





Возможности биометрической аутентификации по лицу человека при использовании обычной камеры ограничены точностью алгоритмов реконструкции трёхмерной геометрии по освещению лица. Такие алгоритмы постоянно совершенствуются, однако качество данных, получаемых с помощью специализированных сенсоров, остаётся на порядок выше. В данной статье рассматриваются алгоритмы первичной обработки лица человека и построения трёхмерной модели, которая может быть использована для биометрической аутентификации.
Ключевые слова: сенсор движения, карта глубины, множество трёхмерных точек, активная модель, закрашивание, ключевые точки, дескрипторы, поиск соответствий, бинарный поиск, сигнулярное разложение, трёхмерная модель лица.
Существует два основных принципа, которые используются специальными сенсорами движения для определения расстояния до объектов. Сенсоры типа time-of-flight, TOF определяют дальность, используя скорость света, измеряя время пролёта светового сигнала, испускаемого камерой, и отражённого каждой точкой получаемого изображения. Камера обеспечивает точность измерения глубины порядка 1 сантиметра. Такой принцип, к пример, использовался в Microsoft Xbox One Kinect. Второй принцип — структурированная подстветка (structured light). Сенсоры такого типа помимо обычной RGB камеры оснащены также инфракрасной камерой и инфракрасной подсветкой. На объекты в поле зрения RGB камеры проецируется инфракрасная сетка и по положению точек на изображении, полученном с помощью инфракрасного сенсора, определяется расстояние до соответствующих пикселей на обычном изображении. Таким образом, на выходе сенсор формирует 2 кадра — обычный RGB кадр и карту глубины объектов (рисунок 1). Анонсирован выход сенсора Intel RealSense, предназначенного именно для сканирования лица, позволяющего получать изображение высокого качества (рисунок 2).
Однако всем этим сенсорам присущи одни и те же ограничения — точки, до которых не может добраться луч света, или от которых луч света отражается зеркально (глянцевые участки), дают «провалы» на карте глубины.

Рис. 1. Пара кадров, получаемых с помощью сенсора движения Asus Xtion Pro.

Рис. 2. Карта глубины лица, получаемая с помощью сенсора Intel RealSense.
Кроме того, изображения, получаемые непосредственно с помощью драйвера сенсора не выровнены между собой (рисунок 3), и необходима дополнительная процедура нахождения соответствия между точками изображений.

Рис. 3. Наложенная на обычное изображение карта глубины
Для совмещения данных RGB кадров и кадров с картой глубины необходимо знать матрицу преобразования между этими пространствами. Библиотека Point Cloud Library [1] обладает необходимыми данными в том числе и для применяемого в данной работе сенсора Asus Xtion Pro, и была использована для получения множеств трёхмерных цветных точек (рисунок 4).

Рис. 4. Множество трёхмерных цветных точек, полученных с сенсора Asus Xtion Pro
Для сокращения области поиска лица и уменьшения вероятности ложного обнаружения лица, исключаются точки, расстояние до которых больше некоторого заданного значения. Значение выбирается в соответствии с ожидаемым расстоянием нахождения пользователя. В данном случае был выбран порог в 1 метр. Выполняется проекция оставшегося облака точек в пространство RGB.
Для поиска ключевых точек на изображении лица, к которым, например, относятся центры глаз, кончик носа, углы рта, используются активные модели [2]. Активная модель представляет собой статистическую модель расположения ключевых точек на лице человека, сформированную с использованием большой базы лиц с вручную определёнными координатами ключевых точек. При применении активной модели для определения ключевых точек на конкретном изображении статистическая модель «накладывается» на реальное лицо и деформируется для наибольшего совпадения с ним (рисунок 5).

Рис. 5. Поиск ключевых точек с использованием адаптивной модели внешнего вида
После того, как с помощью активной модели множество трёхмерных точек, принадлежащих лицу, установлено, задача регрессии для нахождения плоскости лица (рисунок 5) решается c помощью метода главных компонент. Для множества точек лица находятся 2 главных компоненты, коэффициенты которых представляют собой координаты векторов, образующих плоскость.
Находится матрица преобразования, описывающая поворот плоскости xOy к плоскости, параллельной плоскости лица. Выполняется проекция множества точек на найденную плоскость. В результате проекции множества точек на плоскость, параллельную лицу, изображение лица остаётся фронтальным несмотря на повороты лица (рисунок 6).
|
Исходное облако точек |
Проекция в RGB после поворота |
|
|
|
|
|
|
|
|
|






Рис. 6. Выравнивание плоскости лица
Поворот множества точек приводит к появлению «провалов» при проекции в RGB пространство. В пространстве RGB изображение может быть восстановлено с помощью метода закрашивания Александру Телеа (Alexandru Telea [3]). Восстановленные с помощью закрашивания изображения лица, для кадров, приведённых выше, показаны на рисунке 7.



Рис. 7. Восстановленное изображение лица
Другой, более предпочтительный вариант — совмещение нескольких множеств цветных трёхмерных точек, полученных с разных кадров. Трёхмерная модель лица, полученная с помощью одного кадра (для сенсора Asus Xtion Pro) является достаточно грубой.
Для уточнения модели необходимо объединять множества трёхмерных точек, полученных с разных кадров, для этого для каждой пары последовательных кадров i, i+1 выполняется следующий алгоритм:
1. Выполняется поиск ключевых точек SIFT [4].
2. Для найденных ключевых точек вычислить дескрипторы FPFH [5].
3. Найти соответствия между найденными дескрипторами с помощью алгоритма kd-tree nearest neighbor search.
4. Исключить «плохие» соответствия используя метод RANSAC [6].
5. На основе оставшихся соответствий между парами дескрипторов найти преобразование одного множества точек в другое как решение уравнения в матричной форме Ax=B, где A и B — множества точек, x — искомое преобразование.
Инвариантное к масштабированию преобразование, позволяющее извлекать особенности, основывается на построении пирамиды гауссианов (Gaussian) и разности гауссианов (Difference of Gaussian, DoG). Инвариантность относительно масштаба достигается за счет нахождения ключевых точек для исходного изображения, приведённого к разным размерам. Строится пирамида гауссианов: все масштабируемое пространство разбивается на некоторые участки — октавы, причем часть масштабируемого пространства, занимаемого следующей октавой, в два раза больше части, занимаемой предыдущей. При переходе от одной октавы к другой делается ресэмплинг изображения, его размеры уменьшаются вдвое. За ключевые точки, принимаюся пиксели, которым в пирамиде DoG соответствует экстремум как внутри уровня, так и между соседними уровнями (точнее говоря, эти точки проходят две дополнительные проверки и только после этого могут считаться ключевыми). Пример найденных ключевых точек SIFT показан на рисунке 8.

Рис. 8. Ключевые точки SIFT
Дескрипторы FPFH (Fast Point Feature Histograms) основаны на дексрипторах SPFH (Simplified Point Feature Histograms), которые для каждой пары точек ps и pt вместо исходных 12 параметров (2 трёхмерных координат и 2 нормалей к поверхностям) позволяют получить 4 параметра 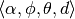 , где первые 3 значения — углы, показанные на рисунке 9, а d — расстояние Евклида между точками ps и pt.
, где первые 3 значения — углы, показанные на рисунке 9, а d — расстояние Евклида между точками ps и pt.
Рис. 9. Параметры дескриптора SPFH
Значение дескриптора FPFH точки pq расчитывается через значения дескрипторов SPFH k соседних точек SPSH(pk).
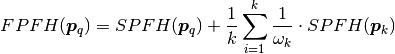 (1)
(1)
где ωk — весовая функция, вычисляемая через обратную величину расстояния между точками pq и pk.
Поиск соответствий «каждый с каждым» слишком ресурсоёмкий, поэтому выполняется поиск соответствий с помощью вычисленных дескрипторов FPFH между парами ближайших в пространстве точек из разных множествах. Поиск пар ближайших точек осуществляется с помощью метода kd-tree nearest neighbor search. С помощью метода Random Sample Consensus найденные соответствия разделяются на «хорошие» (inliers) и «ложные» (outlier). Для найденных «хороших» соответствий в матричной форме решается уравнение Ax=B, где в строчках матриц A и B представлены все найденные «хорошие» соответствия и с помощью сигнулярного разложения находится матрица преобразования x.
Полученное последовательное совмещение нескольких множеств точек, полученных с разных кадров (двух, десяти, тридцати) показано на рисунке 10.
|
|
|
|
|
2 кадра |
10 кадров |
30 кадров |



Рис. 10. Трёхмерная модель лица, полученная совмещением множеств трёхмерных точек.
Литература:
1. URL: http://pointclouds.org/
2. Timothy F. Cootes, Gareth J. Edwards, and Christopher J. Taylor, Active Appearance Models // IEEE transactions on pattern analysis and machine intelligence, vol. 23, no. 6, june, 2001 г.
3. Alexandru Telea, An Image Inpainting Technique Based on the Fast Marching Method. // Journal of Graphics, GPU, and Game Tools 9 1, 2004 г., стр. 23–34
4. David G. Lowe, Distinctive image features from scale-invariant keypoints // International Journal of Computer Vision, 60, 2, 2004 г., стр. 91–110
5. URL: http://pointclouds.org/documentation/tutorials/fpfh_estimation.php
6. Ruwen Schnabel Roland Wahl Reinhard Klein, Efficient RANSAC for Point-Cloud Shape Detection // The Eurographics Association and Blackwell Publishing, vol. 0, no. 0, 2007 г.
