




Представление профилей нормального поведения пользователей с помощью масштабируемых фильтров Блума

Автор: Григоров Андрей Сергеевич
Рубрика: 1. Информатика и кибернетика
Опубликовано в
Дата публикации: 01.04.2014
Статья просмотрена: 435 раз
Библиографическое описание:
Григоров, А. С. Представление профилей нормального поведения пользователей с помощью масштабируемых фильтров Блума / А. С. Григоров. — Текст : непосредственный // Технические науки: проблемы и перспективы : материалы II Междунар. науч. конф. (г. Санкт-Петербург, апрель 2014 г.). — Т. 0. — Санкт-Петербург : Заневская площадь, 2014. — С. 2-5. — URL: https://moluch.ru/conf/tech/archive/89/5458/ (дата обращения: 27.04.2024).
В данной статье представлен метод обнаружения аномалий в действиях пользователей путём оценки результатов выполнения SQL-запросов к базам данных. Даётся описание представления профиля нормального поведения пользователя с помощью использования масштабируемых фильтров Блума.
Ключевые слова: обнаружение аномалий, профиль нормального поведения пользователя, масштабируемые фильтры Блума.
В настоящее время использование систем обнаружения аномалий (СОА) в действиях пользователей является одним из подходов к повышению эффективности защиты информационных систем. Принцип работы подобных СОА заключается в том, что сначала для защищаемой информационной системы формируется описание её нормального поведения, а затем все действия, выполняемые с системой, сравниваются с построенными профилями нормального поведения. Если при сравнении обнаруживается значительное отклонение от профиля, то СОА сигнализирует администратору системы или службе безопасности о возможном нарушении правил работы с информационной системой.
При разработке СОА следует учитывать тот факт, что использование СОА может существенно повлиять на работу информационной системы. Так использование неэффективных алгоритмов анализа поведения и структур данных для хранения профилей нормального поведения может привести к тому, что скорость отклика защищаемой системы уменьшится, или обнаружение аномалий будет происходить с большой задержкой, что обычно неприемлемо. Примером систем, использующихся для управления большими объёмами данных и для которых важна скорость отклика на запросы пользователей, являются системы управления базами данных (СУБД), для которых в последние десятилетие активно воплощаются в жизнь идеи создания СОА. Одним из направлений научных исследований в данной области является создание алгоритмов обнаружения аномалий, использующих в качестве исходных данных для анализа информацию о результатах выполнения SQL‑запросов [6]. В работах [1, 2, 3] была предложена математическая модель описания профилей нормального поведения пользователей базы данных на основе графов (рис. 1), отражающих взаимосвязи между данными, которые выбираются SQL‑запросами, считающимися допустимыми при нормальной работе пользователей СУБД. В данной модели вершинам графа соответствуют записи из таблиц БД. Наличие рёбра между вершинами показывает, что при нормальной работе пользователя появление двух записей, соответствующих этим вершинам, в результате выполнения какого-нибудь SQL‑запроса является допустимым событием.
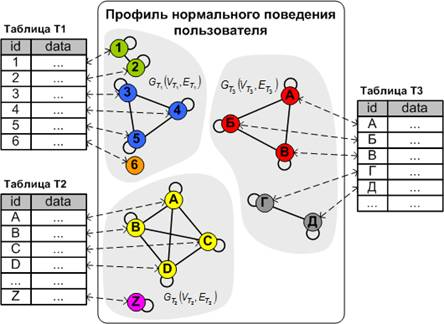
Рис. 1. Пример профиля нормального поведения пользователя
Разработанный метод обнаружения аномалий в SQL-запросах заключается в оценке результата выполнения запроса путём вычисления плотности графа, отражающего взаимосвязи между данными, которые были выбраны запросом. Чем меньше значение плотности графа, тем менее связанными друг с другом являются выбранные данные. Если значение плотности графа оказывается ниже некоторого установленного порога, то это является сигналом о том, что полученный результат не характерен для нормальной работы пользователя.
Плотность графа – это величина, значение которой равно отношению суммы весов всех рёбер графа к максимально возможному весу, который мог бы иметь рассматриваемый граф. Для невзвешенного графа плотность определяется следующей формулой
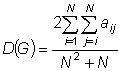 ,
,
где N – количество вершин в графе, а 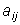 равно 1, если между вершинам i и j существует ребро, и равно 0, если ребра нет.
равно 1, если между вершинам i и j существует ребро, и равно 0, если ребра нет.
С ростом количества записей в таблицах базы данных возникает задача эффективного хранения и манипуляции информацией о графе, описывающем профиль нормального поведения пользователя. Причём для уменьшения временных расходов на работу СОА необходимо, чтобы используемые структуры данных позволяли выполнять обработку в оперативной памяти, так как работа с внешними хранилищами данных (например, жёстким диском) значительно увеличивает время отклика СОА. Основной операцией при вычислении плотности графа, является определение того, существует ли ребро между двумя вершинами графа. Использование для хранения информации о графе матрицы смежности позволяет определить наличие ребра за время пропорциональное 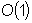 . Однако объём памяти, требующийся для хранения матрицы смежности, пропорционален
. Однако объём памяти, требующийся для хранения матрицы смежности, пропорционален 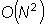 . Альтернативой может быть хранение для каждой вершины списка всех вершин, с ней связанных. Однако в данном случае требуются накладные расходы на хранение названия связанной вершины. Например, если вершины в графе кодируются K-битными ключами, то на хранение списка из M вершин потребуется KM бит информации.
. Альтернативой может быть хранение для каждой вершины списка всех вершин, с ней связанных. Однако в данном случае требуются накладные расходы на хранение названия связанной вершины. Например, если вершины в графе кодируются K-битными ключами, то на хранение списка из M вершин потребуется KM бит информации.
Для уменьшения размеров памяти, необходимой для хранения списка смежных вершин, в данной статье предлагается использовать фильтр Блума [5] – вероятностную структуру данных, позволяющую хранить множество элементов и проверять принадлежность конкретного элемента к данному множеству. Принцип работы фильтра Блума устроен таким образом, что в ответ на вопрос, есть ли данный элемент во множестве, можно получить положительный ответ, хотя на самом деле элемента во множестве нет. Однако если на данный вопрос получен отрицательный ответ, то это означает, что элемент во множестве точно отсутствует.
Фильтр Блума представляет собой массив из m бит, изначально заполненный нулями, и набор k независимых друг от друга хеш-функций h1, h2, …, hk, возвращающих значения от 1 до m. Добавление в фильтр Блума элемента x заключается в записи в ячейки с номерами h1(x), h2(x), …, hk(x) единиц. Для проверки принадлежности элемента x множеству проверяются значения ячеек с номерами h1(x), h2(x), …, hk(x). Если хотя бы в одной ячейке окажется ноль, то это означает, что элемент ранее во множество не добавлялся, так как в этом случае все ячейки были бы заполнены единицами. Если же все ячейки заполнены единицами, то это означает, что элемент, возможно, принадлежит множеству, так как все ячейки могли быть заполнены единицами при добавлении других элементов. Как видно из описания, фильтр Блума не требует хранения самого элемента, что делает размер его массива независимым от размера элементов во множестве.
Размер битового массива, который следует использовать, определяется двумя параметрами: количеством элементов n, которое предполагается добавить во множество, и p – желаемый уровень ложноположительных срабатываний алгоритма. Оптимальный размер может быть вычислен по формуле
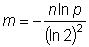 .
.
Так, например, для хранения n-элементного множества при желаемом уровне ложноположительных срабатываний равном 1% потребуется 9,58n бит.
Предлагается каждой вершине в графе поставить в соответствие свой фильтр Блума, в котором будут храниться все смежные вершины. Однако следует учитывать, что для некоторых вершин количество смежных вершин может быть существенно меньше общего числа вершин в графе. Поэтому нецелесообразно для всех вершин размер массива брать равным 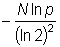 бит, где N – количество вершин в графе. Можно организовать цепочку из нескольких фильтров Блума, которые образуют так называемый масштабируемый фильтр Блума [4]. Изначально делается предположение, что количество смежных вершин будет не более некоторого числа L меньшего, чем N. И вершине ставится в соответствие фильтр Блума размером
бит, где N – количество вершин в графе. Можно организовать цепочку из нескольких фильтров Блума, которые образуют так называемый масштабируемый фильтр Блума [4]. Изначально делается предположение, что количество смежных вершин будет не более некоторого числа L меньшего, чем N. И вершине ставится в соответствие фильтр Блума размером 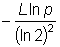 . В дальнейшем при добавлении элементов в фильтр Блума выполняется оценка вероятности ложноположительных срабатываний алгоритма. Если вероятность превышает ожидаемый порог p, то создаётся новый массив того же размера и добавляется в последовательность массивов, связанных с вершиной графа. В дальнейшем добавление новых элементов производится уже в этот массив. Таким образом, при добавлении новых смежных вершин цепочка из фильтров Блума автоматически увеличивается, причём вероятность ложноположительных срабатываний остаётся на желаемом уровне. При определении принадлежности элемента множеству выполняется последовательная проверка во всех фильтрах Блума. Если хотя бы в одном массиве все ячейки, соответствующие значениям хеш-функций, содержат 1, то элемент считается принадлежащим множеству. Если в каждом массиве хотя бы одна ячейка, соответствующая значению хеш-функции, содержит 0, то считается, что элемент не принадлежит множеству.
. В дальнейшем при добавлении элементов в фильтр Блума выполняется оценка вероятности ложноположительных срабатываний алгоритма. Если вероятность превышает ожидаемый порог p, то создаётся новый массив того же размера и добавляется в последовательность массивов, связанных с вершиной графа. В дальнейшем добавление новых элементов производится уже в этот массив. Таким образом, при добавлении новых смежных вершин цепочка из фильтров Блума автоматически увеличивается, причём вероятность ложноположительных срабатываний остаётся на желаемом уровне. При определении принадлежности элемента множеству выполняется последовательная проверка во всех фильтрах Блума. Если хотя бы в одном массиве все ячейки, соответствующие значениям хеш-функций, содержат 1, то элемент считается принадлежащим множеству. Если в каждом массиве хотя бы одна ячейка, соответствующая значению хеш-функции, содержит 0, то считается, что элемент не принадлежит множеству.
На рисунке 2 показан пример представления графа поведения пользователей с помощью масштабируемых фильтров Блума.
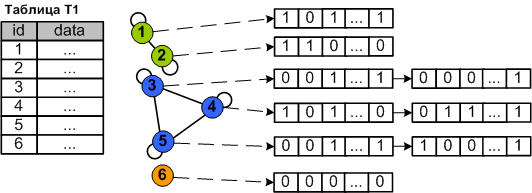
Рис. 2. Представление профиля нормального поведения пользователей с помощью масштабируемых фильтров Блума.
В виду того, что при использовании фильтров Блума возможны ложноположительные срабатывания, вычисленное значение плотности графа в ряде случаев может оказаться больше истинного значения. Однако данную проблему можно обойти, уменьшая пороговое значение плотности графа в зависимости от выбранного желаемого уровня ложноположительных срабатываний фильтра Блума.
Одним из вариантов дальнейшего развития предложенного метода видится определение точных правил корректировки порогового значения плотности графа в зависимости от желаемого уровня ложноположительных срабатываний.
Литература:
1. Беляев А.В., Григоров А.С. Обнаружение атак на базы данных на основе оценки внутренней структуры результатов выполнения SQL-запросов. // Научно-технический вестник Поволжья. №2 2012 г. - Казань: Научно-технический вестник Поволжья, 2012. - С. 99-104.
2. Григоров А.С. Обнаружение аномалий в SQL-запросах к базам данных на основе оценки внутренней структуры результатов выполнения запросов. // Научно-технический вестник Поволжья. №6 2011 г. - Казань: Научно-технический вестник Поволжья, 2011. - С. 146-151.
3. Григоров А.С., Плашенков В.В. Метод обнаружения аномалий в поведении пользователей на основе оценки результатов выполнения SQL-запросов // Вестник компьютерных и информационных технологий. – 2013. – №3 – С. 49-54.
4. Almeida P., Baquero C., Preguica N., Hutchison D. Scalable Bloom Filters // Information Processing Letters 101 (6), 2007 – P. 255–261.
5. Bloom B.H., Space/time trade-offs in hash coding with allowable errors // Commun. ACM 13 (7), 1970 – P. 422-426.
6. Mathew S., Petropoulos M., Hung Q. Ngo, Shambhu Upadhyaya. A Data-Centric Approach to Insider Attack Detection in Database Systems // Recent Advances in Intrusion Detection: 13th International Symposium, RAID, 2010 – P. 382-401.
Ключевые слова
обнаружение аномалий, профиль нормального поведения пользователя, масштабируемые фильтры БлумаПохожие статьи
Один способ генерации графа | Статья в журнале...
Представление профилей нормального поведения пользователей...
Граф G′ = (V′, E′) называется подграфом графа G = (V, E) при условии, что V′ ⊆V, E′ ⊆E. Если множество вершин подграфа G′ есть V′, а...
Обзор методов обнаружения аномалий в SQL-запросах к базам...
Методы обнаружения аномалий, напротив, подразумевают создание шаблонов нормального поведения пользователя и последующее
При работе системы все запросы к БД сначала передаются синтаксическому анализатору для преобразования текста SQL запроса в квиплет.
Моделирование систем защиты информации. Приложение теории...
Ключевые слова: информационная безопасность, системы защиты информации, моделирование, теория графов.
‒ теория нечетких множеств; ‒ теории игр и конфликтов
‒ state enumeration graph — в таких графах вершинам соответствуют тройки (s, d, а), где s...
Использование апостериорного анализа данных для обнаружения...
SQL, запрос, DEMIDS, нормальное поведение, баз данных, метод обнаружения аномалий, DIDAFIT, отрицательный отбор, результат выполнения запроса, какой образ. Экспорт данных о ролевой политике безопасности из Системы...
Анализ моделей и алгоритмов обнаружения компьютерных атак на...
Также различают методики обнаружения аномального поведения и обнаружения злоумышленного поведения пользователей.
Совокупность правил и лингвистических переменных может быть представлена как ориентированный граф, его вершинами являются...
Особенности изучения способа тестирования базового пути...
Узлы (вершины) потокового графа соответствуют линейным участкам программы, включают один
Дана программа, написанная на языке Pascal [4] в системе «Pascal ABC» [5] (рис. 1).
Все независимые пути графа образуют базовое множество. Свойства базового множества
Система поиска сходства шаблонизированных строк
Основная цель любой поисковой системы — поиск информации, удовлетворяющей запросу пользователя.
Слова, для которых величина принимает нулевое значение, не включаются во множество вершин графа.
Редактор языковых баз Wordnet с использованием гиперграфовой...
Использование графов для описания модели предприятия при... UML, модель, баз данных, теория графов, уровень детализации, качество вершин графа, ребро графа, словесное описание, информационная система, привлечение новых клиентов.
Похожие статьи
Один способ генерации графа | Статья в журнале...
Представление профилей нормального поведения пользователей...
Граф G′ = (V′, E′) называется подграфом графа G = (V, E) при условии, что V′ ⊆V, E′ ⊆E. Если множество вершин подграфа G′ есть V′, а...
Обзор методов обнаружения аномалий в SQL-запросах к базам...
Методы обнаружения аномалий, напротив, подразумевают создание шаблонов нормального поведения пользователя и последующее
При работе системы все запросы к БД сначала передаются синтаксическому анализатору для преобразования текста SQL запроса в квиплет.
Моделирование систем защиты информации. Приложение теории...
Ключевые слова: информационная безопасность, системы защиты информации, моделирование, теория графов.
‒ теория нечетких множеств; ‒ теории игр и конфликтов
‒ state enumeration graph — в таких графах вершинам соответствуют тройки (s, d, а), где s...
Использование апостериорного анализа данных для обнаружения...
SQL, запрос, DEMIDS, нормальное поведение, баз данных, метод обнаружения аномалий, DIDAFIT, отрицательный отбор, результат выполнения запроса, какой образ. Экспорт данных о ролевой политике безопасности из Системы...
Анализ моделей и алгоритмов обнаружения компьютерных атак на...
Также различают методики обнаружения аномального поведения и обнаружения злоумышленного поведения пользователей.
Совокупность правил и лингвистических переменных может быть представлена как ориентированный граф, его вершинами являются...
Особенности изучения способа тестирования базового пути...
Узлы (вершины) потокового графа соответствуют линейным участкам программы, включают один
Дана программа, написанная на языке Pascal [4] в системе «Pascal ABC» [5] (рис. 1).
Все независимые пути графа образуют базовое множество. Свойства базового множества
Система поиска сходства шаблонизированных строк
Основная цель любой поисковой системы — поиск информации, удовлетворяющей запросу пользователя.
Слова, для которых величина принимает нулевое значение, не включаются во множество вершин графа.
Редактор языковых баз Wordnet с использованием гиперграфовой...
Использование графов для описания модели предприятия при... UML, модель, баз данных, теория графов, уровень детализации, качество вершин графа, ребро графа, словесное описание, информационная система, привлечение новых клиентов.




