




Применение методов кластеризации для обработки новостного потока

Автор: Кутуков Денис Сергеевич
Рубрика: 1. Информатика и кибернетика
Опубликовано в
Статья просмотрена: 5469 раз
Библиографическое описание:
Кутуков, Д. С. Применение методов кластеризации для обработки новостного потока / Д. С. Кутуков. — Текст : непосредственный // Технические науки: проблемы и перспективы : материалы I Междунар. науч. конф. (г. Санкт-Петербург, март 2011 г.). — Санкт-Петербург : Реноме, 2011. — С. 77-83. — URL: https://moluch.ru/conf/tech/archive/2/207/ (дата обращения: 19.04.2024).
В данной работе рассматривается задача выделения сюжетов и тем из потока новостных сообщений. Для решения данной задачи используется кластеризация полнотекстовых статей. Кратко рассматриваются различные типы алгоритмов кластеризации в зависимости от модели представления коллекции объектов: статические, инкрементальные и онлайновые. Дается описание системы новостного онлайн-агрегатора, разработанного на базе поисковой системы. Данная система осуществляет сканирование и кластеризацию статей нескольких интернет-изданий. Рассматриваются использованные подходы к решению проблемы разбиения новостей на связанные по сюжету группы, эффективность использованных алгоритмов и варианты дальнейшего развития системы.
В связи с развитием глобальной сети Интернет в общем и онлайн-ресурсов средств массовой информации в частности значительно возросли объемы информации, с которыми приходится работать конечному пользователю. Это зачастую осложняет задачу поиска актуальной информации среди новостных статей. Другой задачей информационной системы является представление пользователю статей из нескольких источников, написанных об одном и том же событии или персонаже, например, для более обширного представления точек зрения на происходящее.
В данной работе для решения указанных задач рассматриваются методы кластеризации для разбиения статей из поступающего новостного потока на отдельные группы. Эти группы схожих новостных статей могут представлять собой отдельные темы, категории или события. Кластеризация используется в большинстве современных информационно-поисковых систем, обрабатывающих потоки новостных статей. Объединение схожих статей в кластеры делает интерфейс новостной системы более понятным и повышает эффективность работы пользователя с ней. В ходе работы была разработана система, которая периодически извлекает статьи с серверов различных новостных интернет-агентств и автоматически разделяет их на кластеры схожих документов.
Кластеризация – разбиение множества объектов на группы (кластеры), основываясь на свойствах этих объектов. Кластер представляет собой группу объектов, имеющих общие признаки. Целью алгоритмов кластеризации является создание классов, которые максимально связаны внутри себя, но различны друг от друга. Таким образом, характеристиками кластера можно назвать два признака:
внутренняя однородность – документы внутри одного кластера должны быть максимально схожи между собой:
внешняя изолированность – документы из одного кластера должны быть как можно меньше схожи с документами из другого кластера.
Кластеризация является примером стратегии «обучение без учителя», то есть занесение конкретного документа в тот или иной кластер происходит автоматически, без участия эксперта-человека. В кластеризации содержание кластеров определяется только распределением и структурой данных. В этом состоит главное отличие кластеризации данных от другой задачи – классификации данных (Classification) – также широко распространенной в информационном поиске. Классификация представляет собой «обучение с учителем»: его цель – группировка документов по заранее заданным параметрам, признакам – рубрикам. При кластеризации такие параметры изначально не заданы, объединение происходит полностью автоматически.
В данной статье рассматриваются различные методы кластеризации: статической, инкрементальной и онлайн-кластеризации. Последняя применяется в разработанной системе новостного онлайн-агрегатора.
Статическая кластеризация – разбиение изначально известного множества объектов, которое не изменяется до конца работы кластеризации. На статические алгоритмы кластеризации не накладываются ограничения по использованию памяти или количеству проходов по множеству документов.
Формально определим задачу кластеризации следующим образом. Пусть X – множество объектов, Y – множество номеров (имён, меток) кластеров. Задана функция расстояния между объектами
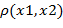 .
Имеется конечная обучающая выборка объектов
.
Имеется конечная обучающая выборка объектов
 .
Требуется разбить выборку на непересекающиеся
подмножества, называемые кластерами,
так, чтобы каждый кластер состоял из объектов,
близких по метрике
.
Требуется разбить выборку на непересекающиеся
подмножества, называемые кластерами,
так, чтобы каждый кластер состоял из объектов,
близких по метрике 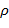 ,
а объекты разных кластеров
существенно отличались. При этом каждому объекту
,
а объекты разных кластеров
существенно отличались. При этом каждому объекту
 приписывается номер кластера yi.
приписывается номер кластера yi.Далее рассматриваются наиболее распространенные алгоритмы статической кластеризации данных.
Цель алгоритма k-means – минимизировать среднее арифметическое сумм квадратов расстояний от каждого документа кластера до его центра, называемого центроидом
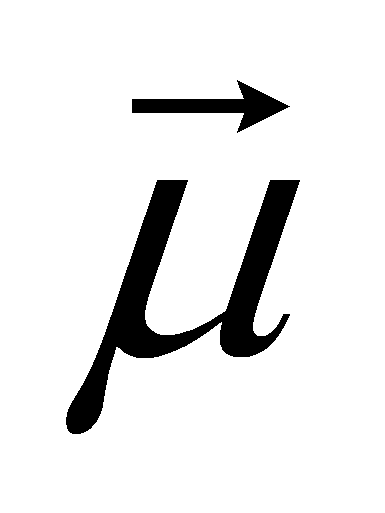 кластера
кластера
 :
:
Предполагается, что документы представлены в виде векторов в пространстве термов, нормализованных по длине.
Показателем того, насколько хорошо центроиды отражают содержимое кластеров, является остаточная дисперсия (residual sum of squares, RSS), вычисляемая как сумма квадратов расстояний между документами кластера и его центроидом:

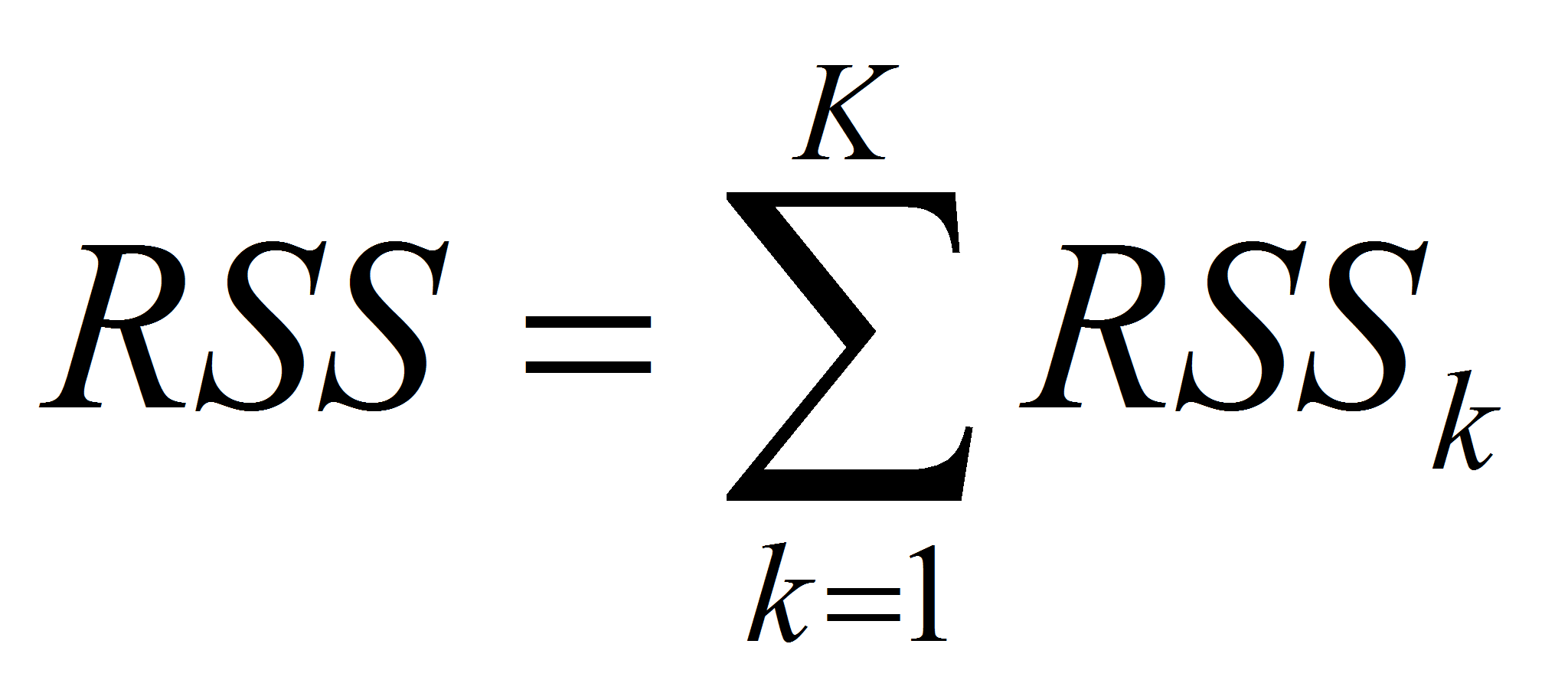
RSS является целевой функцией в алгоритме K-средних, и задача сводится к ее минимизации.
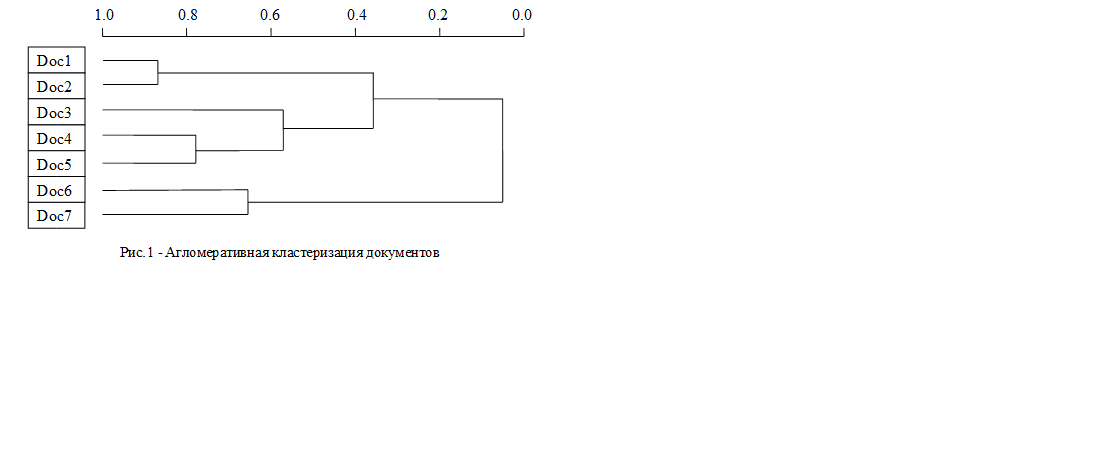
Агломеративный метод производит кластеризацию «снизу-вверх»: на первом этапе все документы коллекции представляются как одиночные кластеры, затем происходит слияние пар наиболее схожих по содержанию кластеров, и так до тех пор, пока не образуется один большой кластер, содержащий все документы. Таким образом, выстраивается бинарное дерево, листья которого – документы исходной коллекции. Пример подобной кластеризации приведен на рис. 1.
Для объединения кластеров документов необходимо выбрать правило вычисления расстояния между кластерами. Существует 4 базовых правила: метод ближайшего соседа (single-link), метод наиболее удаленного соседа (complete-link), попарное среднее (group-average), метод центроидов (centroid clustering).
Данный метод кластеризации основывается на известной задаче теории графов – построении минимального остовного дерева (MST, minimum spanning tree). Исходную коллекцию документов мы представляем как граф, где вершины – документы, а дуги – всевозможные пары документов, вес которых равен расстоянию между их векторными представлениями. Далее по одному из известных алгоритмов строится минимальное остовное дерево, причем при выборе алгоритма необходимо учитывать большое количество дуг в графе (при N документах в коллекции -
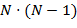 дуг). После построения дерева идет процесс удаления ребер с
наибольшими длинами, в результате чего образуется лес более
маленьких деревьев, из узлов которых и генерируются кластеры.
дуг). После построения дерева идет процесс удаления ребер с
наибольшими длинами, в результате чего образуется лес более
маленьких деревьев, из узлов которых и генерируются кластеры.
Суть алгоритма DBSCAN заключается в обнаружении кластеров на основе предположения о том, что внутри каждого кластера наблюдается типичная плотность объектов, которая значительно выше плотности объектов за пределами кластера. Более того, плотность в областях шума ниже, чем плотность в любом из кластеров. Эта интуитивная нотация «кластеров» и «шума» формализуется для данных в некотором многомерном пространстве, следуя ключевой идее: для каждого объекта кластера соседство заданного радиуса должно содержать, по крайней мере, минимальное количество объектов, т.е. плотность в соседстве должна превышать некоторое пороговое значение. Таким образом, анализируя плотность соседства каждого объекта, исследуется все пространство объектов, а те объекты, которые не вошли ни в один из кластеров, объявляются шумом.
Методы статической кластеризации требуют возможности произвольного доступа к документам и их содержимому. Однако, в связи с возросшими в последнее время объемами обрабатываемых данных, такое требование может привести к большим потерям в производительности приложений и времени обработки коллекций. Поэтому в ряде работ[6][7] рассматриваются методы инкрементальной кластеризации. В них наборы данных представляются в виде потоковой модели.
Дадим формальную постановку задаче инкрементальной кластеризации по аналогии с задачей статической кластеризации. Пусть
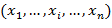 – упорядоченная последовательность элементов множества X,
считываемых в порядке увеличения индекса i.
Требуется разбить выборку на непересекающиеся
кластеры так, чтобы каждый кластер состоял из объектов,
близких по метрике ρ,
а объекты разных кластеров
существенно отличались. При этом каждому объекту xi
приписывается номер кластера yi.
– упорядоченная последовательность элементов множества X,
считываемых в порядке увеличения индекса i.
Требуется разбить выборку на непересекающиеся
кластеры так, чтобы каждый кластер состоял из объектов,
близких по метрике ρ,
а объекты разных кластеров
существенно отличались. При этом каждому объекту xi
приписывается номер кластера yi.- Рассмотрим основные методы, разработанные для решения поставленной задачи инкрементальной кластеризации.
Алгоритм Small-Space – простой алгоритм, использующий парадигму «разделяй и властвуй». Сначала мы разбиваем вся коллекция входящих данных S на m частей X1,..., Xm. Затем каждый такой набор подвергается кластеризации с помощью алгоритма k-means, в результате чего мы находим O(k) центров в каждом наборе (например, 2k – это число устанавливается при настройке алгоритма). После этого разбиваются на группы сами центры, число которых O(mk), и каждому соответствует вес, равный числу документов в его кластере.
Проблемой этого алгоритма является то, что число m анализируемых подмножеств ограничено, так как необходимо хранить в памяти промежуточные центры, число которых mk. Если размер доступной памяти – M, тогда мы должны разбить множество S на m частей так, чтобы каждая помещалась в память, иными словами, n/m ≤ M. Кроме этого, в памяти должны помещаться промежуточные центры, т.е. mk ≤ M. Но такое число m не всегда существует.
Алгоритм BIRCH используется для иерархической кластеризации больших наборов данных. Для каждого кластера вычисляется тройка его свойств CF = (N, LS, SS), где N – количество документов в кластере, LS – их линейная сумма, SS – сумма их квадратов. Для всей коллекции данных и их разбиения на кластеры выстраивается CF-дерево – сбалансированное дерево с двумя параметрами: фактор ветвления B и пороговое значение T. Каждый промежуточный узел содержит не более B вхождений вида [CFi,childi], где childi – указатель на его i-й дочерний узел, CFi – субкластер, представленный этим дочерним узлом. Листовой элемент содержит не более L вхождений вида [CFi]. Размер дерева является функцией от T: чем больше T, тем меньше дерево. Значения B и L определяются P.
На первом шаге алгоритма сканируется вся коллекция документов и выстраивается первоначальное CF-дерево в памяти отведенного размера. На втором этапе просматриваются все листья с целью построения нового дерева с меньшим размером, за счет удаления шума (далеко удаленных документов) и слияния тесно расположенных субкластеров. Затем с помощью одного из известных статических алгоритмов осуществляется кластеризация листовых элементов. Например, удобно использовать иерархический агломеративный метод на субкластерах, представленных их CF-векторами, так как он позволяет пользователю задать или желаемое количество кластеров, или желаемый порог для диаметров кластеров. Для устранения неточностей кластеризации может применяться дополнительный необязательный этап, на котором мы выделяем центроиды кластеров и перераспределяем документы по ближайшим к ним центроидам. В частности, этот шаг помогает избавиться от шума в кластерах.
Все вышеупомянутые методы кластеризации работают с множеством документов, которое задано до начала работы алгоритма. Однако в таких задачах, как автоматическое разбиение статей из новостного потока, общий набор кластеризуемых документов не может быть заранее определен, так как на вход системе непрерывно поступают новые статьи. Для решения этой проблемы требуется либо адаптация существующих алгоритмов статической и инкрементальной кластеризации, либо разработка новых методов с учетом специфики онлайн-кластеризации.
Дадим формальную постановку задаче онлайн-кластеризации по аналогии с задачей статической кластеризации. Пусть
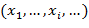 упорядоченная бесконечная счетная последовательность элементов
множества X, считываемых в порядке
увеличения индекса i. Требуется в
каждый момент времени хранить в памяти разбиение множества уже
считанных объектов на непересекающиеся
кластеры так, чтобы каждый кластер состоял из объектов,
близких по метрике ρ,
а объекты разных кластеров
существенно отличались. При этом каждому объекту xi
приписывается номер кластера yi.
упорядоченная бесконечная счетная последовательность элементов
множества X, считываемых в порядке
увеличения индекса i. Требуется в
каждый момент времени хранить в памяти разбиение множества уже
считанных объектов на непересекающиеся
кластеры так, чтобы каждый кластер состоял из объектов,
близких по метрике ρ,
а объекты разных кластеров
существенно отличались. При этом каждому объекту xi
приписывается номер кластера yi.- Для решения поставленной задачи онлайн-кластеризации могут использоваться следующие алгоритмы.
- Базовый алгоритм для кластеризации потока новостных статей имеет следующие этапы:
- считывается новое сообщение;
находится кластер, расположенный наиболее близко к сообщению;
если расстояние между найденным кластером и сообщением меньше заданного порогового значения, то занести сообщение в этот кластер;
- иначе, создать новый кластер, содержащий считанное сообщение.
Данный алгоритм решает проблему онлайн k-кластеризации, т.е. задачи разбиения потоковых данных на кластеры, число которых точно задано и равно k. Алгоритм использует два параметра a и b такие, чтобы
 .
Рассмотим i-ю итерацию алгоритма.
Допустим, в ее начале сформирована коллекция из k
кластеров (С1,…,Сk),
di –
минимальный значение их диаметров. Каждый кластер Сi
имеет центроид ci,
которым является один из принадлежащих ему документов. Каждая
итерация состоит из двух фаз: слияния и обновления. На этапе слияния
мы устанавливаем
.
Рассмотим i-ю итерацию алгоритма.
Допустим, в ее начале сформирована коллекция из k
кластеров (С1,…,Сk),
di –
минимальный значение их диаметров. Каждый кластер Сi
имеет центроид ci,
которым является один из принадлежащих ему документов. Каждая
итерация состоит из двух фаз: слияния и обновления. На этапе слияния
мы устанавливаем
 ,
и на основе этого значения из существующих кластеров формируются
новые кластеры по следующему принципу: Cp
и Cs объединяются
в один кластер, если расстояние между их центроидами cp
и cs меньше или
равно di+1.
В результате работы фазы слияния мы имеем m
≤ k кластеров. На фазе
обновления считываются новые поступающие документы и если расстояние
от нового объекта до ближайшего центроида не превышает величину
,
и на основе этого значения из существующих кластеров формируются
новые кластеры по следующему принципу: Cp
и Cs объединяются
в один кластер, если расстояние между их центроидами cp
и cs меньше или
равно di+1.
В результате работы фазы слияния мы имеем m
≤ k кластеров. На фазе
обновления считываются новые поступающие документы и если расстояние
от нового объекта до ближайшего центроида не превышает величину
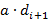 ,
он добавляется в соответствующий кластер. Если документ лежит
достаточно далеко от всех центроидов – образуется новый
кластер. Фаза обновления продолжается до тех пор, пока число
кластеров не станет равно k.
,
он добавляется в соответствующий кластер. Если документ лежит
достаточно далеко от всех центроидов – образуется новый
кластер. Фаза обновления продолжается до тех пор, пока число
кластеров не станет равно k.
В рамках данной работы была реализована система автоматического агрегатора новостных статей. Данная система предназначена для представления пользователю последних новостей и происшествий. Агрегатор собирает статьи различных интернет-изданий СМИ и выделяет из них относящиеся к одним и тем же темам или событиям. Архитектура системы представлена на рис. 2. Рассмотрим работу отдельных модулей агрегатора.
Система состоит из двух программ, работающих независимо друг от друга – сканер новостей и web-сервер. Сканер периодически опрашивает добавленные в список источников новостные серверы, загружая их RSS-ленты и проверяя наличие свежих, еще не обработанных статей. Если такие статьи появились с момента прошлого обхода сканера, происходит загрузка страницы с сайта издания, содержащей полный текст сообщения.
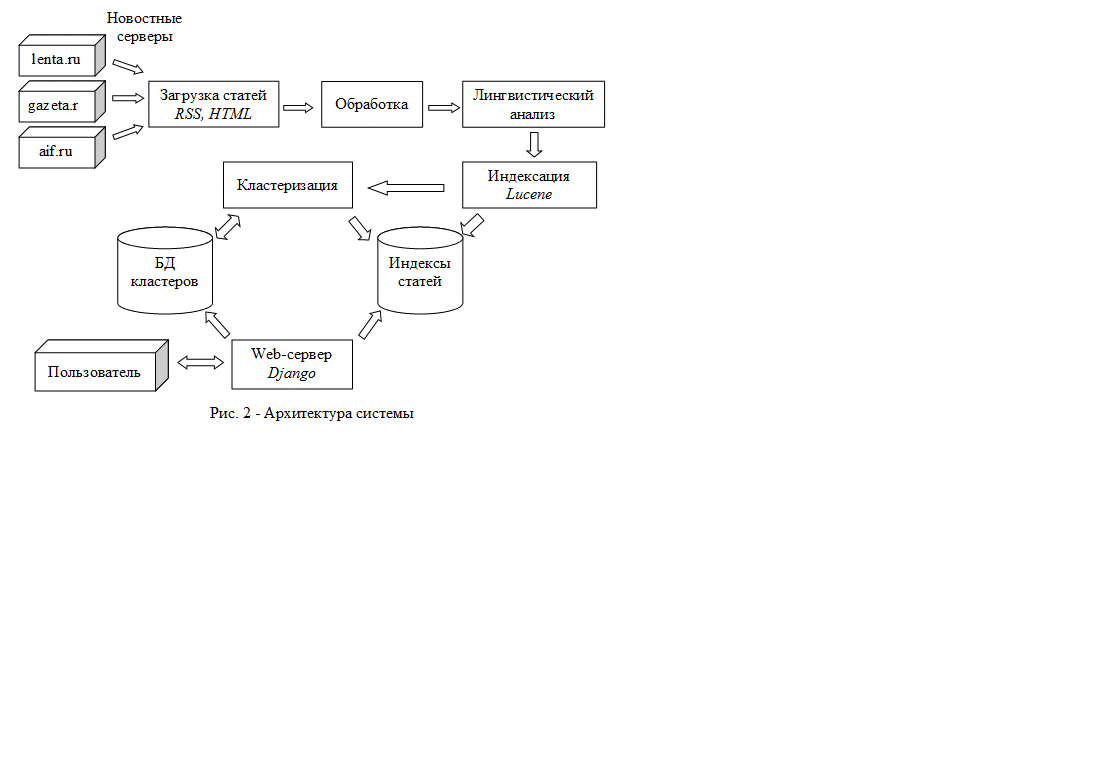
На следующем этапе html-страница подвергается обработке с целью выделения полного текста статьи, не содержащего лишней информации. Вместе с содержанием статьи анализируются ее метаданные – дата публикации, источник, ссылка на первоисточник и т.д. Формируется образ статьи внутри системы.
Затем модуль лингвистического анализа убирает из текста знаки препинания и ненужные стоп-слова, не несущие смысловой нагрузки – союзы, частицы, некоторые наречия и т.д. Применяя алгоритм Портера[4], данный модуль также осуществляет стемминг текста: для каждого слова отбрасывается окончание и выделяется его основа, чтобы одни и те же слова, стоящие в различных грамматических формах (например, «сапог», «сапогов» и «сапоги»), представлялись для системы одинаковыми.
Следующий модуль осуществляет индексацию текста статьи и некоторых метаданных. Индексация производится с помощью свободно распространяемой библиотеки Lucene. Новая статья представляется в виде вектора преобразованных слов (термов) и добавляется в хранилище индексов на файловой системе.
Модуль кластеризации принимает на вход образ статьи, содержащий ее вектор термов, и считывает из базы данных и хранилища индексов данные, необходимые для определения кластера, в который будет занесена новая статья. Вектор термов представляет собой ассоциативный массив пар (term, weight), где term – терм из текста статьи, weight – значение веса этого терма в данной статье. Кластер представляется набором всех статей, содержащихся в нем.
Вес weight, рассчитывается по метрике TF-IDF[1]:
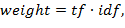
где tf – частота употребления терма в тексте данной статьи. Значение idf определяется по формуле
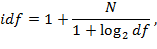
где N – количество документов в текущей коллекции, df – общее число документов, в которых встречается данный терм. Таким образом, наибольший вес имеют слова, которые часто встречаются в тексте данной статьи, но редко – во всей текущей коллекции документов.
Модуль кластеризации использует наивный однопроходный алгоритм, рассмотренный ранее. Расстояние от новой статьи до кластера высчитывается как среднее арифметическое расстояний до всех статей кластера. Для вычисления дистанции между двумя статьями используется косинусная мера близости между их векторами термов:
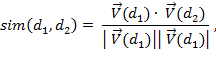
В качестве порогового значения радиуса кластеров экспериментально было подобрано число 0.3. После завершения работы алгоритма кластеризации для новой статьи, ей присваивается идентификатор кластера, пересчитывается центр кластера, и вся информация сохраняется в базу данных.
Параллельно подсистеме сканера новых статей работает web-сервер, задачей которого является обработка входящих пользовательских соединений и запросов. При новом запросе он обращается в базу данных кластеров и отсылает пользователю информацию о последних событиях, основанную на образованных кластерах. Пользователю также предоставляется возможность поиска по тексту статей. Запросы на поиск обрабатываются сервером путем обращения к хранилищу индексов.
Эксперименты проводились на новостных статьях пяти онлайн-источников, находящимся по адресам: www.lenta.ru, www.gazeta.ru, www.aif.ru, www.kp.ru и www.rbc.ru. Подсистема сканера сообщений агрегировала статьи в течение суток. В результате работы системы было собрано 734 статьи и из них выделено 446 кластер. Самый большой кластер содержал 20 статей, а 385 кластеров оказались атомарными.
Вручную с помощью веб-интерфейса системы были оценены точность и полнота результатов кластеризации. Точность – отношение количества верно распределенных в один кластер статей к общему числу статей в этом кластере. Полнота – отношение числа верно распределенных в один кластер статей к общему числу статей о сюжете кластера. В экспериментах подсчитывались средние значения полноты и точности для всех кластеров и сюжетов. При оценке учитывались следующие признаки: количество статей, правильно отсортированных по кластерам, количество статей, которые система неверно занесла в тот или иной кластер, количество кластеров и их размеры, описывающие одно и то же событие и которые должны быть объединены в один (учитывались все такие кластеры, за исключением наибольшего из них). Для оценки точности наблюдались только относительно большие группы, с числом статей больше двух.
В результате были получены значения 55% для точности и 91% для полноты кластеризации. Полученная величина точности является неплохим экспериментальным результатом для подобной системы, но недостаточно качественным для промышленного использования[3]. Высокий процент полноты получен по той причине, что в ходе работы системы было выделено большое число атомарных кластеров, состоящих из одной или двух статей. Подобные кластеры не представляют интереса для пользователя агрегатора, поэтому их следует скрывать при выдаче результатов.
Результаты экспериментов показали, что наивный однопроходный алгоритм онлайн-кластеризации с достаточной эффективностью может применяться в системах обработки новостного потока с небольшим набором источников. Однако можно выделить некоторые методы улучшения как эффективности работы агрегатора, так и экспериментальной базы. Для проведения более точных исследований требуется добавление новых источников статей или анализ работы системы с предоставлением эталонного кластеризационного решения, например на дорожках РОМИП[5].
Для усовершенствования системы агрегатора следует реализовать более эффективные алгоритмы. Одни из таких является метод двухпроходной кластеризации с целью объединения атомарных кластеров[2]. Также повысить эффективность работы может алгоритм онлайн-кластеризации, основанный на принципе статического иерархического, и его разработка является направлением дальнейшей работы в области онлайн-кластеризации. Кроме того, для более точного нахождения меры соответствия сообщений следует использовать более универсальные метрики векторов термов, например BM25[8].
Для анализа новостных потоков можно выделить также следующие направления дальнейших исследований:
поиск главных действующих лиц события, выделение их действий, цитат, объектов, над которыми совершено действие;
- построение аннотаций к текстам статей с помощью наиболее важных ключевых слов;
- анализ связей по ссылкам и ключевым фигурам и объектам между различными статьями, выявление сюжета или анализ линии поведения;
анализ действий пользователя с выдаваемым набором статей на его вопрос, использование этих данных для настройки алгоритмов;
- выявление популярности той или иной статьи на основе анализа комментариев и записей в личных дневниках пользователей, касающихся той или иной новости.
Пескова О.В. Разработка метода автоматического формирования рубрикатора полнотекстовых документов. – Дис. … канд. техн. наук. – Москва, МГТУ им. Н. Э. Баумана, 2008.
Кондратьев М.Е. Анализ методов кластеризации новостного потока. - Труды 8-й Всерос. науч. конф. «Электронные библиотеки: перспективные методы и технологии, электронные коллекции» RCDL’2006. – Суздаль, 2006. – С. 108-114.
Сегалович И., Маслов М., Нагорнов Д. Как работают новые Яндекс.Новости [Электронный ресурс]. – Электрон. дан. – Режим доступа: http://company.yandex.ru/technology/publications/2003-08.xml, свободный.
[Алгоритм выделения псевдооснов Мартина Портера] [Электронный ресурс]. – Электрон. дан. – Режим доступа: http://snowball.sourceforge.net, свободный.
Российский семинар по Оценке Методов Информационного Поиска [Электронный ресурс]. – Электрон. дан. – Режим доступа: http://romip.narod.ru/, свободный.
M. Charikar, C. Chekuri, T. Feder and R. Motwani. Incremental clustering and dynamic information retrieval. // Proceedings of the 29th Annual ACM Symposium on Theory of Computing. - 1997. – P. 626-635.
S. Guha, N. Mishra, R. Motwani, L. O'Callaghan. Clustering data streams. // Proceedings of the Annual Symposium on Foundations of Computer Science (XI’00). IEEE – 2000. – P. 359-366.
Baeza-Yates R., Ribeiro-Neto B. Modern Information Retrieval. – ACM Press/Addison Wesley, 1999.
Похожие статьи
Поэтапный процесс кластерного анализа данных на основе...
Применение методов кластеризации для обработки новостного... Далее рассматриваются наиболее распространенные алгоритмы статической кластеризации данных.
Кластерный анализ разработки современных алгоритмов...
Еще одно достоинство – это огромное количество графических и статических возможностей, которые облегчают
Применение методов кластеризации для обработки новостного...
Рис. 1.Результат кластеризации алгоритмом k-means (k=3). Метод k-means хорошо работает, когда.
Метод кластера в технологии развития критического мышления на...
В настоящее время происходит модернизация российского образования с целью воспитания личности соответствующей актуальным запросам общества, умеющей адаптироваться к изменяющимся условиям жизни, находить выход в критических ситуациях...
Метод k средних при решении задачи распознавания диктора по...
К сожалению, алгоритм кластеризации K-средних чувствителен к выбросам и набор.
Кластер представляет собой группу объектов, имеющих общие признаки. RSS является целевой функцией в алгоритме K-средних, и задача сводится к...
Неконтролируемые методы машинного обучения при...
Методы кластеризации работают, группируя наблюдаемые данные в кластеры, в соответствии с заданным коэффициентом подобия или линией отсчета.
Алгоритм К-средних является традиционным алгоритмом кластеризации.
Метод автоматической классификации документов в задаче...
кластер, алгоритм, документ, инкрементальная кластеризация, статическая кластеризация, кластеризация... Применение метода анализа иерархий для оценки типа...
Расширение модели Виттена-Сэндера. Кластер-кластерная...
Кластер-кластерная агрегация. С тех пор как была реализована виттен-сэндеровская модель, стало понятно, что она не является наиболее приемлемой моделью агрегационных экспериментов на коллоидах и
Кластерный анализ разработки современных алгоритмов...
Кластеры США. Силиконовая долина как пример эффективного...
По словам Владимира Княгинина: «термину «кластер», в его нынешнем понимании, около 150–200 лет.
Итогом указанных исследований явилась классификация типологии пространственной и территориальной организации, где был внедрен такой тип, как кластер.
Применение иерархического кластерного анализа для...
Применение методов кластеризации для обработки новостного... Алгоритм BIRCH используется для иерархической кластеризации больших наборов данных. анализ связей по ссылкам и ключевым фигурам и объектам между различными статьями...
Похожие статьи
Поэтапный процесс кластерного анализа данных на основе...
Применение методов кластеризации для обработки новостного... Далее рассматриваются наиболее распространенные алгоритмы статической кластеризации данных.
Кластерный анализ разработки современных алгоритмов...
Еще одно достоинство – это огромное количество графических и статических возможностей, которые облегчают
Применение методов кластеризации для обработки новостного...
Рис. 1.Результат кластеризации алгоритмом k-means (k=3). Метод k-means хорошо работает, когда.
Метод кластера в технологии развития критического мышления на...
В настоящее время происходит модернизация российского образования с целью воспитания личности соответствующей актуальным запросам общества, умеющей адаптироваться к изменяющимся условиям жизни, находить выход в критических ситуациях...
Метод k средних при решении задачи распознавания диктора по...
К сожалению, алгоритм кластеризации K-средних чувствителен к выбросам и набор.
Кластер представляет собой группу объектов, имеющих общие признаки. RSS является целевой функцией в алгоритме K-средних, и задача сводится к...
Неконтролируемые методы машинного обучения при...
Методы кластеризации работают, группируя наблюдаемые данные в кластеры, в соответствии с заданным коэффициентом подобия или линией отсчета.
Алгоритм К-средних является традиционным алгоритмом кластеризации.
Метод автоматической классификации документов в задаче...
кластер, алгоритм, документ, инкрементальная кластеризация, статическая кластеризация, кластеризация... Применение метода анализа иерархий для оценки типа...
Расширение модели Виттена-Сэндера. Кластер-кластерная...
Кластер-кластерная агрегация. С тех пор как была реализована виттен-сэндеровская модель, стало понятно, что она не является наиболее приемлемой моделью агрегационных экспериментов на коллоидах и
Кластерный анализ разработки современных алгоритмов...
Кластеры США. Силиконовая долина как пример эффективного...
По словам Владимира Княгинина: «термину «кластер», в его нынешнем понимании, около 150–200 лет.
Итогом указанных исследований явилась классификация типологии пространственной и территориальной организации, где был внедрен такой тип, как кластер.
Применение иерархического кластерного анализа для...
Применение методов кластеризации для обработки новостного... Алгоритм BIRCH используется для иерархической кластеризации больших наборов данных. анализ связей по ссылкам и ключевым фигурам и объектам между различными статьями...




