





Важную роль в программах распознавания звука имеет такой параметр, как частота дискретизации, так как изначально аналоговый сигнал нужно преобразовать в цифровой для дальнейшей обработки. Микрофон конвертирует звуковые колебания в аналоговый (непрерывный) электрический сигнал. Далее сигнал дискретизируется посредством выборки значений амплитуд сигналов, и производится квантование аналогового сигнала [1]. Согласно теореме Котельникова частота дискретизации в два раза больше верхней границы частот, которые воспринимаются человеком (воспринимаются частоты от 20 Гц до 20 кГц) [2]. Поэтому звук обычно записывается с частотой дискретизации 44,1 кГц.
Современные мобильные устройства уже содержат встроенные аналогово-цифровые преобразователи. То есть для распознавания звука необходимо лишь наличие соответствующего программного обеспечения, для его разработки целесообразно использование библиотек для работы со звуком. Примерами таких библиотек могут служить OpenAL, PortAudio, Audiere и SDL.
OpenAL (англ. Open Audio Library) — кроссплатформенный интерфейс программирования приложений (API) для работы с аудиоданными. Ключевой особенностью является работа со звуком в 3D пространстве и использование эффектов EAX. Поддерживается компанией Creative. [4]
PortAudio является аудиобиблиотекой, которая дает Audacity возможность воспроизводить и записывать звук независимо от используемой платформы. В PortAudio предоставляются кольцевые буферы, средства, позволяющие изменять частоту дискретизации при воспроизведении/записи, и, самое главное, предоставляется интерфейс API, который скрывает различия между аудиообработкой на платформах Mac, Linux и Windows. [5]
Audiere является полностью бесплатной, распространяется по лицензии LGPL, и поставляется с исходниками. Audiere проигрывает следующие форматы звуковых файлов: Ogg Vorbis, MP3, FLAC, несжатый Wav, AIFF, MOD, S3M, XM, и IT. Из платформ поддерживается: Windows, Linux и IRIX. [6]
Simple DirectMedia Layer (SDL) — это свободная кроссплатформенная мультимедийная библиотека, реализующая единый программный интерфейс к графической подсистеме, звуковым устройствам и средствам ввода для широкого спектра платформ. Данная библиотека активно используется при написании кроссплатформенных мультимедийных программ (в основном игр). [7]
Результаты сравнения библиотек представлены в Таблице 1.
Таблица 1
Результаты сравнения библиотек
|
Библиотека |
OpenAL |
PortAudio |
Audiere |
SDL |
|
Свободный доступ |
+ |
+ |
+ |
+ |
|
Кроссплатформенность |
+ |
Mac, Linux, Windows |
Window, Linux, IRIX |
+ |
Рассмотрим алгоритм распознавания шаблона звуковой последовательности. Данные, полученные со звуковой карты, записываются в массив, описывающий изменения амплитуды сигнала с течением времени. Для этого сигнал подвергается преобразованию Фурье. Дальнейшей целью разработчика является определение частотных характеристик сигналов. Оптимальным алгоритмом вычисления преобразования Фурье дискретное является быстрое преобразование Фурье (БПФ) [3]. Основная идея БПФ состоит в том, чтобы разбить исходный N-отсчетный сигнал x(n) на два более коротких сигнала, ДПФ которых могут быть скомбинированы таким образом, чтобы получить Дискретное преобразование Фурье (ДПФ) исходного N-отсчетного сигнала. Для каждого языка существует библиотека, позволяющая выполнить быстрое преобразование Фурье (например, в Java есть библиотека JTransform, а в C для этой процедуры используется FFTW).
Однако при быстром преобразовании Фурье происходит потеря информации о последовательности сигнала. Далее используется «скользящее окно», или блок данных, и трансформируется часть сигнала, которая попадает в «окно». Существует несколько подходов определения размера каждого блока. К примеру, если записывается двухканальный звук с размером образца равным 16 бит и с частотой дискретизации 44100 Гц, одна секунда такого звука занимает 176 Кб памяти (44100 образцов * 2 байта * 2 канала). Если установить размер «скользящего окна», равный 4 Кб, то каждую секунду необходимо будет проанализировать 44 блока данных. Для детального анализа композиции такое разрешение слишком велико
(I = ʋ * b * n, где
I — количество информации
ʋ — частота дискретизации
b — размер образца а байтах
n — число каналов).
Следующим этапом является формирование цифровой сигнатуры, при этом ставится задача выбора важных частот из всего множества. Особого внимания требуют частоты с наибольшими амплитудами. Эти частоты могут значительно варьироваться, образуя серьезные по величине интервалы и тем самым создавая дополнительные трудности. Для решения данной проблемы частотный диапазон разбивается на небольшие интервалы (деление осуществляется с учетом частот, которые характерны для важных музыкальных компонентов). Возможные интервалы частот указаны на Рисунке 1.
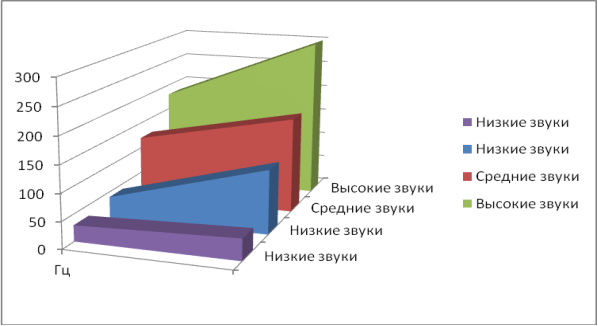
Рис. 1. Интервалы частот
От 30 Гц до 40 Гц, от 40 Гц до 80 Гц и от 80 Гц до 120 Гц для низких звуков, от 120 Гц до 180 Гц и от 180 Гц до 300 Гц для средних и более высоких звуков. Выбор обусловлен тем, что с помощью интервалов для низких звуков удается распознать инструменты с низкой частотой звукоизвлечения, а с помощью средних и высоких — вокал и другие. В каждом интервале осуществляется поиск наибольших значений амплитуды сигнала. Эти данные представляют собой отдельные сигнатуры, которые, в свою очередь, являются элементами сигнатуры целого произведения.
Далее полученная сигнатура сравнивается с теми, что хранятся в базе данных. Для упрощения поиска нужного трека их сигнатуры используются как ключи в хэш-таблице. Однако существует следующая проблема при поиске вычисленных хэш-тегов в базе даных: у многих фрагментов различных музыкальных дорожек хэш-тэги совпадают (некоторые фрагменты различных композиций могут быть похожими или даже идентичными). Поэтому важно помимо хэш-тегов проверять отметки времени. Если хэш-тег совпадает с 2 композициями одновременно, необходимо проверить совпадение хэш-тегов в другом временном промежутке. Запись, на основе которой ищется название произведения, может включать в себя сильный шум, что приводит к расхождениям при сравнении. Поэтому, вместо того, чтобы пытаться исключить из списка совпадений всё, кроме единственной верной композиции, в конце процедуры сопоставления с базой данных записи, в которых нашлись совпадения, сортируются в убывающем порядке. Чем больше совпадений — тем выше вероятность рассчитать нужную композицию.
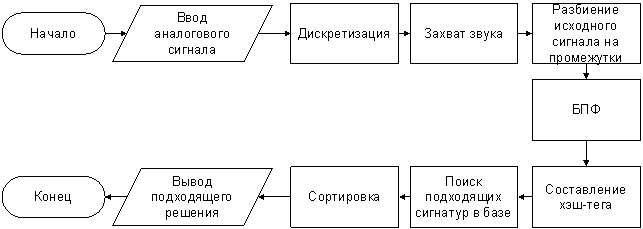 Рис. 2. Схема алгоритма распознавания музыкальной композиции
Рис. 2. Схема алгоритма распознавания музыкальной композиции
Таким образом, была рассмотрена цепочка преобразований, через которые проходит музыкальная композиция, прежде чем нами будет получена информация о ее названии и исполнителе. Изначально происходит захват звука, его дискретизация, затем анализируются его частотные характеристики, вычисляются хэш-теги, после чего они сравниваются с теми, что хранятся в базе данных программы.
Литература:
- Самофалов К. Г., Романкевич А. М., Валуйский В. Н., Каневский Ю. С., Пиневич М. М. Прикладная теория цифровых автоматов. — К.: Вища школа, 1987. — 375 с.
- Ястребов И. П. Дискретизация непрерывных сигналов во времени. Теорема Котельникова. // Электронное учебно-методическое пособие. — Нижний Новгород, 2012. — 31 с.
- Александров В. А. Преобразование Фурье. — Учеб. пособие.: Новосибирск, НГУ, 2002. — 62 с.
- https://ru.wikipedia.org/wiki/OpenAL
- http://rus-linux.net/MyLDP/BOOKS/Architecture-Open-Source-Applications/Vol-1/audacity-05.html
- http://rsdn.ru/forum/media/1104238.1
- https://ru.wikipedia.org/wiki/Simple_DirectMedia_Layer
