения скрипта в 3.2 раза, что является хорошим результатом. Естественно, достичь 4-х кратного улучшения производительности практически невозможно, так как здесь и проявляются накладные расходы метода: получение необходимой информации о количестве ядер процессора (можно сделать константой, но не желательно, так как теряется универсальность), подготовка подзапроса, запуск мульти-функций, сборка результирующего массива.
У метода также есть и недостатки, связанные изолированностью подсоединений:
– невозможно отладить отдельное подсоединение, но это решается запуском и отладкой скрипта без использования мульти-функций.
– Сами подсоединения никак не связаны и обмениваться данными не могут ни друг с другом, ни с главным скриптом, из которого был запуск, поэтому после запуска никакой связи с подсоединением не будет, пока скрипт не будет обработан. Поэтому все параметры подсоединения должны быть определены до запуска дескрипторов.
Данный метод вовсе не обязательно использовать только таким способом. Можно использовать его с INSERT и UPDATE запросами, но с разными таблицами, так как одновременное изменение в одной таблице невозможно. Можно использовать метод для получения данных без подготовки подзапросов из разных таблиц, делая это асинхронно, что тоже в значительной мере ускорит выполнение скрипта.
Литература:
1. Gregory Smith // PostgreSQL 9.0 High Performance — 2010. — P.132–169, P.363–391.
2. Josh Lockhart // New Features and Good Practices — 2015. — P.56–89.
3. Клиентская библиотека cURL в PHP // http://php.net/manual/ru/book.curl.php
