Мобильные устройства, которые подключаются к интернету через сотовые сети, быстро становятся основным средством для доступа к веб-контенту. Сотовые провайдеры («поставщики») широко применяются веб-прокси и другими настройками промежуточных устройств для обеспечения безопасности, оптимизации производительности и технических причин движения. Тем не менее, распространенность и политика этих веб-прокси, как правило, непрозрачны для пользователей, и трудно измерить без привилегированного доступа к устройствам и серверам. В этой статье мы представляем методику обнаружения веб-прокси, не требующих доступа к низкоуровневой трассировки пакетов на устройстве, ни доступа к контактному серверу. Мы продемонстрируем жизнеспособность этой техники, используя контролируемые эксперименты, и представим результаты работы нашего подхода на нескольких производственных сетях и популярных веб-сайтах. Далее мы изучим поведение этих веб-прокси, в том числе кэширование, переадресацию, и переписывание контента. Наш анализ может выявить как влияет веб-прокси на производительность сети и мы выпустим приложение для Android под названием Proxy Detector на Google Play Store, позволяющий обычным пользователям с непривилегированными (некорневыми) устройствами понять размещение веб-прокси.
Такие мобильные устройства как смартфоны и планшеты становятся все более вездесущими, сотовая сеть передачи данных расширена для обслуживания роста их сетевого трафика. Отчасти из-за дефицитной и дорогостоящей полосы пропускания, провайдеры услуг сотовой связи (ППО) размещают веб-прокси и другие настройки на промежуточных устройствах для эффективного использования этих ограниченных ресурсов и для повышения производительности сети.
Вывод нашей методики основана на наблюдении, в котором веб-прокси, за которым мы наблюдали в мобильных сетях, вклинится на трафик порта 80 (протокол http), но не вклинится на порт 443 (https), предположительно потому, что они предполагают, что шифрование по протоколу https поможет избежать многих прокси-объектов из рабочей (например, кэширование, транскодирование и перенаправления). Таким образом, мы определяем сервера, которые служат как http, так и https-трафик, а также используем тесты на порту 443, как наш «контроль», что не является субъектом стратегии прокси-сервера.
Одной из ключевых задач нашей работы является обнаружение прокси без доступа к низкоуровневой трассировки пакетов, без доступа к Web-серверам. Поэтому наша методология должна обеспечить способ сделать вывод, что существует веб-прокси, основанный только на информации, полученной из слоя приложения на клиенте. Достижение этой цели требует от нас решения двух проблем: 1) контроль трафика является предметом доверенности взаиморасположения, и 2) выявление влияния этого вмешательства.
Для решения первой задачи, мы опираемся на результаты предыдущих исследований, где веб-прокси работают на только на определенные порты трафика (например, порт 80 для HTTP), но не на другие (например, порт 443 для HTTPS). Таким образом мы прибегаем назад к экспериментам для получения тех же веб-страниц через http и https с того же сервера, 2 — где последний не подлежит взаиморасположению прокси. Для решения второй проблемы мы используем комбинацию функций, которые включают задержку различия и модификацию содержимого.
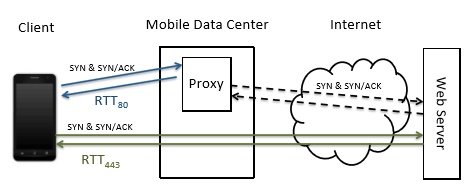
Рис. 1. Диаграмма, изображающая типичный веб-прокси, который разделяет TCP-соединения на порт 80 (http), но не на порт 443 (https)
Проверка наличия прокси-сервера. Мы используем задержку подхода к выводу о существовании веб-прокси. В частности, для каждого направления мы создаем TCP-сокет, и измеряем время приема-передачи (РТТ) между SYN и SYN /АСК, как измеряется клиентом. Мы делаем это на порт 80 и порт 443, вплотную измеряем, затем повторяем эту пару измерений несколько раз к посчитать шум производительности сотовой сети. 3 исходя из наших наблюдений, веб-прокси отправляет пакет SYN/ACK в клиента сразу; однако, пакет SYN отправляется на тот же сервер 443, пройдет прокси-сервера и ответ придет напрямую с сервера назначения. Таким образом, мы сравниваем RTT80 с RTT443. Мы предполагаем, что веб-прокси находится где-то на пути между клиентом и web-сервером, и поэтому если в сети существует веб-прокси, то RTT80 должна быть не менее RTT443. В противном случае, измеренные на этих двух портах РТТ должны быть почти идентичны.
Так как задержка сотовой сети может значительно меняться с течением времени из-за условий канала и скопления, важно использовать несколько образцов. Однако существует компромисс между увеличением количества образцов и минимизации трафика, потребляемого нашими тестами для пользователей, работающих нашими экспериментами. Чтобы исследовать этот вопрос, мы исследовали влияние ряда тестов на точность системы. При изменении количества тестов от 2 до 10 мы обнаружили, что 4 датчика были лучшими номерами для точного определения прокси даже в присутствии шума при минимальном количестве испытаний.
Чтобы понять влияние прокси на популярные направления в Интернете, мы выбрали веб-сайты из топ 100 мировых сайтов Алексы [1]. Однако, есть две проблемы при выборе сайтов использования для определения прокси. Во-первых, для достижения хорошего качества обслуживания интернет-пользователей, многие сервера назначения уже размещены вблизи (или внутри) мобильных сетей, то прокси и назначения пути сервера практически идентичны. Используя только такие сайты, в наших измерениях может привести к ложноотрицательных результатов, поскольку RTT80 будет похож на RTT443 (мы рассмотрим это на рис. 2).
Во-вторых,шум в сотовой сети из-за перегрузки, сила сигнала и другие факторы могут повлиять на наши выводы, вызывая задержки существенно различающихся по тестам. Чтобы достоверно определить прокси-поведение, таким образом, нам нужно выбрать направления, которые являются относительно «далекими» от клиента, гораздо больше, чем любое отклонение в показателях из-за сети.
С учетом этого шума, мы предлагаем следующий динамический подход, который корректирует разницу в любой системе измерения. Сначала мы измеряем RTT 443 за 100 ведущих веб-сайтов сразу. Затем мы используем стандартное отклонение (SD) по измерениям РТТ, ииспользуем 2*SD как порог для исключения направлений, которые находятся «слишком близко» к сети для использования прокси-вывода. В частности для каждого места назначения мы сравниваем RTT443 с 2*SD, и смотрим, если первое больше, чем второе, мы удаляем сайты, чьи RTT443 меньше, чем 2* SD.
При проверке прокси-сервера, наш клиент устанавливает TCP-сокеты с целевым веб-сервером на порт 80 и порт 443. Мы используем 4 датчика для каждого теста, т. е. для каждого назначения мы собираем четыре пары RTT80 и RTT443. Для каждой пары мы вычисляем разницу между RTT443 и RTT80. После этого мы вычисляем стандартное отклонение (SD) из этих четырех значений разницы. Для каждого сайта сравниваем разницу и SD. Если значение разности больше нуля и больше чем SD, мы предполагаем что этот веб-прокси в сети. Мы утвердили этот подход для всех перевозчиков Соединенных Штатов в нашем исследовании, используя тесты на контролируемом сервере в Amazon EC2 в Вирджинии. Мы обнаружили, что наш метод вывода дало идентичные результаты.
Кэширование. Для обнаружения кэширования на веб-прокси, мы предполагаем, что время выборки для содержимого из кэша меньше, чем от начального сервера, исходя из предположения, что кэш ближе к клиенту с точки зрения времени ожидания. Таким образом, мы используем латентную методологию для того, чтобы сделать вывод о том, есть ли кэширование прокси в сети, для определения кэширования на основе различий в разное время, при повторном извлечении кэшированного содержания.
Конкретно, мы посылаем два последовательных HTTP GET, чтобы получить такой же (кэшированный) объект дважды. Предполагая пустой кэш в начале эксперимента, и что веб-прокси кэширует извлеченный контент, извлеченный объект будет кэшироваться после первой HTTP GET. В этом случае второй HTTP GET будет обслуживаться из кэша. Затем мы вычисляем разницу во времени загрузки для двух GetS (first80 и second80) и делаем вывод, что объект был кэширован, если first80 статистически больше, чем second80.
Поскольку данный объект может быть кэширован в предыдущей выборке, мы используем несколько источников контента (некоторые из которых не следует сохранять в кэше) и убеждаемся, что наши эксперименты оставляют достаточное время между парами GETs, чтобы гарантировать, что любое кэшированное содержимое истекает [2]. Мы проверили этот подход с нашим управляемым сервером, подтвердили, что каждая из записей истечет. Для двух носителей, развернутых в Веб кэширований (Sprint и Boost), мы обнаружили, что записи кэша истекают через 5 минут.
Мы динамически определили, какие объекты выбрать для тестирования, чтобы кэшировать с помощью загрузки индексной страницы для популярных веб-сайтов и извлечения URL-адресов для встроенных объектов. Мы обнаружили, что Веб-кэширование не кэширует все типы файлов. Чтобы исследовать это поведение, мы включаем CSS, JavaScript, JPG, PNG, GIF и HTML файлы в нашем эксперименте, потому что они обычно встроены в веб-страницы.
Похожий сценарий у обнаружения прокси, мы не можем обнаружить поведение кэширования прокси-сервера, если кэш и начальный сервер относительно близко друг к другу и размеры файлов невелики. Таким образом, мы повторно использовали «далекие» сайты, которые мы включаем в прокси выявляющего эксперимента для извлечения URL, и мы исключаем мелкие объекты (менее 5 КБ).
Объект перезаписи. Для обнаружения объекта перезаписи, мы рассчитываем на то, что веб-прокси не может модифицировать HTTPS трафик не нарушая шифрования, но может свободно сделать это с HTTP трафиком. Таким образом мы сравнили результаты выборки похожего Web объекта через HTTPS и HTTP для определения изменения содержания на незашифрованном трафике [4].
Мы используем аналогичный подход к методологии кэш-обнаружения для идентификации объектов для извлечения, используя встроенные объекты на популярных веб-сайтах и обеспечения того, чтобы серверы хостинга поддерживали контент как HTTP и HTTPS. Мы выбрали каждый объект через HTTP (порт 80) и HTTPS (порт 443), и сравнили содержимое извлеченных объектов для идентификации перезаписи.
Это, конечно, возможно, что веб-контент извлекающийся из порта 80 и 443 не идентичен, и, эти различия в содержании не обязательны для перезаписи. Чтобы исключить ложную тревогу, мы используем сервер, мы контролируем проверку различия веб-контента при извлечении с помощью HTTP и HTTPS, основываясь на предположении, что такое поведение не будет меняться в зависимости от местоположения клиента. Если содержание одинаково по обоим протоколам для нашего сервера управления, но они разные при получении через сотовую сеть, мы приходим к выводу о том, что веб-прокси перезаписывает содержимое HTTP.
We include CSS, JavaScript, PNG, GIF, JPG, and HTML files in the experiment to
explore what file types are rewritten and how. Our approach allows us to detect behav-
iors such as transcoding, compression, header modification, and content injection.
Мы включаем CSS, JavaScript, PNG, GIF, JPG, HTML файлы в эксперимент, чтобы исследовать какие типы файлов были переписаны и каким образом. Наш подход позволяет нам обнаружить поведения, такие как транскодирование, сжатие заголовка, видоизменение и инъекции содержимого.
Перенаправление. Xu и др. [3] показали, что некоторые веб-прокси игнорируют IP-адрес, предоставляющий HTTP GET запросы, и вместо этого, чтобы выполнить новый поиск DNS для определения назначения IP основывается на разрешении доменных имен в хосте: поле в HTTP GET заголовка запроса. В этом случае HTTP поток может быть отправлен на другой сервер, не обусловленный клиентом. Чтобы обнаружить такое поведение перенаправления, мы были не в состоянии эффективно использовать латентные методы, поэтому мы используем два сервера под нашим контролем, E1 и E2, каждый из которых имеет другой IP-адрес. Мы изменили содержимое заголовка HTTP GET, помещая имя домена E1 в хост: поля и отправив запрос GET на E2 (при условии, что IP-адрес E2 в заголовке IP).
Мы делаем это как для E1 и E2, и проверяем, какой сервер получает запрос HTTP [5]. Если E1 получает запрос GET, это указывает на то, что прокси-сервер Web перенаправил запрос GET Е2 путем разрешения доменного имени E1 в IP-адрес E1. В противном случае, прокси-сервер не делает перенаправление.
Литература:
- Alexa top 100 websites. http://www.alexa.com/topsites.
- G. Detal, B. Hesmans, O. Bonaventure, Y. Vanaubel, and B. Donnet. Revealing middlebox interference with tracebox. In Proc. of IMC. ACM, 2013.
- V. Farkas, B. H´eder, and S. Nov´aczki. A Split Connection TCP Proxy in LTE Networks. In Inf. Comm. Tech., 2012.
- C.Kreibich,N.Weaver,B.Nechaev,andV.Paxson. Netalyzr:Illuminatingtheedgenetwork. In Proc. of IMC, 2010.
- A.Nikravesh,H.Yao,S.Xu,D.Choffnes,andZ. M. Mao. Mobilyzer:Anopenplatformfor controllable mobile network measurements. In Proc. of MobiSys. ACM, 2015.

