





Введение
Существует достаточно широкий спектр алгоритмов детектирования объектов на изображении. Один из самых эффективных — это алгоритм адаптивного усиления AdaBoost. К достоинствам этого алгоритма можно отнести результативность распознавания, высокую скорость работы и простоту реализации.
AdaBoost (сокращение от Adaptive Boosting) — алгоритм усиления классификаторов, путем объединения их в комитет. Суть алгоритма заключается в комбинировании слабых классификаторов в один финальный, более мощный. В процессе обучения финального классификатора акцент делается на эталоны, которые распознаются хуже, т. е. выбирается классификатор, который лучше идентифицирует объекты, неверно распознанные предыдущим классификатором, в этом и заключается адаптивность алгоритма, в процессе обучения он подстраивается под наиболее сложные объекты [1].
Фактически, алгоритм адаптивного усиления осуществляет только отбор классификаторов и их комбинирование.
На эталонное изображение накладывается один из классификаторов, затем вычисляется сумма значений пикселей в белой области и чёрной области и отнимается от первого значения второе. На выходе получаем обобщённую характеристику анизотропии (неодинаковости свойств среды) участка изображения.
На основе отобранных классификаторов строится каскад. Каждый последующий элемент каскада имеет более жёсткие условия успешного прохождения, чем предыдущий (используется больше классификаторов), тем самым до конца доходят только самые правильные [2].
Реализация алгоритма
На практике будет использована реализация данного алгоритма из библиотеки OpenCV. В библиотеке имеются модули для работы с каскадным классификатором, его детектирования и обучения [5]. Есть два модуля для тренировки каскадов opencv_traincascade и opencv_haartraining, а также модули для обучения opencv_performance и opencv_createsamples.
Модуль opencv_createsamples применяется для создания учебного набора положительных и тестовых образцов в формате *.vect.
Модуль opencv_performance может быть использован для оценки качества классификаторов, но только для обученных opencv_haartraining. Он использует коллекцию различных изображений, запускает классификатор и сообщает производительность, т. е. количество найденных объектов, количество пропущенных объектов, количество ложных срабатываний и другую информацию [4].
Для обучения необходимо собрать образы. Есть два типа образов: негативные и позитивные. Негативные образы соответствуют отсутствию объекта на изображении. Положительные образы соответствуют изображениям с обнаруженными объектами. Набор негативных образов должен быть подготовлен вручную, а множество положительных образов создаётся с помощью модуля opencv_createsamples.
Один из образов будет являться объектом поиска. Тогда большое множество позитивных образов создаются из данного объекта изображения, изменениями интенсивности объекта, случайными вращениями, а также размещением объекта на произвольном фоне.
Практическая часть
Изначально данный алгоритм разрабатывался и применялся в области разработки алгоритмов для распознавания лиц, но ничего не мешает обучить алгоритм поиску других предметов: объектов на медицинских снимках, машин, запрещённых объектов на рентгеновских снимках в аэропорту и т. д.
Нашей задачей является поиск объекта (Рис. 1) на изображениях (Рис. 2).

Рис. 1. Объект поиска

Рис. 2. Изображения для поиска
В работе все цветные изображения переводятся в grayscale, иначе количество инвариантов слишком велико.
Объект может иметь разный цвет (± 50 от исходного цвета), случайное местоположение на изображении, разный размер, разный угол наклона (в пределах 90°).
Создание обучающей выборки
Первый шаг при тренировке каскадов — создание обучающей выборки.
Изначально было заготовлено 500 изображений размером 1920×1200, одно эталонное изображение размером 150×150 и файл negative.dat со структурой:
images/image0.jpg ...
images/image1.jpg ...
...
images/image499.jpg ...
Модуль opencv_createsamples был запущен со следующими параметрами:
-vec C:\ positive.vect -bgC:\ negative.dat -img C:\images\bg.jpg -num 500 -w 1920 -h 1200 -bgcolor 0 -bgthresh 0 ... -show
В зависимости от указанных параметров, модуль берёт эталонный объект и применяет к нему различные деформации (размер, угол наклона и т. д.).
На выходе получаем файл positive.vect, содержащий положительные образы (Рис. 3).
В данном примере количество положительных образов равно 500, но в реальных задачах следует ориентироваться на объём в районе 10000.

Рис. 3. Положительные образы
Создание каскада
Когда обучающая выборка создана, подготовлены 500 негативных образов и столько же позитивных, переходим к созданию каскада классификаторов. Для этого используем модуль opencv_haartraining.
Запускаем модуль со следующими параметрами:
-data C:\training-vec C:\ positive.vect -bgC:\ negative.dat -npos 500 -nneg 500 -nsplits 2 -w 20 -h 24 -mem 1536 -mode ... -maxfalsealarm 0.5
Алгоритм обучения, при должном подходе, может длиться от 1 до 7 дней. Для данного эксперимента, обучение длилось 1 день.
На выходе получили xml-файл, который можно подгружать в исходный код программы.
Тестирование каскада
После того, как каскад был создан, тестируем его, используя модуль opencv_performance. Для этого генерируем изображения по принципу, описанному в части Создание обучающей выборки, тем самым создавая проверочную выборку.
Запускаем модуль с нужными параметрами и как итог получаем следующий результат (Рис. 4):
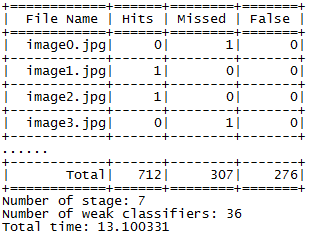
Рис. 4. Информация, полученная после тестирования каскада
Заключение
Прежде всего, следует отметить время, которое потребовалось для обработки 1500 изображений из тренировочной выборки, на обработку одного изображения затрачивалось не более 13 мс. С учётом времени, затраченного на обучение каскада (1 день) и количества изображений в обучающей выборке (1000 изображений), результат тестирования вполне удовлетворительный. В реальных задачах необходимо учитывать, что объём обучающей выборки должен быть от 10000 изображений, а время обучения от 3 дней. Результаты работы алгоритма представлены далее (Рис. 5).

Рис. 5. Результат работы алгоритма
Литература:
1. AdaBoost [Электронный ресурс].
2. URL: http://en.wikipedia.org/wiki/AdaBoost
3. Introduction to Adaptive Boosting [Электронный ресурс].
4. URL: http://www.csie.ntu.edu.tw/adaboost.pdf
5. A Short Introduction to Boosting [Электронный ресурс].
6. URL: http://cseweb.ucsd.edu/IntroToBoosting.pdf
7. Classification and Prediction Using Adaptive Boosting [Электронный ресурс]. URL: https://msdn.microsoft.com/en-us/magazine/dn166933.aspx
8. Opencv documentation [Электронный ресурс]. URL: http://docs.opencv.org/
