В статье рассмотрены подходы к реализации систем управления базами данных на многопроцессорных машинах различных архитектур. Предложен вариант реализации архитектуры сервера баз данных отвечающий современным требованиям к масштабируемости и отказоустойчивости, а также готовности данных.
Ключевые слова: базы данных, многопроцессорные системы, параллельная обработка информации, масштабируемость вычислительной системы, отказоустойчивость.
В начале 21 века Россия эволюционно перешло из индустриальной стадии развития в постиндустриальную. На предыдущем этапе развития приоритетными экономическими благами являлись материальные ресурсы и труд человека, то теперь главными факторами устойчивого развития государства стали передовые технологии и постоянный доступ к актуальной информации. В современном информационном обществе большинство профессий связано с созданием, обработкой и передачей информации, при этом каждый индивид имеет возможность получить доступ к интересующей его услуге или информации по продукту в удобное время практически вне зависимости от его географического местоположения. Развитие компьютеров привело к тому, что большая комплексная машина стала необходимой в каждом доме и офисе. [6]
Основным местом хранения и средством обработки информации, несмотря на появление огромного количества устройств для потребления цифрового контента, как и раньше являются персональные компьютеры, или производные от них аппаратные комплексы (ПК). Важной особенностью, возникающей при переходе к информационному обществу, является резкий рост объемов цифрового контента, который используется и хранится в ПК. Для достижения возможности эффективной работы с большими объемами упорядоченной информации в ПК применяются технологии, основанные на использовании баз данных (БД) в их различных вариациях. Вычислительный комплекс (ВК), в который входит аппаратная составляющая, работающая под управлением системы управления базами данных (СУБД), является машиной баз данных (МБД).
Впервые МБД начали появляться в 60-е годы прошлого столетия. Сегодня рынок программного обеспечения (ПО) представлен огромным количеством разнообразных коммерческих СУБД почти для всех аппаратно-программных вариаций. До начала 2000-х годов большинство МБД использовали однопроцессорную архитектуру. С ростом требований к программно-аппаратной составляющей современной информационной системы, появился спектр задач, связанных с хранением, передачей и дальнейшей обработкой очень больших объемов упорядоченной информации. Вполне обоснованным и рациональным решением задачи обработки очень больших БД является применение при проектировании МБД многопроцессорных ПК, которые позволяют выполнять параллельную обработку информации.
Примерами успешных с технической и коммерческой точки зрения решений создания параллельных СУБД могут служить: DB2 ParallelEdition, NonStopSQL и NCR Teradata. Такие системы позволяют объединить до тысячи CPU и такое же число устройств хранения и могут обслуживать БД объёмом в несколько десятков терабайт. Несмотря на параллельно идущую эволюцию аппаратных составляющих и ПО попрежнему существует открытый перечень проблем, требующих вспомогательных исследований и разработок. Примером может являться продолжающаяся эволюция аппаратной архитектуры параллельных машин. В Асиломарском отчете о направлениях исследований в области БД [2], указывается, что достаточно скоро крупные корпорации будут использовать в своей деятельности БД занимающие петабайты дискового пространства. Для оперирования такими объемом данных необходимы параллельные машины с количеством CPU значительно превышающим их количество в существующих ВК. Вместе с тем, традиционные архитектуры параллельных МБД не предоставляют возможности простого увеличения на несколько порядков величины своих аппаратных ресурсов.
Фундаментом современной технологии СУБД является реляционная модель, которую предложил в 1969 г. Е. Ф. Кодд [4]. Впервые коммерческие реляционные БД, как разновидность инструментального ПО возникла в 1983 г., а сегодня она заслуженно занимает лидирующее положение по количеству использования в проектах разного характера и величины, а также определённую нишу на рынке.
Аргументы и результаты реляционных операций — это отношения. Запросы на выполнение определённых операций по отношению к данным в реляционных БД создаются по средствам конструкций, написанных на специально созданном для этих целей на языке SQL [9].
При условии, что исходное отношение достаточно велико, для исполнения операции выборки требуются существенные затраты машинного времени. Чтобы ускорить данный процесс, возможно организовать параллельное исполнение запроса с одновременным задействованием нескольких CPU, которые входят в состав многопроцессорного ВК. Реляционная модель организации БД идеально подходит для «распараллеливания» запросов. В упрощённом виде такой процесс можно представить следующим образом: каждое отношение делится на фрагменты, располагающиеся на обособленных HDD или SSD. При формировании запроса, он применяется к этим фрагментам, а не к целому отношению. Обработка каждого из них происходит на отдельном CPU. Результаты обработки, полученные на обособленных CPU, в конце операции объединяются в общее итоговое отношение. Поэтому, разделяя отношение на n фрагментов в параллельной МБД с n CPU, сокращается время исполнения запроса в n раз.
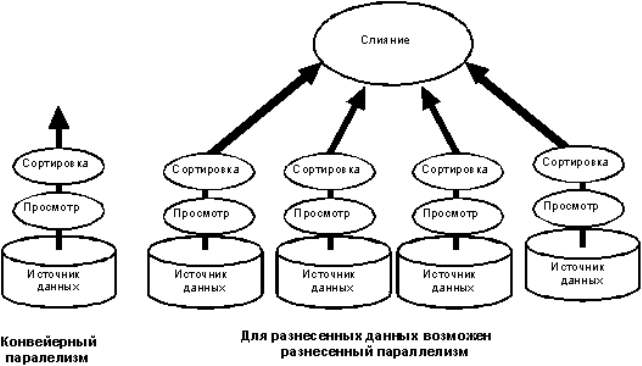
Рис. 1 Возможные подходы к организации БД
При использовании данного подхода наряду с неоспоримыми преимуществами существует и ряд проблемных вопросов и противоречий. Первая проблема — выбор критерия, в соответствии с которым следует делить отношения в реляционной БД на фрагменты. Обычно применяется упорядоченное разделение, которое использует первые два символа из первого поля как критерий распределения кортежей по локальным или сетевым дискам. Такой метод разделения не считается эталонным, так как в итоге возможно получатся фрагменты, которые значительно различаются по размерам, что как правило, приводит к существенным нарушениям баланса в загрузке CPU, а это снижает производительность многопроцессорного вычислительного комплекса до уровня ВК с одним CPU.
Существует различные способы разделения отношения на фрагменты в параллельной МБД, но все они не гарантируют сбалансированной загрузки всех CPU во всех вероятных случаях. Поэтому, для повышения эффективности «распараллеливания» запросов в параллельной МДБ необходимо применяясь специальный механизм, реализующий балансировку нагрузки между всеми CPU при исполнении запроса в режиме реального времени.
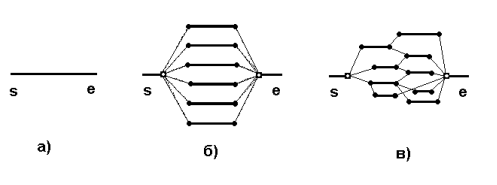
Рис 2. Графики исполнения процессов в случаях а) последовательного вычисления, б) близкого к идеальному распараллеливания, в) в общем случае распараллеливания
Ещё одна проблема, связанная с возможностью широкого внедрения в продаже и повсеместного использования параллельных МБД появляется из-за их ограниченной масштабируемости. В составе многопроцессорного ВК CPU делят между собой существующие ресурсы такие как: HDD, RAM, пропускную способность соединительной сети, объединяющую их. Внедрение в существующую систему нового CPU ведёт к снижению производительности и эффективности работы уже существующих, которые используют те же самые аппаратные ресурсы.
Само количество используемых в параллельной системе CPU и дисков является третьей серьёзной проблемой, которая выражается в обеспечение отказоустойчивости самого ВК. Вероятность отказа HDD или SSD в однопроцессорном ВК достаточно мала. Параллельная же система может включать в себя несколько тысяч CPU и HDD — поэтому вероятность отказа увеличивается в несколько раз. Четвертой проблемой является обеспечение высокой готовности данных. Параллельная система должна восстанавливать утраченные данные так, чтобы сделать по максимуму незаметными данные процессы для конечного пользователя, который делает запросы к БД. При условии, что 80–90 % машинного времени тратится только на восстановление БД, использование системы является неприемлемым для предоставления выборки в режиме реального времени.
На современном этапе развития аппаратных и программных компонентов, решение указанных проблем во многом зависит от правильно выбранной архитектуры параллельной МБД.
В 1986 г. М. Стоунбрейкер [10] предложил обобщённую классификацию возможных архитектур параллельных МБД и разделил их на три класса:
архитектуры с разделяемой памятью и дисками,
архитектуры с разделяемыми дисками,
архитектуры без совместного использования ресурсов.
Система с разделяемой памятью и дисками SE (Shared-Everything) включает обособленные CPU, соединяющиеся при помощи общей шины с разделяемой памятью и дисками. При прочих равных условиях SE-системы показывают более высокую производительность и эффективность работы для малых конфигураций. При казалось бы неоспоримых преимуществах, SE-архитектура имеет некоторые недостатки, такие как: ограниченная масштабируемость и низкая аппаратная отказоустойчивость [8].
В параллельных системах с разделяемыми дисками SD (Shared-Disk) каждый у каждого CPU есть своя собственную память. SD-архитектура показывает по сравнению с SE лучшую масштабируемость и большую отказоустойчивость. Но, при реализации SD-систем возникает несколько серьезных проблем, не имеющие эффективного решения.
Рис. 3. Варианты топологий связи процессоров в многопроцессорных вычислительных системах
В системах без совместного использования ресурсов SN (Shared-Nothing) каждый CPU имеет собственную память и HDD или SSD. CPU соединяются между собой с помощью высокоскоростной соединительной сети. SN-архитектура обладает лучшими показателями по масштабируемости и отказоустойчивости, но самый существенный ее недостаток — сложность обеспечения сбалансированной загрузки входящих в неё процессоров. Возникающие в процессе функционирования перекосы в распределении данных между CPU вызывают резкое снижение показателей её производительности.
С целью эффективного преодоления проблем, с которыми сталкиваются разработчики при проектировании SE и SN-архитектур, А. Бхайд в 1988 г. предложил анализировать гибридные архитектуры [11], в которых SE-кластеры объединяются в единую SN-систему. SE-кластер представляет собой фактически самостоятельный мультипроцессор с разделяемыми RAM и HDD. В рамках системы SE-кластеры соединены друг с другом высокоскоростной соединительной сетью. Исходя из этого архитектура CE (Clustered-Everything) обладает хорошими возможностями масштабирования, как SN и возможностями балансировки загрузки, как SE.
В последнее время в мире, в том числе в России наблюдается активное применение вычислительных кластеров — локальных сетей, узлов рабочих станций или персональных компьютеров, намеренно составленных из нескольких вычислительных систем. [7]
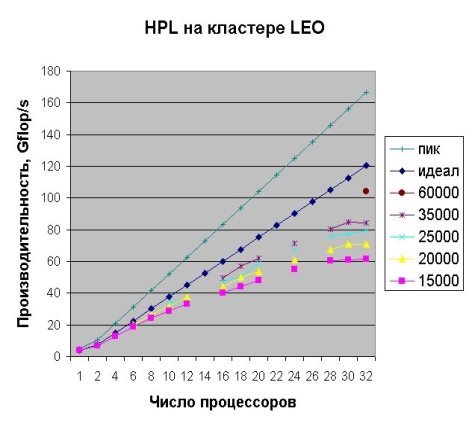
Рис. 4. График, иллюстрирующий изменение производительность в зависимости от количества CPU на кластере Xenon под тестом HPL (по данным http://parallel.ru/cluster/leo_linpack.html)
Причины существенных недостатков CE-архитектуры — вероятные трудности обеспечения готовности данных при отказе аппаратной части вычислительного комплекса на уровне SE-кластера. C целью предупреждения потери данных из-за отказов нужно дублировать их на разных SE-кластерах. Поддержка идентичности различных копий неизбежно ведёт к существенному увеличению трафика передаваемого по соединительной сети. Подобное явление значительно снижает общую производительность параллельной системы в режиме нормального функционирования и приводит к тому, что SE-кластеры начинают работать с производительностью, характерной для однопроцессорных ВК.
С целью минимизации действия существующих недостатков аппаратных архитектур, необходимо использовать альтернативную трехуровневую иерархическую архитектуру. В её основе лежит понятие SD2-кластера CD2 (Clustered-Diskwith 2-processormodules). Этот кластер состоит из несимметричных двухпроцессорных модулей PM с разделяемой RAM и набора HDD, которые объединены по схеме SD.
Учитывая вышесказанное можно отметить следующее: параллельные МБД с одноуровневой архитектурой на современном этапе эволюции вычислительных систем уже исчерпали все возможности дальнейшего эффективного масштабирования. Их сменяют принципиально новые системы с иерархической архитектурой, которые включают в себя на два порядка больше CPU и HDD или SSD.
На современном этапе развито вычислительной техники существуют все предпосылки для того, чтобы дальнейшее развитие иерархических архитектур параллельных МБД пошло по пути создания многоуровневых гибридных схем, способных обеспечить высокую готовность данных на конфигурациях с несколькими сотнями тысяч CPU.
Грамотно интегрированная в процесс управления информационная система является одним из важных факторов успешной реализации стратегических бизнес-целей организации. [5]
Также актуальной проблемой остаётся существенный недостаток аппаратных средств для параллельных вычислении в учебных и научных учреждениях, что не позволяет обеспечить всестороннего изучения данных технологий. Но начиная с недавнего времени появляются технологии, которые позволяют использовать практику параллельных вычислении в большинство учебных и производственных лаборатории. [1]
Литература:
- Бакенов В. М. Многомашинные комплексы и многопроцессорные системы / Москва: Московский Государственный университет приборостроения и информатики, 2014. — 127 с;
- Бернштейн Ф. и др. / Открытые системы. — 1999. — № 1. — C. 61–68;
- Воеводин В. В., Воеводин Вл.В. Параллельные вычисления. — СПб.: БХВ- Петербург, 2011. — 608 c;
- Кодд Е. Ф. / СУБД. — 1995. — № 1. — C. 145–169;
- Поначугин А. В. Администрирование в информационных системах и компьютерных сетях (учебное пособие) / Н. Новгород: Мининский университет, 2016. — 82 с;
- Поначугин А. В. Использование суперкомпьютеров для решения задач моделирования / Фундаментальные и прикладные исследования в современном мире. — 2015. — № 10–1. — С. 22–25;
- Поначугин А. В. Кластерные суперкомпьютеры и их применение в решении наукоёмких задач / Информационные технологии в организации единого образовательного пространства: сборник статей по материалам конференции. кафедра Прикладной математики и информатики. — Нижний Новгород, 2014. С. 84–90;
- Соколинский Л. Б. Параллельные машины баз данных / Природа. — 2001. — № 8 [Электронный ресурс] — Режим доступа: http://vivovoco.astronet.ru/VV/JOURNAL/NATURE/08_01/PARBASE.HTM;
- Чамберлин Д. Д. и др. // СУБД. — 1996. — № 1. — C. 144–159;
- Stonebraker M. // Database Engineering Bulletin. — March 1986. — V.9. — № 1. — P. 4–9;
- Bhide A. An Analysis of Three Transaction Processing Architectures // Proceedings of 14-th Internat. Conf. on Very Large Data Bases (VLDB'88), 29 August — 1 September 1988, Los Angeles, California, USA, 1988. — P. 339–350.

