




Метод обнаружения автомобилей на аэрокосмических снимках

Авторы: Симоненко Иван Владимирович, Матвеев Иван Алексеевич
Рубрика: 1. Информатика и кибернетика
Опубликовано в
II международная научная конференция «Технические науки в России и за рубежом» (Москва, ноябрь 2012)
Статья просмотрена: 389 раз
Библиографическое описание:
Симоненко, И. В. Метод обнаружения автомобилей на аэрокосмических снимках / И. В. Симоненко, И. А. Матвеев. — Текст : непосредственный // Технические науки в России и за рубежом : материалы II Междунар. науч. конф. (г. Москва, ноябрь 2012 г.). — Москва : Буки-Веди, 2012. — С. 20-24. — URL: https://moluch.ru/conf/tech/archive/55/3029/ (дата обращения: 20.04.2024).
- Представлен алгоритм обнаружения автомобилей на цветных
изображениях, полученных аэрофотосъёмкой. Подходом к решению
является то, что большинство автомобилей окрашено в один цвет и
имеет сходные размеры. Это позволяет выделять автомобили на фоне как
области с цветовыми характеристиками, отличающимися от фоновых, и
имеющие определённые размер и форму. Области строятся путём
иерархического объединения более мелких на основании сходства
цветовых и пространственных характеристик. Проведено тестирование
алгоритма на наборе изображений, содержащих в общей сложности 2226
автомобилей.
- Введение, постановка задачи. Быстрое развитие средств аэрофотосъёмки (особенно беспилотных летательных аппаратов), позволяющее оперативно получать значительное количество изображений, равно как и развитие вычислительных средств, дающих возможность обрабатывать эту информацию в реальном или близком к реальному масштабе времени, ставит новые интересные задачи. Одна из таких задач - распознавание объектов автомобильного транспорта на изображениях аэрофотосъёмки [1]. Входными данными служат изображения в масштабе 5-10 см/пиксель (так что автомобиль занимает по длине область размером 30-100 пикселей), цветные (3 канала - красный, зелёный, синий), глубина цвета 8 бит. Требуется найти автомобили (их положение, ориентация, размеры) с минимальным количеством ошибок первого и второго рода (пропуск/ложное обнаружение).
- Существующие подходы к решению задачи можно разделить на три основных класса: выделение границ областей на изображении и обнаружение характерных контуров машин (например, [2,3]), использование корреляторов в схеме АдаБуст (например, [4]) и выделение областей с определёнными характеристиками (например, [5,6]). Первые два подхода используются на чёрно-белых изображениях, третий - как правило, на цветных. В представленной работе используется именно третий подход - выделение областей на изображении на основании цветовых характеристик составляющих их точек. В статьях, опирающихся на этот метод, изученных авторами, точки областей интереса (автомобилей) дискриминируются от фона на основании разнообразных эвристик (кластеризация в цветовом пространстве, байесовский подход, работа с последовательностью изображений и др.) после чего из этих точек составляются области. В данной работе используется иерархическое объединение точек в укрупняющиеся области на основании сравнения цветовых и пространственных характеристик этих областей.
- Метод решения. Метод основан на выделении областей с близкими цветовыми характеристиками. Такой подход оправдан тем, что большинство автомобилей имеет однотонную окраску и при этом тон этой окраски, как правило, отличается от фонового (дорога, растительность). Основные стадии работы алгоритма таковы:
- Введение, постановка задачи. Быстрое развитие средств аэрофотосъёмки (особенно беспилотных летательных аппаратов), позволяющее оперативно получать значительное количество изображений, равно как и развитие вычислительных средств, дающих возможность обрабатывать эту информацию в реальном или близком к реальному масштабе времени, ставит новые интересные задачи. Одна из таких задач - распознавание объектов автомобильного транспорта на изображениях аэрофотосъёмки [1]. Входными данными служат изображения в масштабе 5-10 см/пиксель (так что автомобиль занимает по длине область размером 30-100 пикселей), цветные (3 канала - красный, зелёный, синий), глубина цвета 8 бит. Требуется найти автомобили (их положение, ориентация, размеры) с минимальным количеством ошибок первого и второго рода (пропуск/ложное обнаружение).
- выделение тоновых характеристик (исключение влияния затенения на цвет);
- формирование областей одинакового тона;
- выделение однотонных областей гипотетических автомобилей;
- вычисление признаков областей и отбраковка.
- Рассмотрим каждый шаг подробнее.
- Выделение тоновых характеристик. Основное модельное ограничение, эксплуатируемое в данном подходе - однотонность окраски автомобиля. Автомобили, раскрашенные в несколько цветов, составляют весьма малую часть (не более 1%) от общего количества, и погрешность (доля пропущенных автомобилей), создаваемая этим ограничением, представляется приемлемой. Видимый цвет окрашенных участков автомобиля задаётся цветом окраски и затенением (углом падения света на окрашенную поверхность). Бликами пренебрегаем.
- Обозначим три (красную, зелёную и синюю) цветовые компоненты исходных точек как
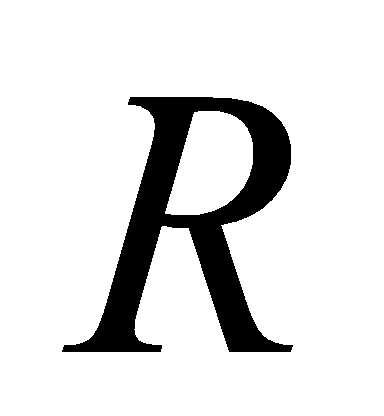 ,
,
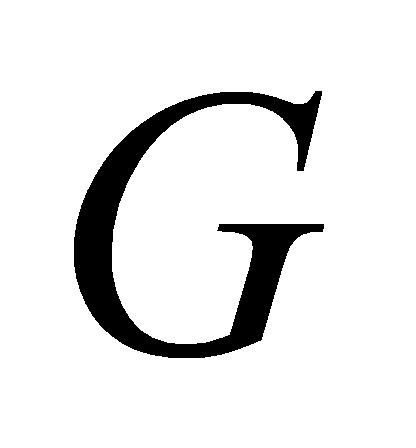 ,
,
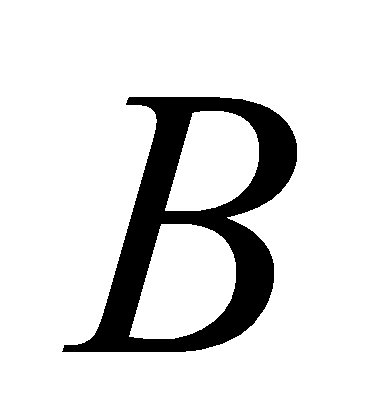 ,
составленный из них вектор цвета
,
составленный из них вектор цвета
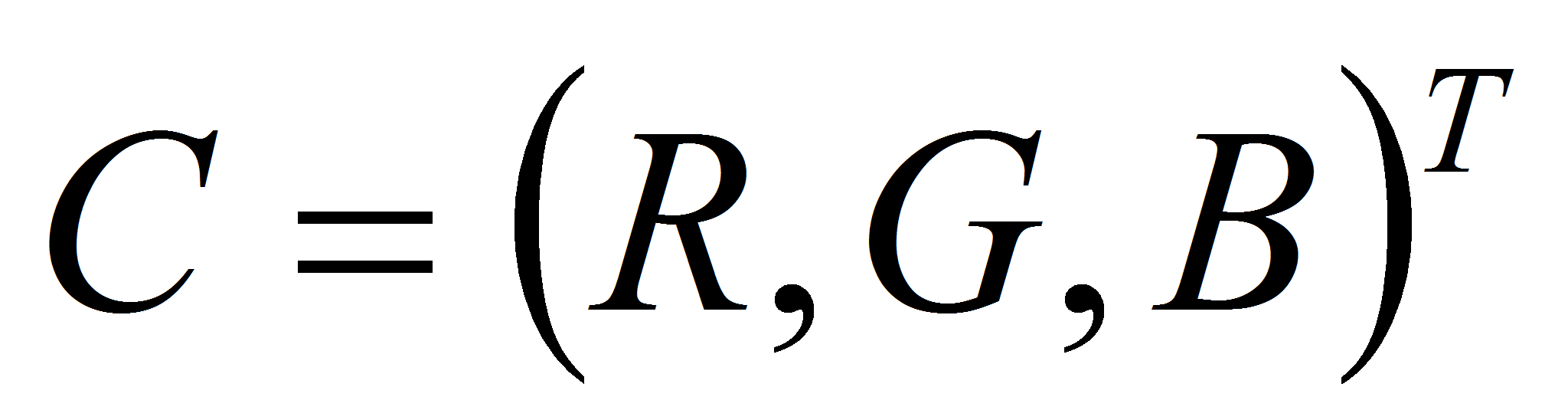 .
Нормализованные компоненты также составляют трёхмерный вектор
.
Нормализованные компоненты также составляют трёхмерный вектор
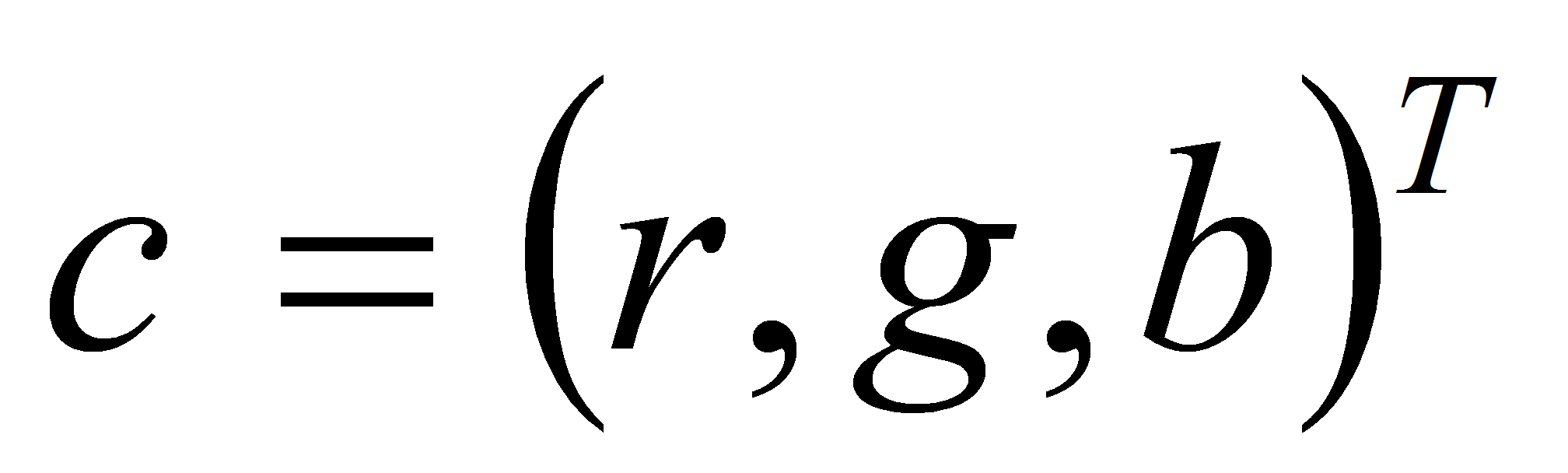 .
Для компенсации затенения, то есть уравнивания цвета одинаково
окрашенных, но по-разному освещённых участков можно использовать
несколько подходов. Из всех вариантов выбрана следующая нормировка:
.
Для компенсации затенения, то есть уравнивания цвета одинаково
окрашенных, но по-разному освещённых участков можно использовать
несколько подходов. Из всех вариантов выбрана следующая нормировка:
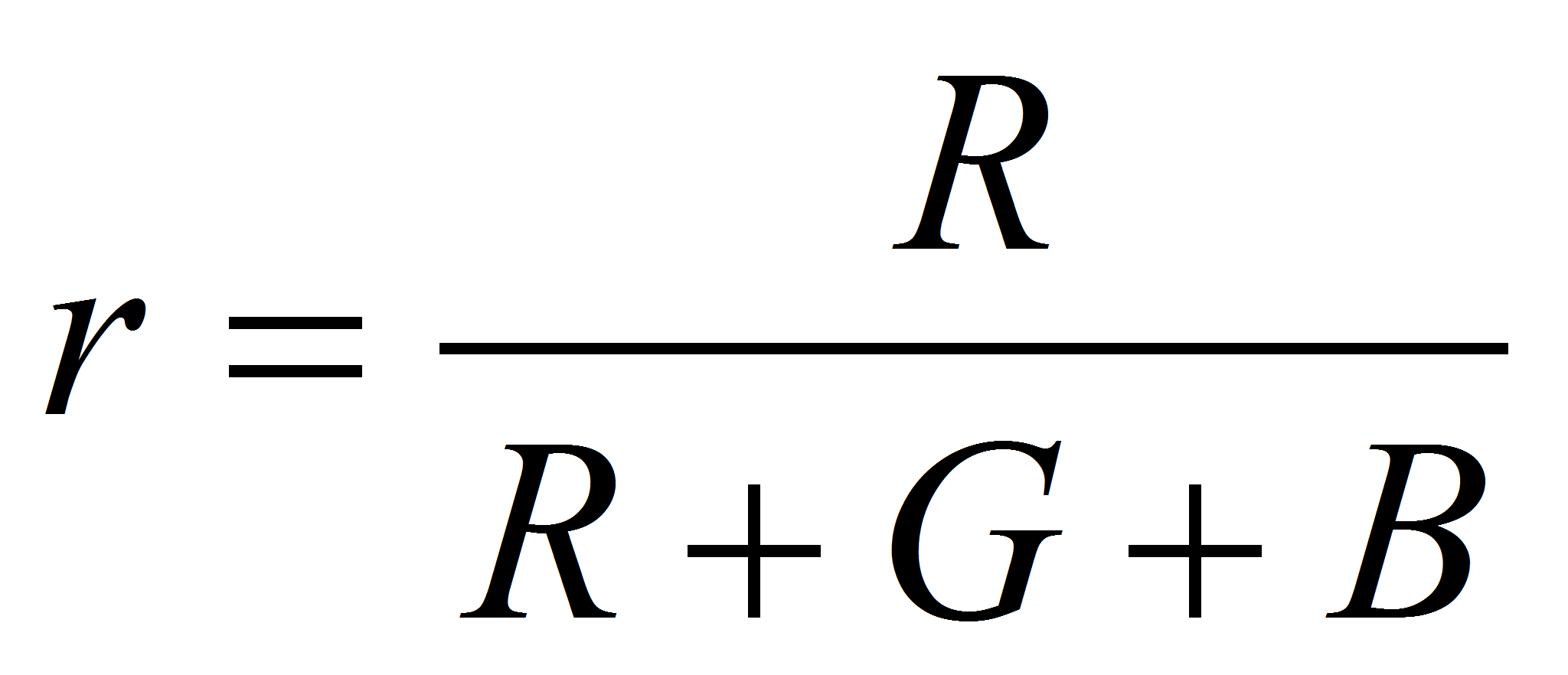 ,
,
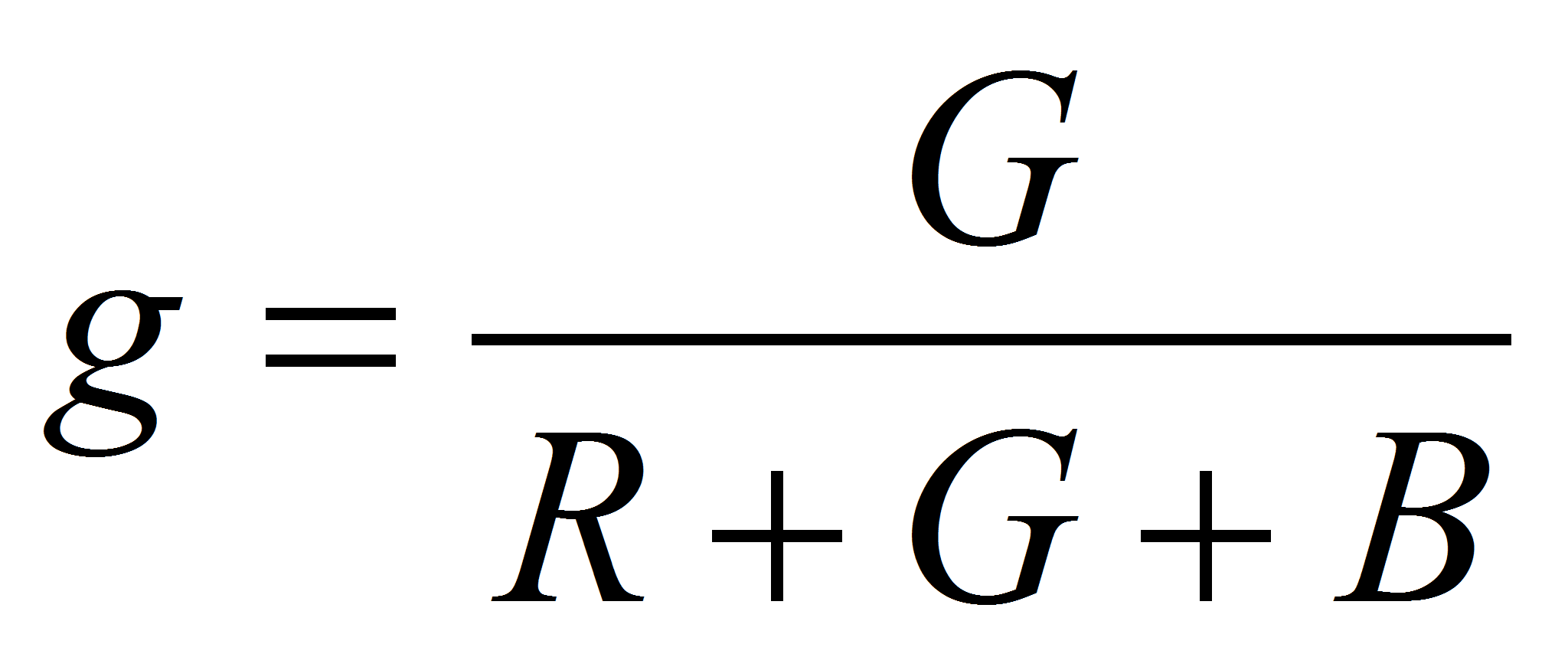 ,
,
 .
.- Запись в векторном виде:
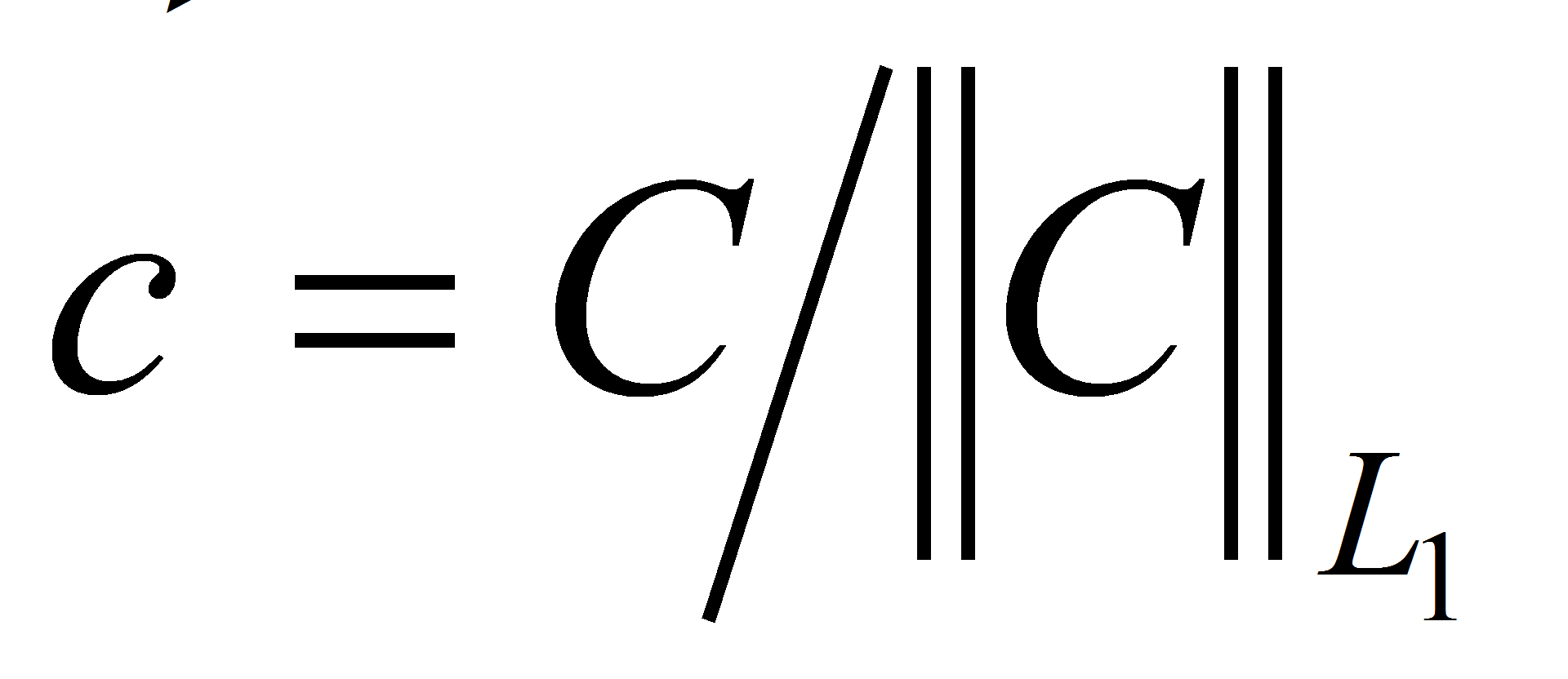 .
Учитывая то, что значения цветовых компонент задаются в диапазоне
.
Учитывая то, что значения цветовых компонент задаются в диапазоне
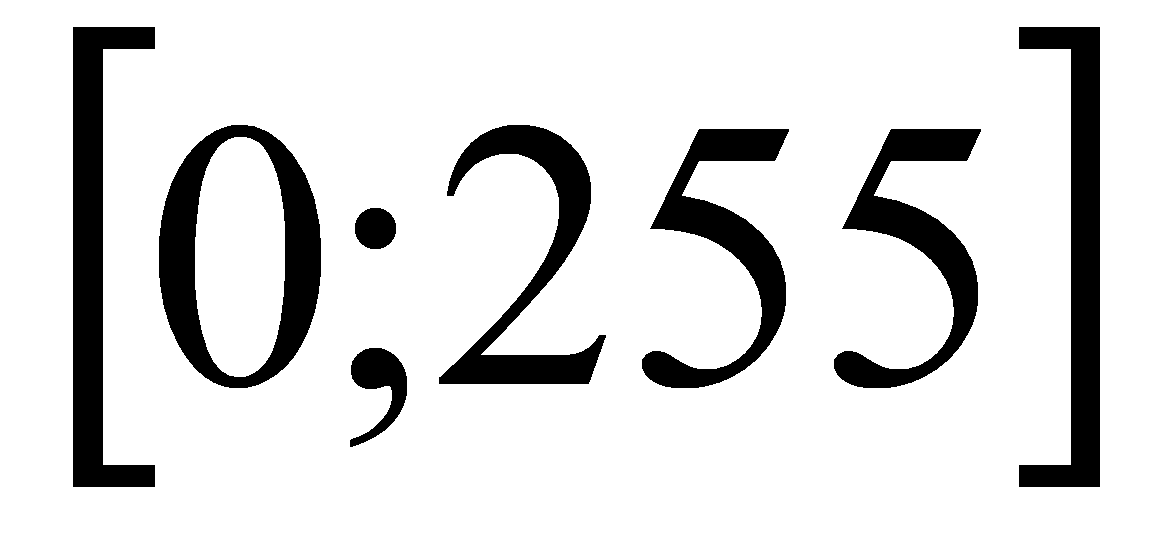 ,
необходимо также домножить на 255, получая в итоге:
,
необходимо также домножить на 255, получая в итоге:
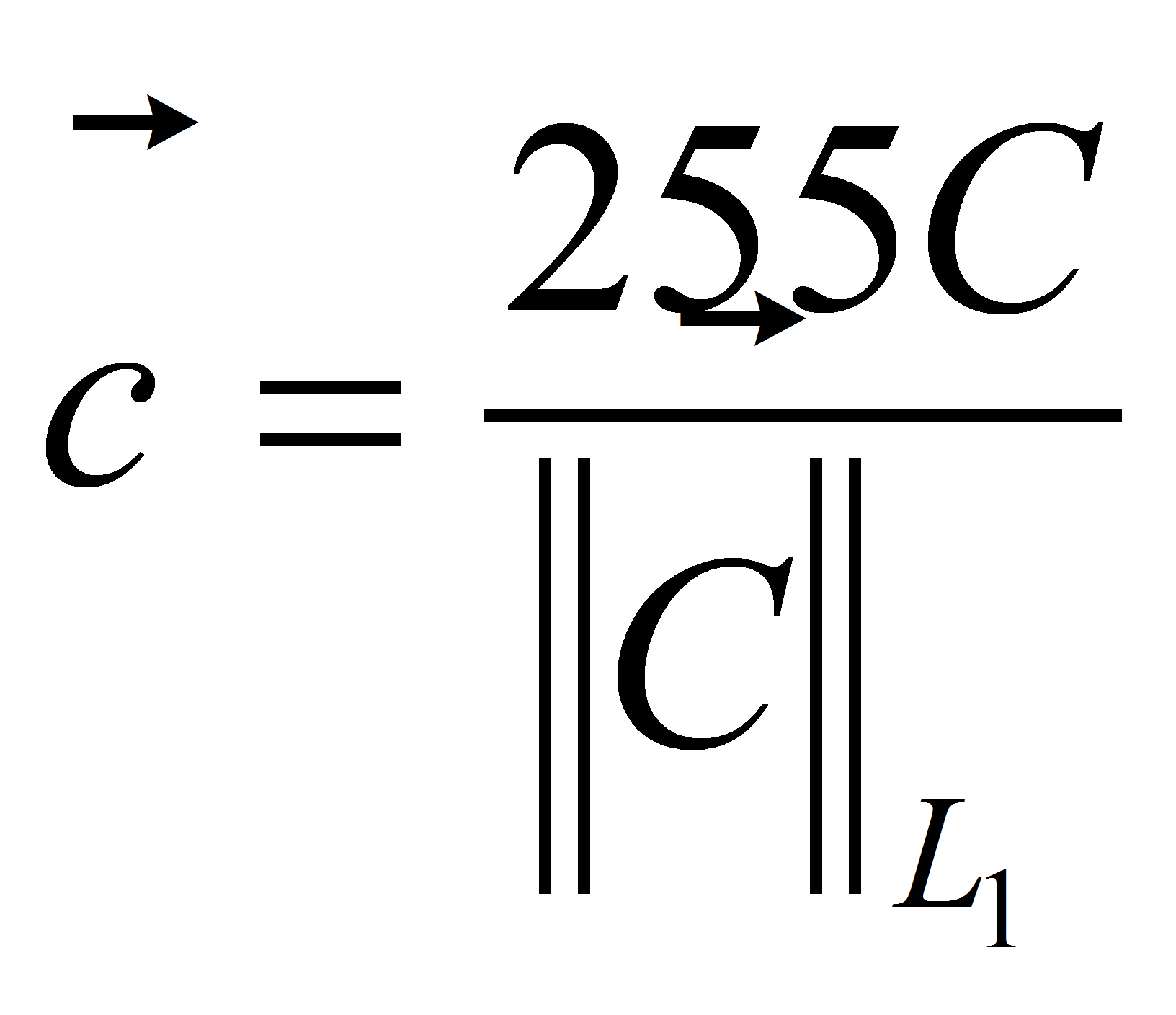 ,
или
,
или
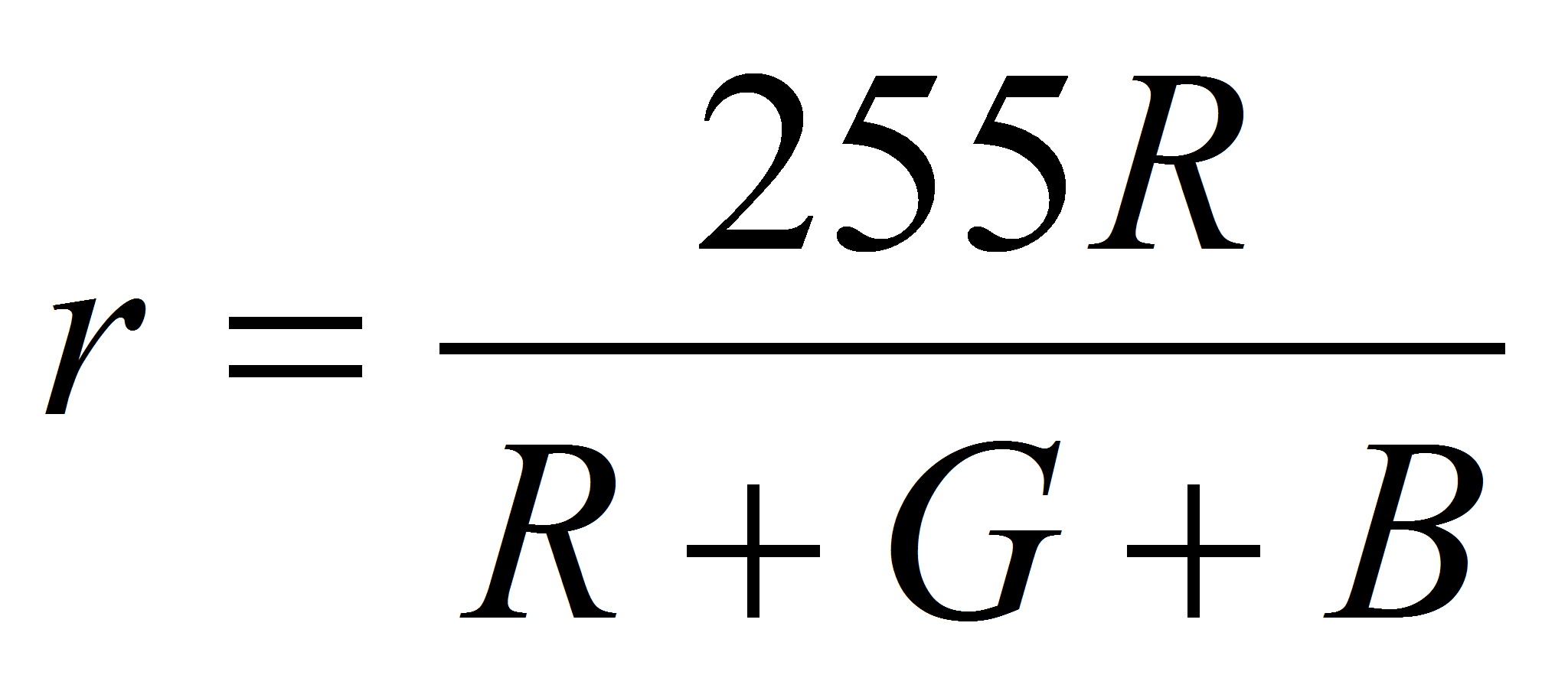 ,
,
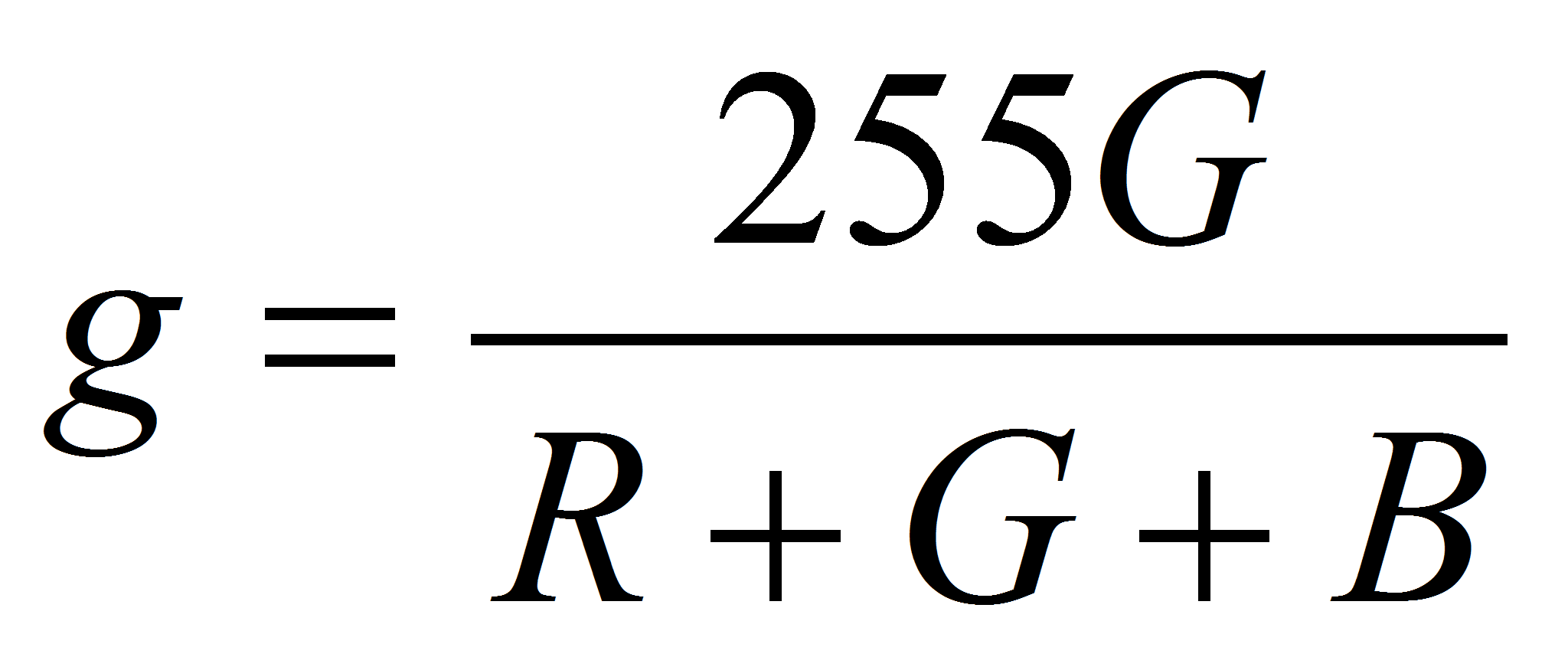 ,
,
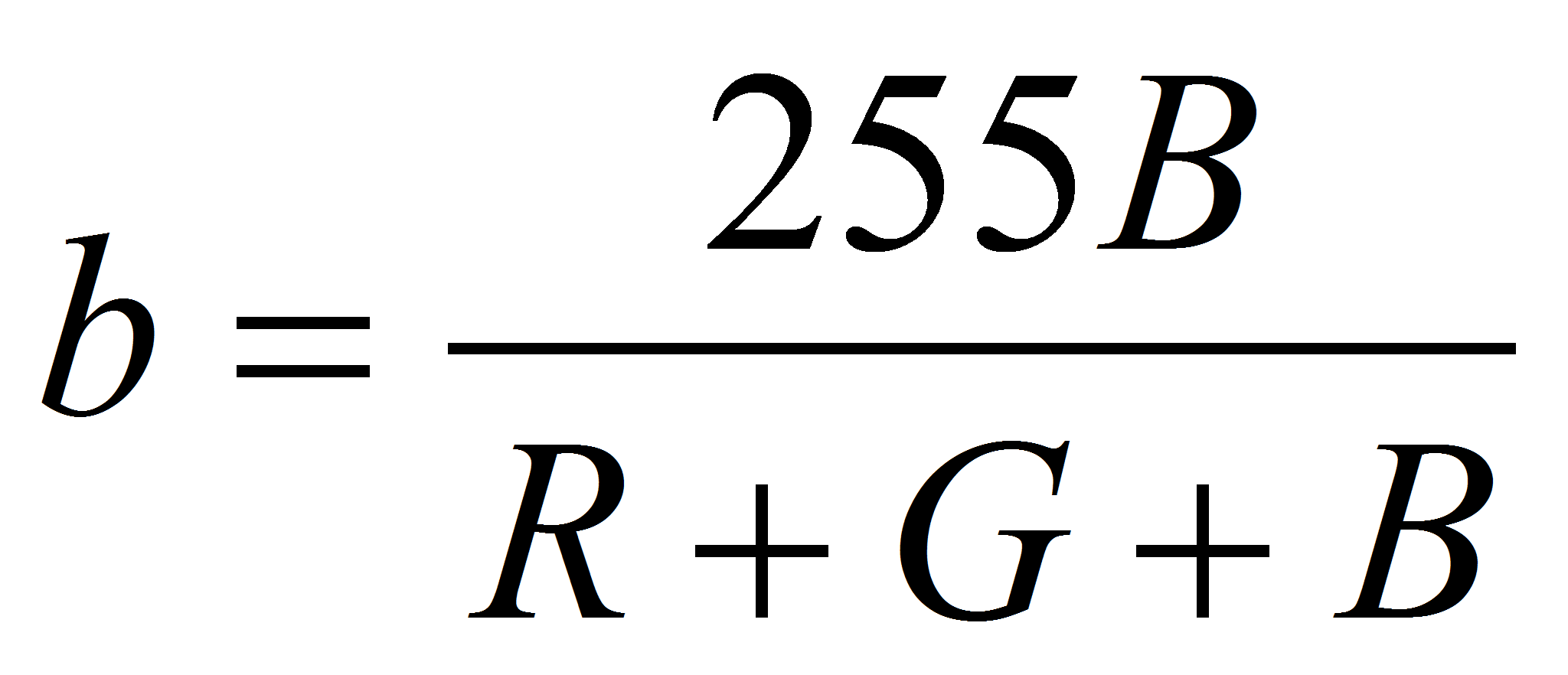
- Можно заметить, что нормированные компоненты, в отличие от исходных, линейно зависимы:
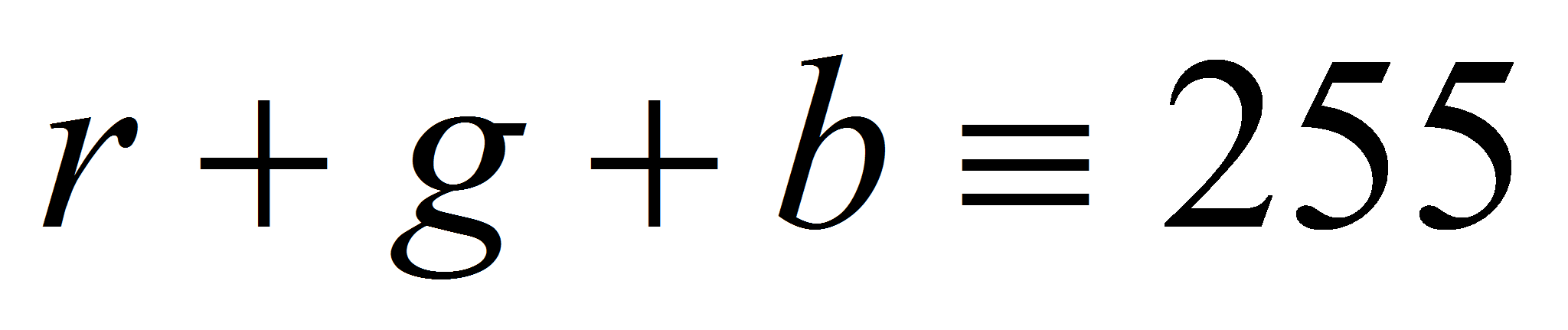 .
Таким образом проявляется исключение яркости.
.
Таким образом проявляется исключение яркости.
- На Рис.1 приведён пример исходного изображения (часть исходного изображения аэрофотосъёмки, размером).
- Выделение тоновых характеристик. Основное модельное ограничение, эксплуатируемое в данном подходе - однотонность окраски автомобиля. Автомобили, раскрашенные в несколько цветов, составляют весьма малую часть (не более 1%) от общего количества, и погрешность (доля пропущенных автомобилей), создаваемая этим ограничением, представляется приемлемой. Видимый цвет окрашенных участков автомобиля задаётся цветом окраски и затенением (углом падения света на окрашенную поверхность). Бликами пренебрегаем.

Рис.1. Исходное изображение
-
Дальнейшая работа происходит в нормированных цветах.
- Формирование областей одинакового тона. Задача состоит в выделении областей одинакового цветового тона, то есть в объединении соседних точек, имеющих одинаковый или близкий цветовой тон, в области. Подход к решению - последовательное слияние близких по цветовым характеристикам областей. Сначала опишем алгоритм в целом.
- Область
 может включать в себя единственную точку изображения
может включать в себя единственную точку изображения
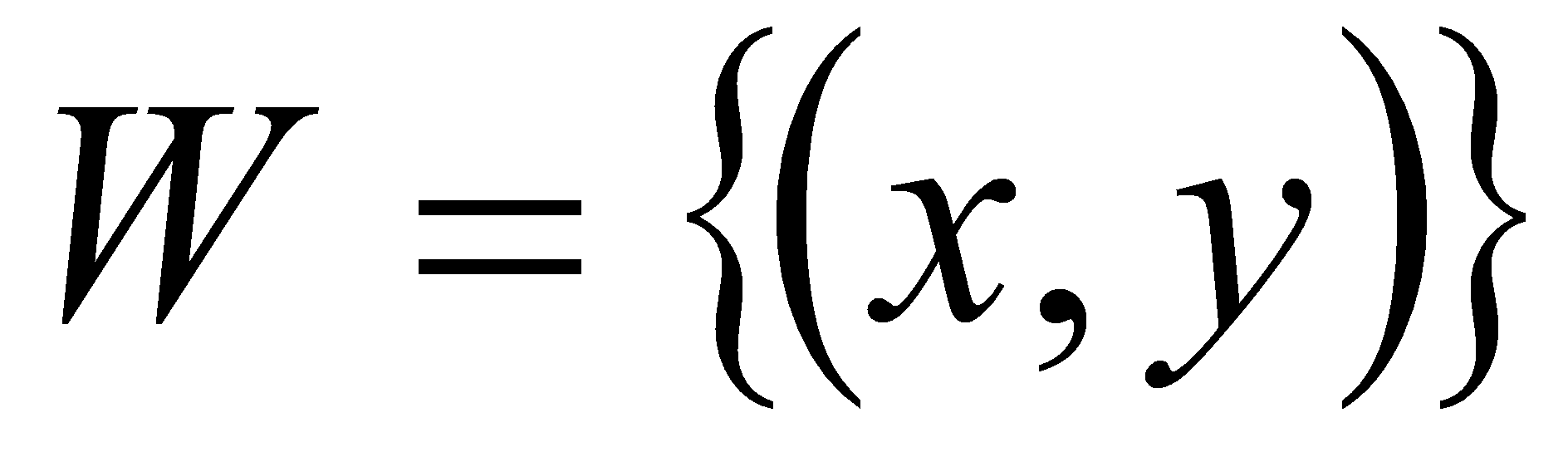 или группу точек
или группу точек
 .
У областей заданы их соседи (такие же области)
.
У областей заданы их соседи (такие же области)
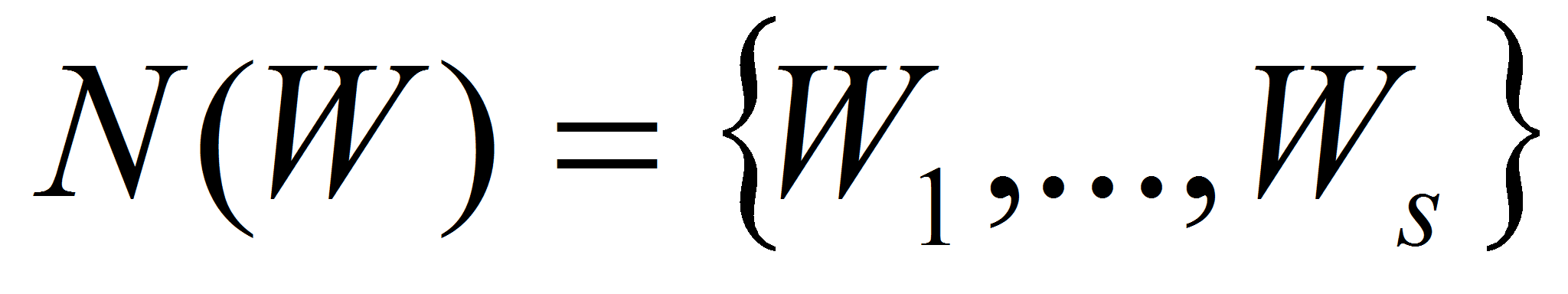 ,
определяемые по принципу 4-связности. Область может иметь от
одного до неопределённо большого (ограниченного сверху количеством
точек изображения) числа соседей. Вырожденный случай - отсутствие
соседей - достигается если всё изображение объединено в одну
область. В каждой точке
,
определяемые по принципу 4-связности. Область может иметь от
одного до неопределённо большого (ограниченного сверху количеством
точек изображения) числа соседей. Вырожденный случай - отсутствие
соседей - достигается если всё изображение объединено в одну
область. В каждой точке
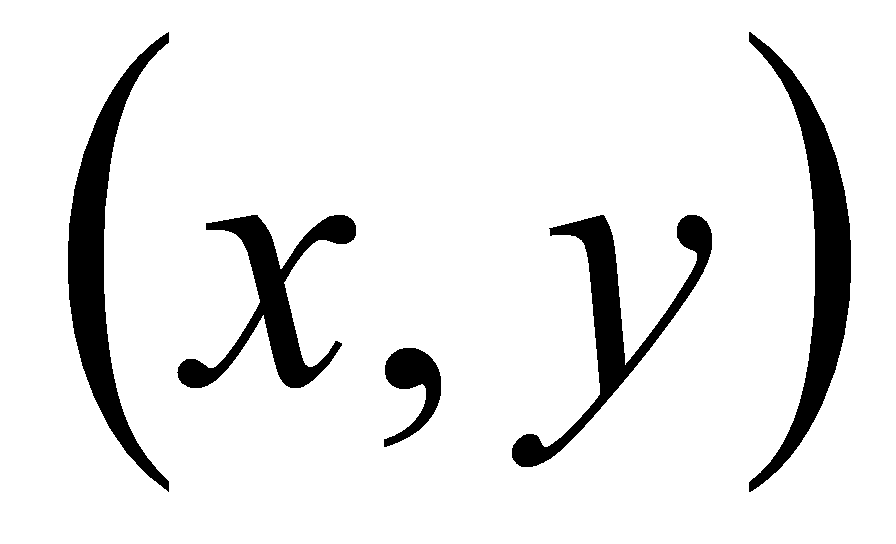 изображения три компоненты яркости
изображения три компоненты яркости
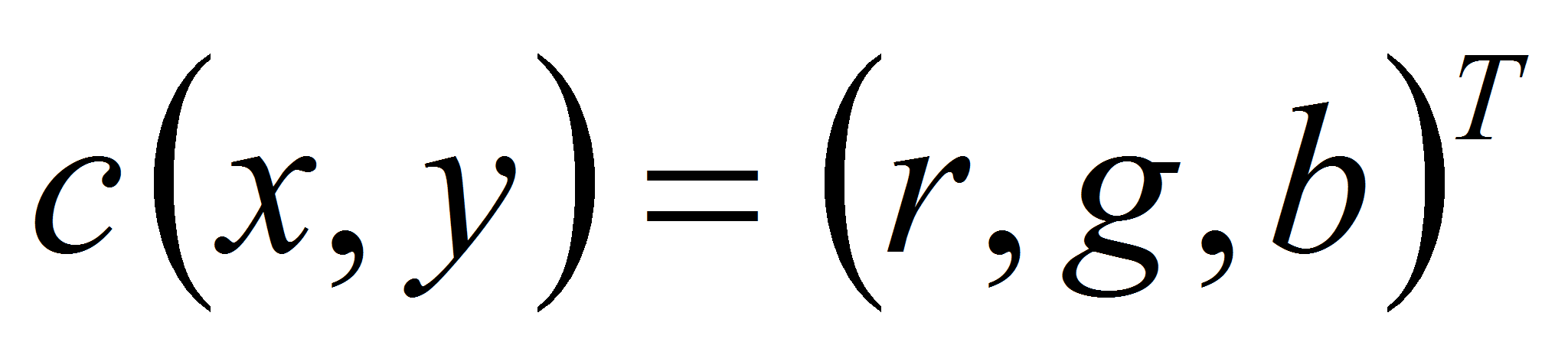 назовём цветовой характеристикой этой точки. Аналогично,
цветовые характеристики области
назовём цветовой характеристикой этой точки. Аналогично,
цветовые характеристики области
 - такие же как у точки три цветовых компонента, являющиеся
усреднением по всем точкам, включенным в область
- такие же как у точки три цветовых компонента, являющиеся
усреднением по всем точкам, включенным в область
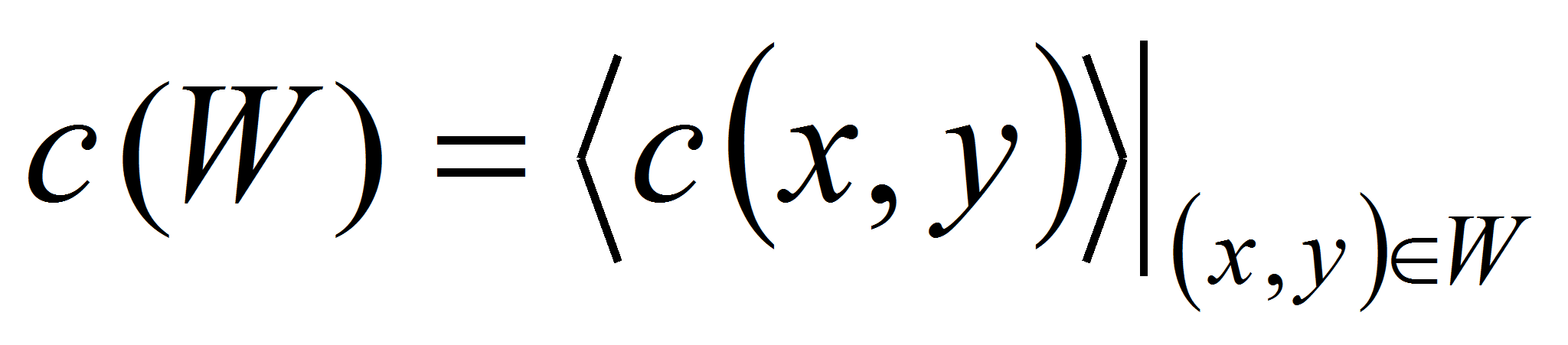 .
Для каждой области в процессе построения определяется общая яркость
.
Для каждой области в процессе построения определяется общая яркость
 по трём компонентам включенных в неё точек и их количество
по трём компонентам включенных в неё точек и их количество
 ,
что позволяет быстро вычислять среднюю яркость:
,
что позволяет быстро вычислять среднюю яркость:
 .
Области могут быть сравнены по их цветовым характеристикам (а также
по размерам). Если характеристики близки, то есть различие между
характеристиками множеств меньше некоторого порога
.
Области могут быть сравнены по их цветовым характеристикам (а также
по размерам). Если характеристики близки, то есть различие между
характеристиками множеств меньше некоторого порога
 ,
и области являются соседями
,
и области являются соседями
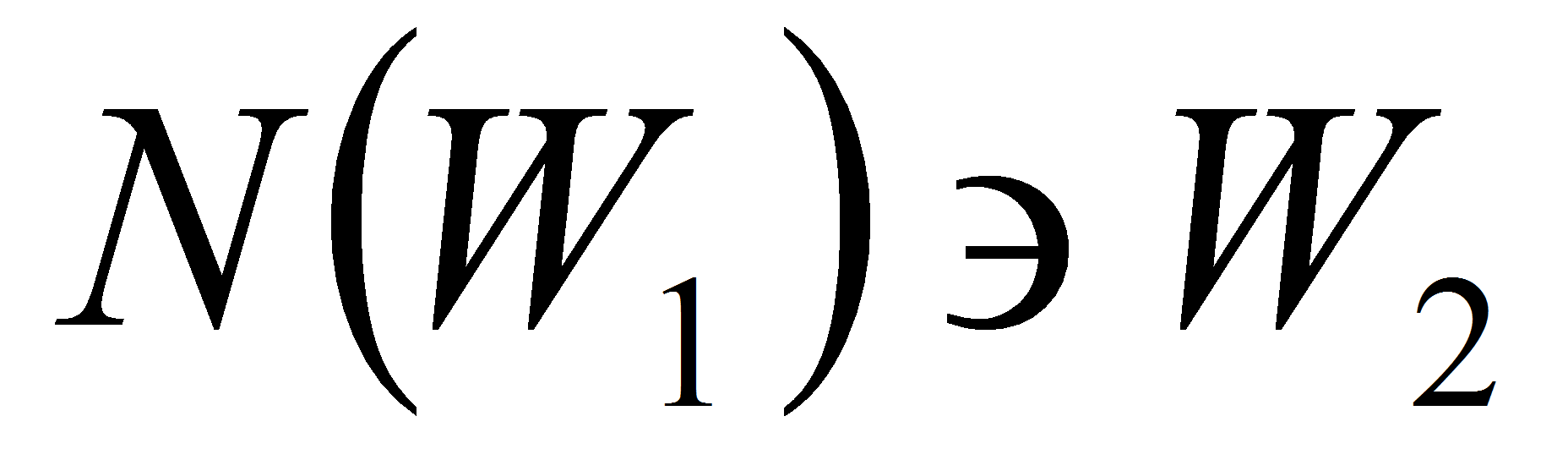 (то есть хотя бы одна точка одной 4-связна с хотя бы одной точкой
другой), то области объединяются
(то есть хотя бы одна точка одной 4-связна с хотя бы одной точкой
другой), то области объединяются
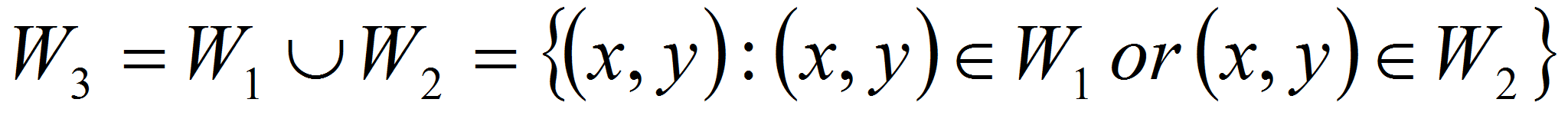 .
Каждое объединение производится для двух и только двух
областей
.
Каждое объединение производится для двух и только двух
областей
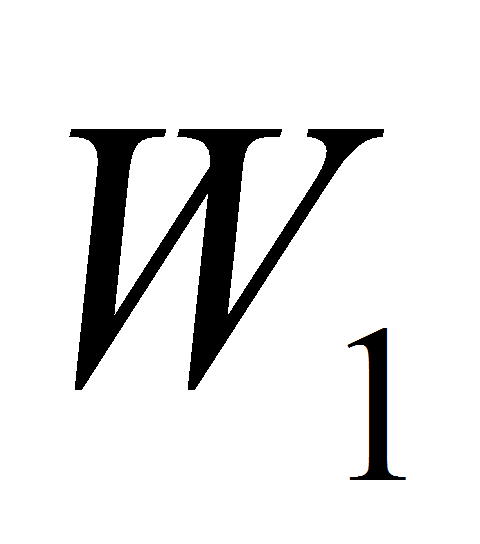 и
и
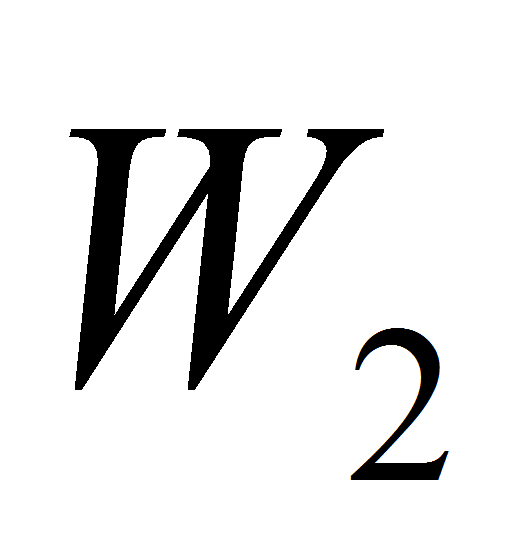 ,
в результате появляется новая (родительская, хотя данный
термин не совсем удачен) область
,
в результате появляется новая (родительская, хотя данный
термин не совсем удачен) область
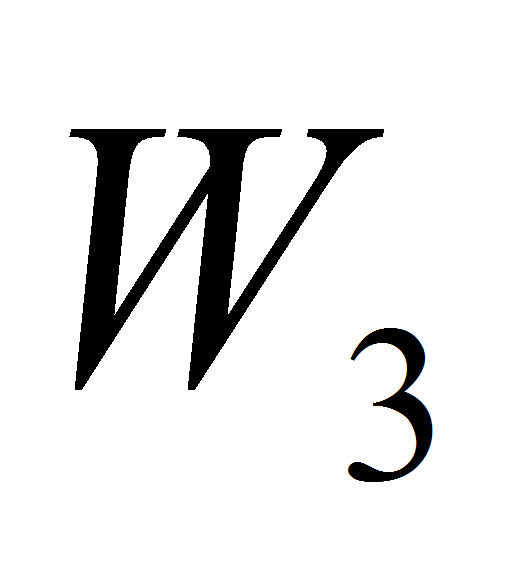 ,
которая имеет тех же соседей, что и исходные области
,
которая имеет тех же соседей, что и исходные области
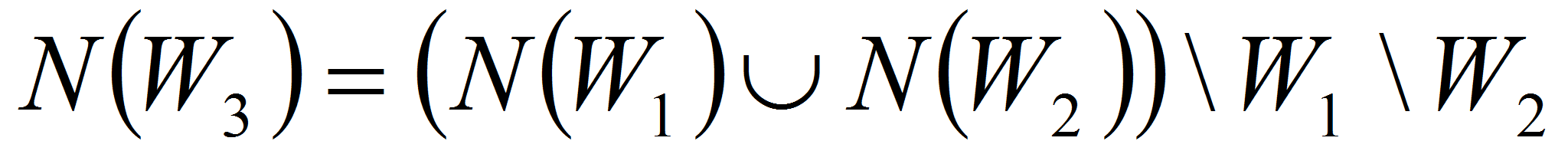 ,
а её яркости и число точек являются суммами соответствующих
характеристик исходных областей
,
а её яркости и число точек являются суммами соответствующих
характеристик исходных областей
 ,
,
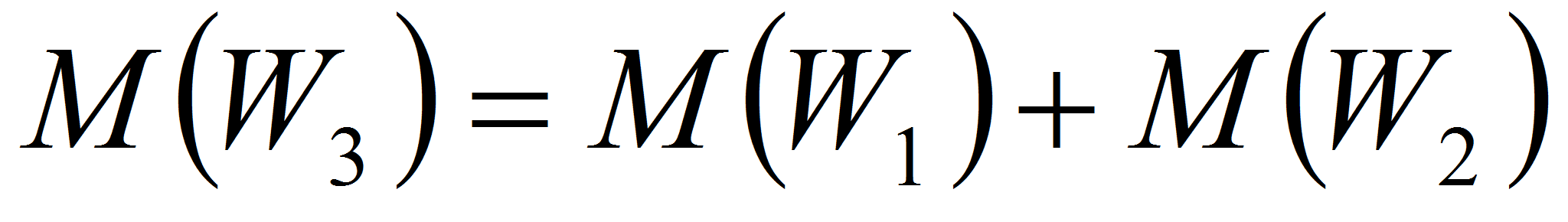 .
Такая новая область делается активной (то есть может
участвовать в дальнейших объединениях), а две объединённые в неё
области становятся пассивными и в дальнейших объединениях не
участвуют. На каждом шаге
.
Такая новая область делается активной (то есть может
участвовать в дальнейших объединениях), а две объединённые в неё
области становятся пассивными и в дальнейших объединениях не
участвуют. На каждом шаге
 работы алгоритма существует упорядоченный список активных
областей
работы алгоритма существует упорядоченный список активных
областей
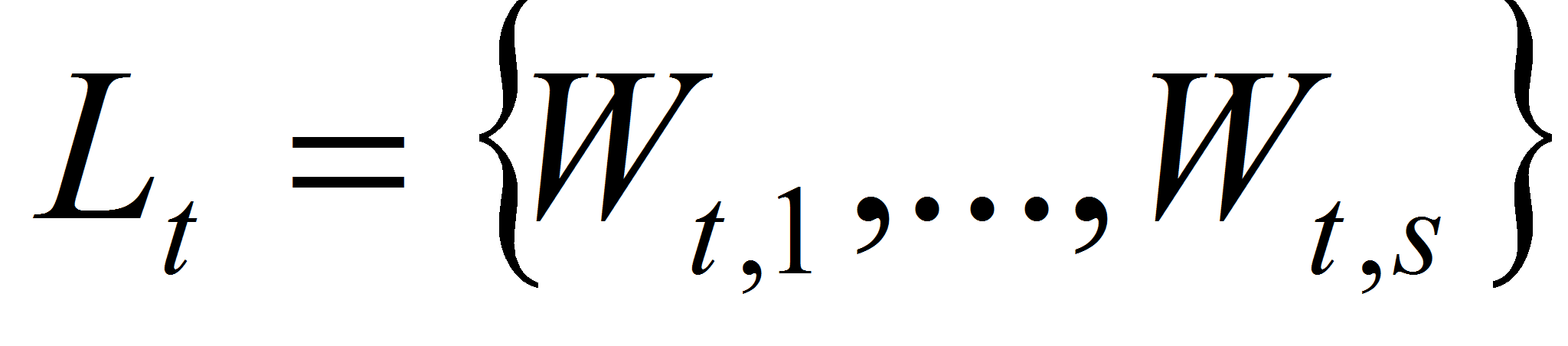 ,
то есть таких, которые ещё не слились ни с какими другими и являются
отдельными.
,
то есть таких, которые ещё не слились ни с какими другими и являются
отдельными.
- В начальный момент при инициализации список активных объектов заполняется точками изображения
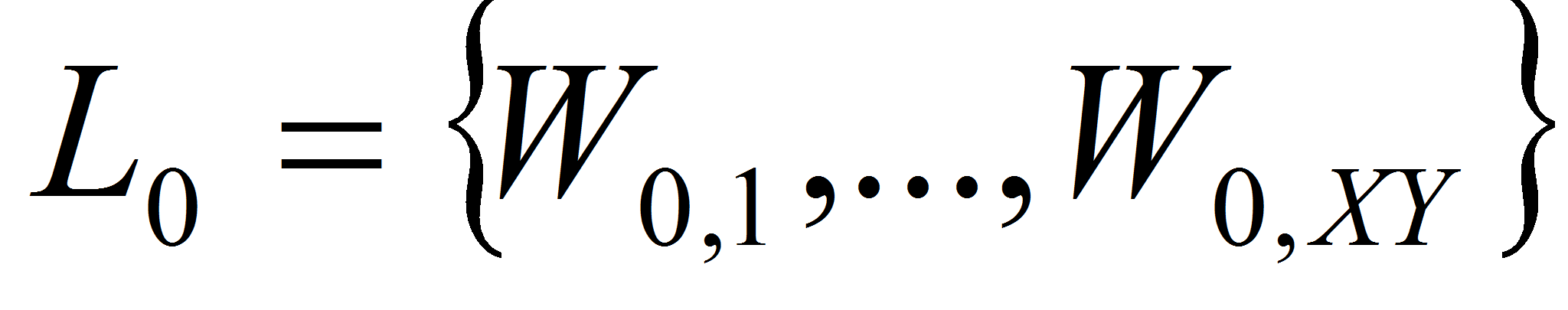 ,
,
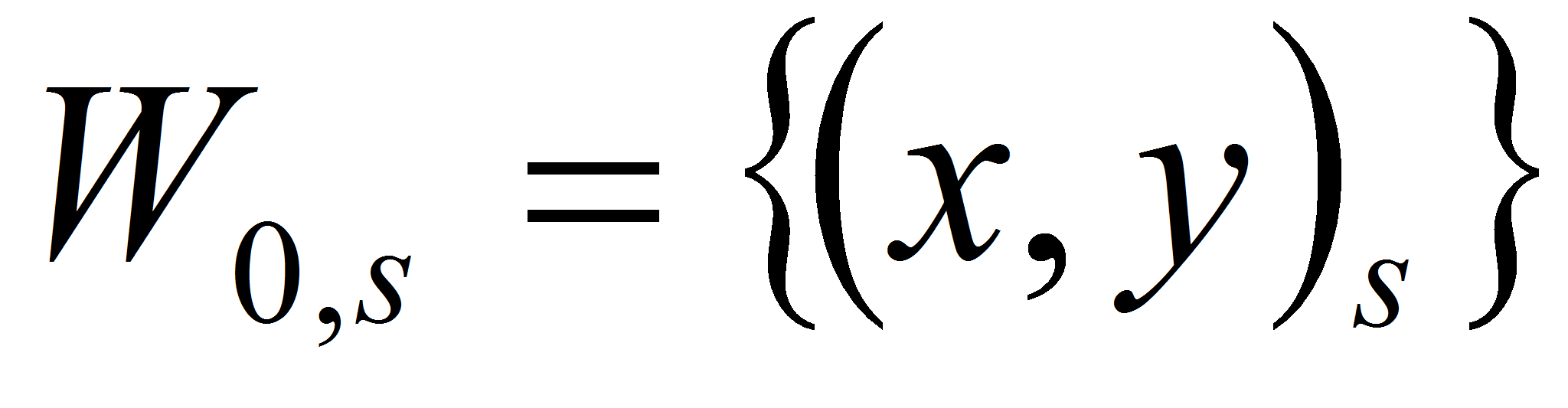 ,
,
 ,
,
 ,
,
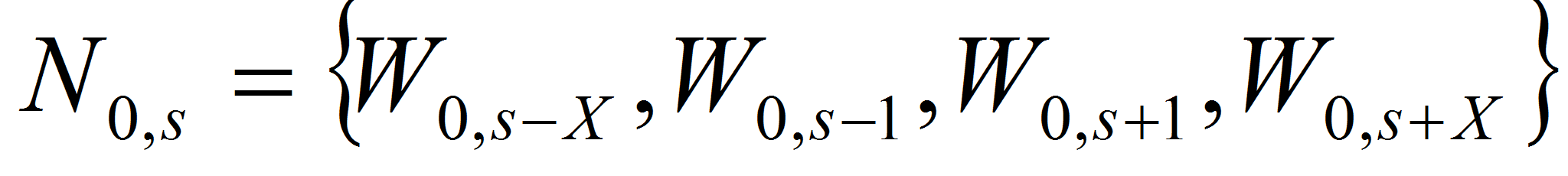 .
Последняя запись означает, что соседями каждого элементарного
множества становятся четыре других элементарных множества,
полученных из соответствующих точек растра. На каждом шаге алгоритма
из списка активных областей выбирается очередная и производится
анализ возможности объединения с каждым из её соседей. Если такое
объединение возможно, оно происходит. В каждом проходе алгоритма
просматривается список всех активных областей. Один проход алгоритма
объединения (то есть анализ всех активных областей, имеющихся в
момент начала прохода, но не новых, появившихся во время прохода)
называется также поколением. Алгоритм заканчивает работу,
когда при очередном проходе не произведено ни одного объединения, то
есть никакие две активные области не могут более слиться при
заданных требованиях на слияние.
.
Последняя запись означает, что соседями каждого элементарного
множества становятся четыре других элементарных множества,
полученных из соответствующих точек растра. На каждом шаге алгоритма
из списка активных областей выбирается очередная и производится
анализ возможности объединения с каждым из её соседей. Если такое
объединение возможно, оно происходит. В каждом проходе алгоритма
просматривается список всех активных областей. Один проход алгоритма
объединения (то есть анализ всех активных областей, имеющихся в
момент начала прохода, но не новых, появившихся во время прохода)
называется также поколением. Алгоритм заканчивает работу,
когда при очередном проходе не произведено ни одного объединения, то
есть никакие две активные области не могут более слиться при
заданных требованиях на слияние.
- Требования на слияние при разных проходах могут различаться. Список активных областей организован как очередь FIFO (первый вошёл, первый вышел), новые активные области добавляются в конец. Таким образом, после
 -го
прохода в результате произведённых объединений список активных
областей удлиняется и
-го
прохода в результате произведённых объединений список активных
областей удлиняется и
 -й
проход производится просто как продолжение сканирования списка
активных областей, без возврата в начало списка. В конце концов
случается так, что при очередном проходе не происходит ни одного
слияния и алгоритм должен был бы завершить работу. Однако, при этом
остаются активные области, которые были пропущены при первом
сканировании (если активная область была пропущена, то она более не
рассматривается, поскольку возврата в начало списка не
производится). Эти активные области могут быть объединены (с учётом
того, что правила объединения могут изменяться в разных проходах).
Поэтому имеет смысл произвести сканирование списка активных
областей, с самого начала. Такое сканирование (последовательность
проходов или поколений) начиная с первой активной области до тех пор
пока очередной проход не будет безрезультатен, называется эрой.
Окончательно алгоритм прекращает работу, когда в результате
прохождения эры не было зафиксировано ни одного слияния (в этом
случае эра вырождена в один проход, также безрезультатный).
-й
проход производится просто как продолжение сканирования списка
активных областей, без возврата в начало списка. В конце концов
случается так, что при очередном проходе не происходит ни одного
слияния и алгоритм должен был бы завершить работу. Однако, при этом
остаются активные области, которые были пропущены при первом
сканировании (если активная область была пропущена, то она более не
рассматривается, поскольку возврата в начало списка не
производится). Эти активные области могут быть объединены (с учётом
того, что правила объединения могут изменяться в разных проходах).
Поэтому имеет смысл произвести сканирование списка активных
областей, с самого начала. Такое сканирование (последовательность
проходов или поколений) начиная с первой активной области до тех пор
пока очередной проход не будет безрезультатен, называется эрой.
Окончательно алгоритм прекращает работу, когда в результате
прохождения эры не было зафиксировано ни одного слияния (в этом
случае эра вырождена в один проход, также безрезультатный).
- Представим работу алгоритма в виде блок-схемы (Рис.2).
- Оценим алгоритмическую сложность. Рассмотрим идеальный случай изображения, заполненного единственным цветом (которое будет объединено в единственную область). Пусть изображение имеет размер
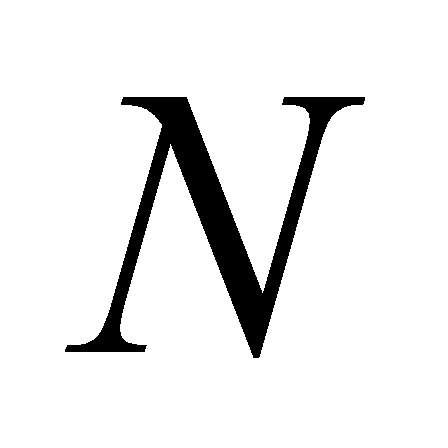 пикселей. В первом проходе они объединятся в
пикселей. В первом проходе они объединятся в
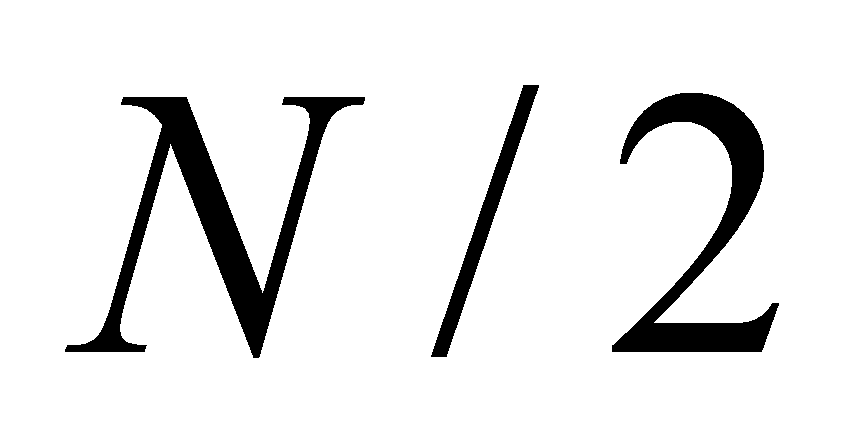 пар (краевыми эффектами пренебрегаем), во втором - в
пар (краевыми эффектами пренебрегаем), во втором - в
 четвёрок и так далее. Всего будет осуществлён
четвёрок и так далее. Всего будет осуществлён
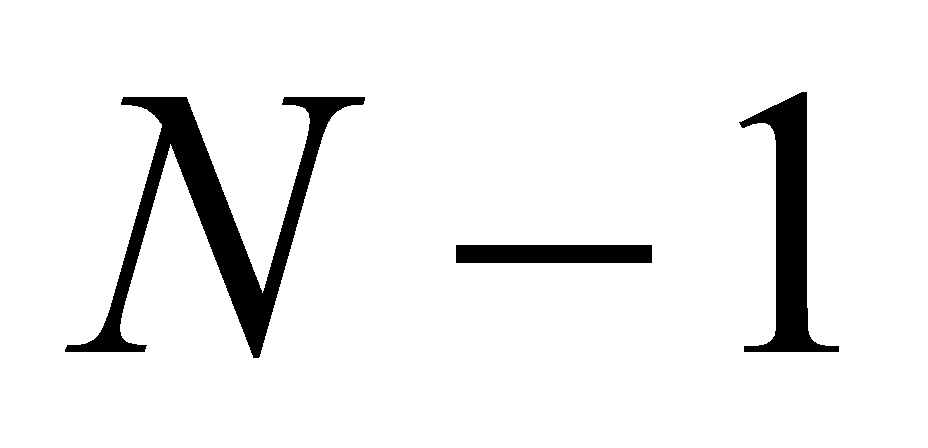 акт объединения. Очевидно, что число объединений равно разности
числа точек изображения и числа полученных в конце работы областей.
Значит, для изображений более сложной структуры объединений будет
меньше. Таким образом, по объединениям сложность алгоритма линейная.
Сложность по просмотрам. В самом худшем случае при каждом просмотре
будет происходить лишь одно объединение, и каждый следующий просмотр
будет анализировать лишь на одну пару меньше и число сравнений
областей будет пропорциональным квадрату числа точек изображения.
Таким образом, сложность по просмотрам - квадратичная. Однако, для
реальных изображений с большими областями приблизительно равных
оттенков, которые объединятся в первых же поколениях, квадратичное
возрастание сложности произойдёт лишь на окончательных стадиях
работы метода, когда число активных областей будет очень невелико по
сравнению с их начальным количеством. Общее число операций возрастёт
незначительно.
акт объединения. Очевидно, что число объединений равно разности
числа точек изображения и числа полученных в конце работы областей.
Значит, для изображений более сложной структуры объединений будет
меньше. Таким образом, по объединениям сложность алгоритма линейная.
Сложность по просмотрам. В самом худшем случае при каждом просмотре
будет происходить лишь одно объединение, и каждый следующий просмотр
будет анализировать лишь на одну пару меньше и число сравнений
областей будет пропорциональным квадрату числа точек изображения.
Таким образом, сложность по просмотрам - квадратичная. Однако, для
реальных изображений с большими областями приблизительно равных
оттенков, которые объединятся в первых же поколениях, квадратичное
возрастание сложности произойдёт лишь на окончательных стадиях
работы метода, когда число активных областей будет очень невелико по
сравнению с их начальным количеством. Общее число операций возрастёт
незначительно.
- Формирование областей одинакового тона. Задача состоит в выделении областей одинакового цветового тона, то есть в объединении соседних точек, имеющих одинаковый или близкий цветовой тон, в области. Подход к решению - последовательное слияние близких по цветовым характеристикам областей. Сначала опишем алгоритм в целом.
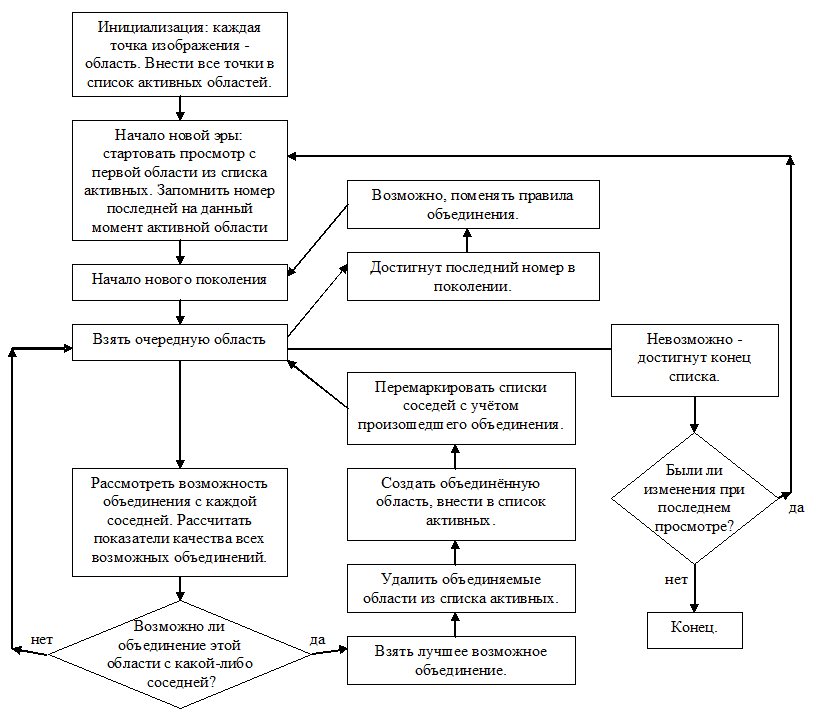
Рис.2. Блок-схема алгоритма объединения областей.
-
- На Рис.3 дан примеры работы алгоритма на малом фрагменте изображения Рис.1. Видно, что из присутствующие на фрагменте два автомобиля выделены в виде областей, но одна из этих областей включает в себя шумовой выброс.
- Выделение однотонных областей - гипотетических автомобилей. Автомобили выделяются прежде всего как области, имеющие определённую площадь, т.е. содержащие определённое число точек. Учитывая известный масштаб изображения можно выбрать пороги количества точек в объектах, соответствующие размеру автомобиля на изображении. В представленных расчётах были использованы пороги
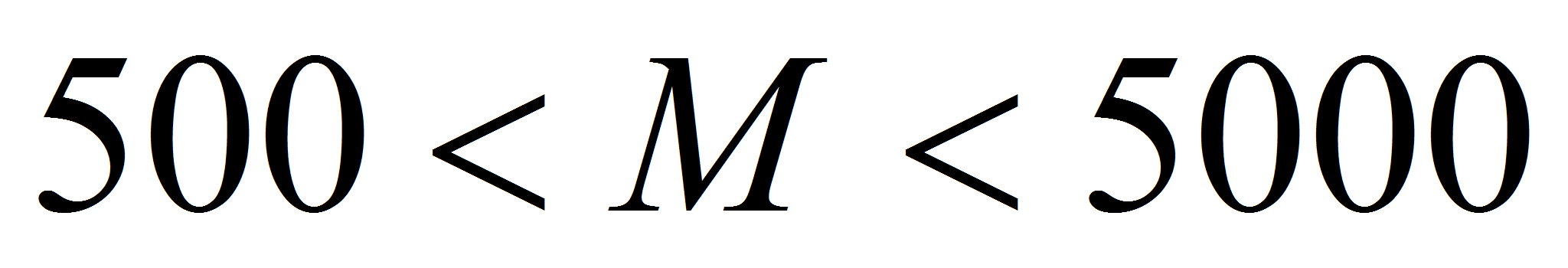 ,
где
,
где
 - число точек объекта. На Рис.4. слева изображены области
изображения Рис 1., попадающие в это ограничение. Видно, что из
присутствующих на исходном изображении восьми автомобилей восемь
остались в виде областей примерно совпадающих размеров, а один
распался на две области. Видно, что наряду с автомобилями имеется
достаточно много других областей. Основная их доля отсекается на
следующем шаге при анализе формы.
- число точек объекта. На Рис.4. слева изображены области
изображения Рис 1., попадающие в это ограничение. Видно, что из
присутствующих на исходном изображении восьми автомобилей восемь
остались в виде областей примерно совпадающих размеров, а один
распался на две области. Видно, что наряду с автомобилями имеется
достаточно много других областей. Основная их доля отсекается на
следующем шаге при анализе формы.
- На Рис.3 дан примеры работы алгоритма на малом фрагменте изображения Рис.1. Видно, что из присутствующие на фрагменте два автомобиля выделены в виде областей, но одна из этих областей включает в себя шумовой выброс.
 Рис.3.
Слева: малый фрагмент изображения, представленного на Рис.1; справа:
двадцать пятое поколение (в псевдоцветах) - окончание работы
алгоритма.
Рис.3.
Слева: малый фрагмент изображения, представленного на Рис.1; справа:
двадцать пятое поколение (в псевдоцветах) - окончание работы
алгоритма.
-
- Вычисление признаков областей и отбраковка. Прежде всего изображение автомобиля - компактная область точек, приблизительно прямоугольной формы с отношением большой и малой сторон отличающимся от единицы, но не слишком большим. Исходя из этого можно воспользоваться моделью эквивалентного эллипса. Требования к эллипсу таковы:
- отношение большой и малой полуосей:
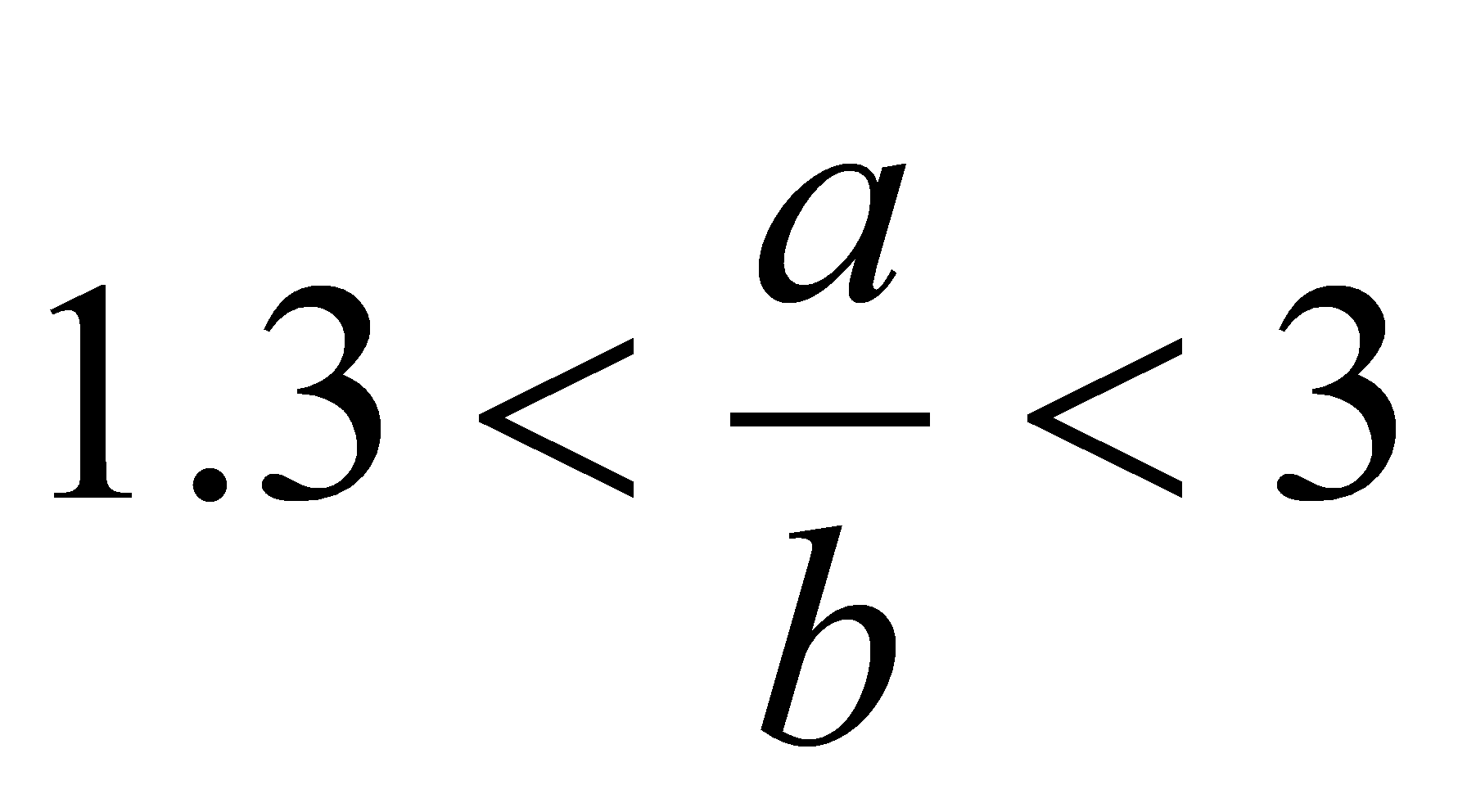 (машина не должна быть квадратной и не должна быть очень длинной);
(машина не должна быть квадратной и не должна быть очень длинной); -
 (площадь эквивалентного эллипса инерции не должна намного
превосходить площадь области, то есть область должна быть
"сплошной", не содержать дыр и длинных выступов).
(площадь эквивалентного эллипса инерции не должна намного
превосходить площадь области, то есть область должна быть
"сплошной", не содержать дыр и длинных выступов).
- На Рис.4. справа представлены области, прошедшие отбраковку по
эллиптичности. Видно, что семь из восьми машин, имеющихся на Рис.1.
выделены, восьмая потеряна. Кроме того, имеется шесть лишних
объектов (не машин).
- Экспериментальная проверка. Были проведены тесты на наборе 46 изображений городской и сельской местности, содержащих в общей сложности 2226 автомобилей. На этих изображениях было обнаружено 1613 автомобилей (72,5%, т.е. ошибка первого рода составляет 17,5%) и было допущено 2452 ложных срабатывания. Эти характеристики не являются удовлетворительными, алгоритм нуждается в дальнейшей доработке.
- Экспериментальная проверка. Были проведены тесты на наборе 46 изображений городской и сельской местности, содержащих в общей сложности 2226 автомобилей. На этих изображениях было обнаружено 1613 автомобилей (72,5%, т.е. ошибка первого рода составляет 17,5%) и было допущено 2452 ложных срабатывания. Эти характеристики не являются удовлетворительными, алгоритм нуждается в дальнейшей доработке.
 Рис.4.
Слева: области изображения, представленного на Рис.1.,
удовлетворяющие ограничениям по площади (числу точек); справа:
области, удовлетворяющие ограничению по форме; тёмные - соответствуют
автомобилям, светлые - ошибки ложного обнаружения.
Рис.4.
Слева: области изображения, представленного на Рис.1.,
удовлетворяющие ограничениям по площади (числу точек); справа:
области, удовлетворяющие ограничению по форме; тёмные - соответствуют
автомобилям, светлые - ошибки ложного обнаружения.
-
- Литература:
- Бондур В.Г., Старченков С.А. Методы и программы обработки и классификации аэрокосмических изображений // Изв. ВУЗов. Геодезия и аэрофотосъемка. 2001. №3. с. 118-143.
- Sotelo M.A., Nuevo J., Bergasa L.M. et al. Road Vehicle Recognition in Monocular Images // Proc. IEEE ISIE 2005. V.4. P.1471-1476.
- Zhao T., Nevatia R. Car Detection in Low Resolution Aerial Image // Proc. IEEE ICCV 2001. V.1. P.710-717.
Negri P., Clady X., Hanif S.M. et al. A Cascade of Boosted Generative and Discriminative Classifiers for Vehicle Detection // EURASIP J. Advances in Signal Processing. 2008. Article ID 782432.
Tsai L.-W., Hsieh J.-W., Fan K.-C. Vehicle Detection Using Normalized Color and Edge Map // IEEE Trans. Image Processing. 2007. V.16. N.3. P.850-864.
Mejía-Inigo R., Barilla-Pérez M.E., Montes-Venegas H.A. Color-based Texture Image Segmentation for Vehicle Detection // www.intechopen.com/download/pdf/15388