




A Decision Forest Approach to Cold-start Recommendation

Автор: Шеньшень Вань
Рубрика: Автоматика и вычислительная техника
Опубликовано в Техника. Технологии. Инженерия №1 (1) июнь 2016 г.
Дата публикации: 12.04.2016
Статья просмотрена: 73 раза
Библиографическое описание:
Шеньшень, Вань. A Decision Forest Approach to Cold-start Recommendation / Вань Шеньшень. — Текст : непосредственный // Техника. Технологии. Инженерия. — 2016. — № 1 (1). — С. 24-30. — URL: https://moluch.ru/th/8/archive/36/870/ (дата обращения: 26.04.2024).
Шеньшень Вань
Юго-западный нефтяной университет (Китай)
Recommender systems have become extremely common in recent years, and are applied in a variety of areas. Model-based methods play an important role in the recommendation. Model-based recommendation systems build a model based on the dataset of ratings. Existing model-based recommenders consider either demographics or content information. However, it is used to recommend for new user or new item. In this paper, we propose a decision forest approach to address the well-known cold-start problem. Our approach makes use of decision forest to constructing a model comprises users' information, items' information and rating to recommendation for users and items simultaneously. This approach can be used to solve double cold-start problem (new user and new item). First, we integrate dataset comprising both users' information, items' information and rating. Dicision system will be got through data conversion and data discretization based on the dataset. Second, a decision forest is generated with n decision trees based on the decision system. Third, we describe how the approach to generates cold-start recommendations. Fourth, a pruning method is proposed for decision forest. Experimental results on the well-known MovieLens dataset show that the pruning decision forest approach performs stably and the constructed trees are understandable.
Keywords: Recommender System, Decision Forest, Cold-start.
Recommender Systems (RSs) [1, 2, 3] have attracted extensive attention in the academic and business [4, 5, 6]. Model-based RSs play an important role in the recommendation. Model-based RSs involve building a model based on the dataset of ratings. In other words, we extract some information from the dataset, and user that as a «model» to make recommendations without having to use the complete dataset every time [7]. Existing model-based recommenders consider either demographic or item information. It is appropriate to either existing item or known user. Moreover, it can be used to recommend for new user or new item.
Cold-start recommendation [8, 9] is a challenging problem in RSs. There are generally two types of cold-start recommendation. One is the new user recommendation, the other is the new item recommendation. Model-based RSs can solve cold-start problem, it involves the demographics or item information to construct a model. Therefore, it is appropriate to either existing item or known user.
A random forest approach to model-based recommendation is proposed in [10]. This approach builds two models, demographic-based model (DM) and content-based model (CM). DM is used to recommend for known user or new user and CM is used to recommend for existing item or new item. The approach builds two models to address the cold-start problem.
In this paper, we propose a decision forest approach to address the well-known cold-start problem. Our approach makes use of decision forest to constructing a model which comprises users' information, items' information and rating to recommendation for users and items simultaneously. This approach can be used to solve double cold-start problem (new user and new item). First, we integrate dataset comprising both users' information, items' information and rating. Dicision system will be got through data conversion and data discretization based on the dataset. Second, a decision forest is generated with n decision trees based on the decision system. Third, we describe how the approach to generates cold-start recommendations. Fourth, we propose a pruning method for decision forest. Experimental results on the well-known MovieLens dataset show that the pruning decision forest approach performs stably and the constructed trees are understandable.
The major advantages of the proposed approach is four-folds. First, we get a decision system. It contains user demographic information, item information and rating information. Second, this approach is valid to new user and new item. Therefore the new approach can be employed to double cold-start recommendation. Third, we propose a pruning technology of decision forest. Fourth, since the new approach is based on the decision system which contains user demographic and item information, it is less sensible to sparse data than model-based recommendation.
Experimental results on the well-known MovieLens dataset show that the pruning decision forest approach performs stably and the constructed trees are understandable.
Data Conversion
In this section, we review MovieLens [11].The Table 1 shows the original data structure of the MovieLens dataset. It has three tables: user, movie and rates. There are three attributes in the Table 1 (a):age, gender and occupation. Many attributes are in the Table 1 (b), which can be classifed into two kinds of attributes, years and genre. Table 1 (c) shows the ratings of users for movies.
The upper part of Figure 1 shows the Table 1. The middle part of Figure 1 depicts the process of building a decision system. The decision system is User information and Movie information linking through Rates. There are three steps: 1) A value is selected from Rates table as the last column in decision system, and the value is a rating of a user for a movie. The user information is selected from User table, which is inserted into the row in front. Then the Movie information is selected from Movie table, and it is appended to the middle of the row. If the User has n users and Movie has m movies, the decision system contains n*m rows. 2) The zero ratings is removed. The rating is a scale of 0 to 5. Users rate movies on a scale of 1 to 5, and 0 means no score. The zero ratings are meaningless for prediction, so remove the zero ratings from the decision system. 3) The UID and MID are removed. The decision system is general patten. It should contain common attributes, so delete the UID and MID. The lower part of Figure 1 represents the converted data.
Table 1
The original data structrue of MovieLens
(a) User
|
User-id |
Age |
Gender |
Occupation |
|
1 |
24 |
M |
Technician |
|
2 |
53 |
F |
Other |
|
3 |
23 |
M |
Writer |
|
… |
|||
|
943 |
22 |
M |
student |
(b) Movie
|
Movie-id |
Release-decade |
Action |
Adventure |
Animation |
Western |
|
1 |
1995s |
0 |
0 |
1 |
0 |
|
2 |
1995s |
1 |
1 |
0 |
0 |
|
3 |
1995s |
0 |
0 |
0 |
0 |
|
… |
|||||
|
1682 |
1991s |
0 |
0 |
0 |
0 |
(c) Rates
|
User-id\Movie-id |
1 |
2 |
3 |
4 |
5 |
1682 |
|
1 |
0 |
1 |
0 |
1 |
0 |
0 |
|
2 |
1 |
0 |
0 |
1 |
0 |
0 |
|
3 |
0 |
0 |
0 |
0 |
1 |
0 |
|
… |
||||||
|
1682 |
0 |
0 |
1 |
1 |
0 |
0 |
Data Discretization
A manual discretization setting is given to discretize numeric data [12]. Given intervals [0, 18), [18, 25), [25, 30), [30, 35), [35, 45), [45, 56), [56,1), the age of the user is discretized by the GroupLens project. In this paper, Age 17, 18, 25, 35, 45, 50, 56 express interval [0, 18), [18, 25), [25, 30), [30, 35), [35, 45), [45, 56), [56,1), respectively, as shown in Figure 2 (a).
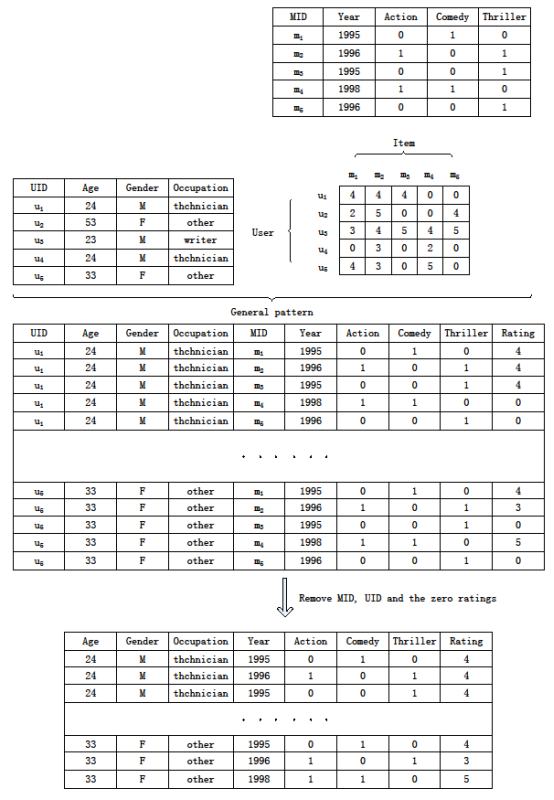
Fig. 1. Data Conversion
We use release decade instead of release date for the movies range from 1920s to 1990s, as shown in Figure 2 (b).
The values of Rating are 1 to 5, because the 0 is removed. Given intervals [1,3], [4,5], 1 indicates the scale of 1 to 3, while 5 indicates the scale of 4 to 5, as show in Figure 2 (c).
We will get the decision system through discretizing the data of lower part of Figure 1.
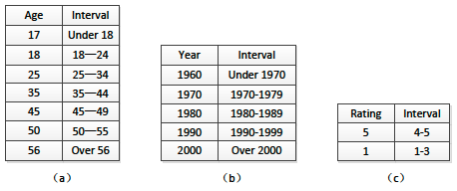
Fig. 2. Attribute discretization: (a) Age discretization, (b) Year discretization, (c) Rating discretization
Construct the Decision Forest
Decision Forest
Generate a decision forest [13] with n random decision trees [14, 15, 16]. Random decision trees are built based on training set in two steps: 1) an attribute is randomly selected from the training set for the root node, then other nodes are constructed based on random decision tree's algorithm; 2) the leaves are assigned discrete scores which indicate the prediction value. There are two classes of rating in training set, 1 means dislike and 5 means favorite. The leaves of random tree stored the prediction value is 1 or 5. When the two conicting results are suggested in different decision trees, the way of voting is used for recommendation.
Pruning
Pruning of decision tree [17, 18] is useful in improving the generalization performance of decision trees [19]. Pre-pruning and post-pruning are two standard methods for pruning a decision tree [19].
In this paper, we propose a pruning technology. It is discribed as follows. There are many genres of movie in the dataset, for example Action, Adventure, Animation, Children and Comedy etc. They are movies' attributes on the MovieLens dataset. As shown in Table 1, the value 1 means the movie is this genre, and the value 0 means not. If the value is 0, it expresses many case. For example, the value of comedy is 0, which means the movie may be Action, or Adventure, or Musical, or War etc. Many possibilities are existing. The nondeterminacy is little significance for recommend. So, we prune the branch of the value 0.
Figure 3(a) represents a decision tree. The pruning decision tree is showed as Figure 3(b). In this paper, the pruning decision forest is applied in recommendation.
Predicting approaches
For new user, we can classify him/her according to the characteristics attributes. First, the characteristics attributes are matched in a decision tree. Then according to the leaf nodes of the matched branch, recommend or not can be decided. Such as, let a new user be a male writer at the age between 18 and 24. According to Figure 3(b), first he mathes the left brance of the root.Then there is only one branch for Action movie.Finally he mathes the rightmost branch according to Occupation.The leaf indicates a rating of 5.Therefore, it shows that he likes Action movies, which will be recommended to him then.
For new item, we can classify it according to its attributes. The process for new item is similar to it for new user. The new user's/item's attributes are matched in every decision tree of the decision forest.
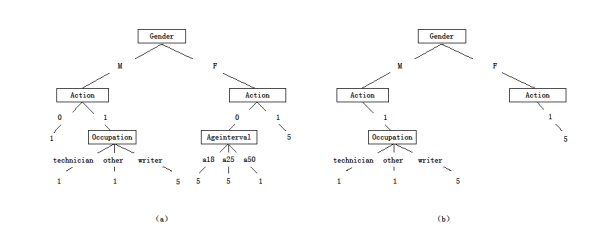
Fig. 3. Decision tree: (a) No pruning decision tree, (b) Pruning decision tree
The predictive result of every decision tree may be difference, 1 or 5, can be the majority is selected. If the quantity of the prediction results for 5 is majority, the result expresses can be recommended. While the prediction results for 1 is majority, the result expresses not recommended. If the number of 1 is the same as that of 5, we will employ 5. That is, we will recommend.
Experimental Result
In this section, we try to answer the following questions through experimentation.
- Which is better between No-pruning Decision Forest and Pruning Decision Forest for predict?
- How large of the size of No-pruning Decision Forest and Pruning Decision Forest when theAccuracy keeps stable?
Dataset
We experiment with one well-known MovieLens [11] dataset which is widely used in recommender systems (see, e.g., [8, 20]). We use the version with 943 users and 1682 movies. The original Rate relation contains the rating of movies with 5 scales. All users have watched at least one movie, and the dataset consists of approximately 100,000 movies ratings.
Results
We select one case for test set in dataset randomly, the remaining n-1 cases for training set. In order to know the size of the forest when the accuracy of pruned decision forest keeps stable, the numbers of random trees defined by us is from 10 to 700.
We undertake 2 sets of experiments to answer the questions raised at the beginning of the section one by one. The first is to test the decision forest approach on the testing set. The second is to test the pruning decision forest approach on the testing set. Each experiment is repeated 100 times with different sampling of training and testing sets, and the average accuracy is computed.
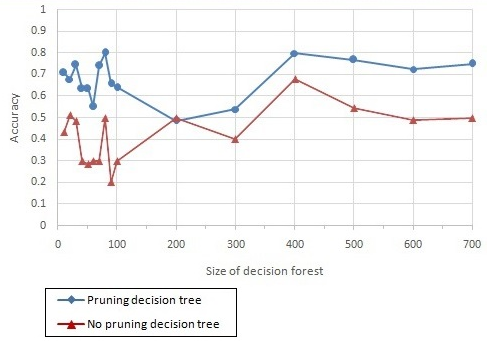
Fig. 4. Accuracy comparision
Figure 4. compares the accuracy of two approaches on the testing set. We observe that the pruning decision forest approach always outperforms the no-pruning decision forest approach. It indicates that the new approach satisfies our requirement well.
The accuracy achieves the maximal value when the pruning decision forest size is 400. Moreover, the accuracy is stable when size of pruning decision forest is 400. In other words, 400 is an appropriate pruning decision forest size. While the accuracy of no-pruning decision forest is stable when the size is 500.
Conclusions
In this paper, we proposed a decision forest approach to cold-start recommendation. It shows that the pruning decision forest approach outperforms decision forest. Experimental results indicate that the pruning decision forest approach performs stably, and the constructed trees are understandable. This approach can be employed to cold-start recommendation.
References:
1. Schafer, J.B., Konstan, J., Riedl, J.: Recommender systems in e-commerce. In: Proceedings ofthe 1st ACM conference on Electronic commerce, ACM (1999) 158–166
2. Resnick, P., Varian, H.R.: Recommender systems. Communications of the ACM 40(3) (1997)56–58
3. Herlocker, J.L., Konstan, J.A., Terveen, L.G., Riedl, J.T.: Evaluating collaborative filteringrecommender systems. ACM Transactions on Information Systems (TOIS) 22(1) (2004) 5–53
4. Bobadilla, J., Ortega, F., Hernando, A., Gutierrez, A.: Recommender systems survey. Knowledge-Based Systems 46 (2013) 109–132
5. Fan Min and William Zhu.: Mining top-k granular association rules for recommendation. IFSA World Congress and NAFIPS Annual Meeting (IFSA/NAFIPS) (2013) 1372–1376
6. He, X., Min, F., Zhu, W.: A comparative study of discretization approaches for granular association rule mining. In: Electrical and Computer Engineering (CCECE), 2013 26th Annual IEEECanadian Conference on, IEEE (2013) 1–5
7. :Model-based recommendation systems. http://www.cs.carleton.edu/cs_comps/0607/recommend/recommender/modelbased.html.
8. Schein, A.I., Popescul, A., Ungar, L.H., Pennock, D.M.: Methods and metrics for cold-startrecommendations. In: Proceedings of the 25th annual international ACM SIGIR conference onResearch and development in information retrieval, ACM (2002) 253–260
9. Min, F., Zhu, W.: Cold-start recommendation through granular association rules. arXiv preprintarXiv:1305.1372 (2013)
10. Heng-ru, Z., Min, F., Shen-shen, W.: A random forest approach to model-based recommendation.Journal of Information and Computational Science. 2014 Vol. 11(15):5341–5348
11. : Internet movie database. http://movielens.umn.edu.
12. He, X., Min, F., Zhu, W.: A comparative study of discretization approaches for granular association rule mining. In: Proceedings of the 2013 Canadian Conference on Electrical and ComputerEngineering. (2013) 725–729
13. Ho, T.K.: Random decision forests. In: Document Analysis and Recognition, 1995., Proceedingsof the Third International Conference on. Volume 1., IEEE (1995) 278–282
14. Magerman, D.M.: Statistical decision-tree models for parsing. In: Proceedings of the 33rd annualmeeting on Association for Computational Linguistics, Association for Computational Linguistics(1995) 276–283
15. Hartmann, C.R., Varshney, P.K., Mehrotra, K.G., Gerberich, C.: Application of informationtheory to the construction of e_cient decision trees. Information Theory, IEEE Transactions on28(4) (1982) 565–577
16. Knuth, D.E.: Optimum binary search trees. Acta informatica 1(1) (1971) 14–25
17. Mingers, J.: An empirical comparison of pruning methods for decision tree induction. Machinelearning 4(2) (1989) 227–243
18. Schmid, H.: Probabilistic part-of-speech tagging using decision trees. In: Proceedings of theinternational conference on new methods in language processing. Volume 12., Manchester, UK(1994) 44–49
19. Dong, M., Kothari, R.: Classi_ability based pruning of decision trees. In: Neural Networks, 2001.Proceedings. IJCNN'01. International Joint Conference on. Volume 3., IEEE (2001) 1739–1743
20. Cremonesi, P., Turrin, R., Airoldi, F.: Hybrid algorithms for recommending new items. In:Proceedings of the 2nd International Workshop on Information Heterogeneity and Fusion in Recommender Systems, ACM (2011) 33–40
