





С каждым годом увеличивается количество информации, хранящейся в электронном виде. Вводится электронный документооборот в организациях и на предприятиях, студенты в учебных заведениях сдают курсовые и дипломные работы в электронном виде. В связи с этим появляется необходимость в использовании удобных автоматизированных поисковых систем.
Автоматизированная поисковая система (АПС) — система, состоящая из персонала и комплекса средств автоматизации его деятельности, реализующая информационную технологию выполнения установленных функций [1].
Основная цель любой поисковой системы — поиск информации, удовлетворяющей запросу пользователя. Необходимо в результате поиска ничего не потерять, то есть найти все документы, относящиеся к запросу, и не найти ничего лишнего.
Примерами АПС являются системы поиска Google, Яндекс, Rambler, системы поиска плагиата. В основном данные системы рассчитаны на поиск файлов, документов, хранящихся в их базах данных. Кроме того, такие системы не раскрывают свои алгоритмы работы.
Проблема поиска сходства также встает при работе сайта частных объявлений. Жизнеспособность такого сайта зависит от количества размещенных на них объявлений. Поэтому, чтобы привлечь клиентов, вводится услуга бесплатных объявлений. Данные объявления можно подавать неограниченное количество с одного аккаунта сроком на двадцать восемь дней. Сообщения на вершине списка обладают большей популярностью, поэтому для продвижения своей услуги некоторые пользователи подают свое объявление в разные промежутки времени, удерживая его выше других. Это вредит как другим пользователям (по запросу они могут получить много одинаковых записей, что оттолкнет их к конкурентам), так и сайту (при потере клиентов он утратит свою жизнеспособность).
Поэтому поставлен вопрос о поиске дублирующихся объявлений, которые подаются на сайт частных объявлений. Дублирующееся объявление — это не только копия ранее поданного, но и объявление, отличающееся от исходного одним-двумя неключевыми словами. Данная задача преследует цель не заполнения базы данных повторяющейся информацией, и предоставление пользователям, которые ищут какую-либо услугу, разные объявления.
Решением на поставленный вопрос не может быть ни одна из приведенных выше АПС, так как, во-первых, область поиска каждой из них — своя база данных; во-вторых, алгоритмы работы скрыты и защищены; в-третьих, необходим поиск по строке, а не по тексту (то есть в данном случае имеют место разные параметры критериев поиска таких, как полнота, точность); в-четвертых, в случае поиска дублирующихся объявлений работа ведется с шаблонизированными строками, что, несомненно, необходимо использовать.
Поэтому целью исследования является определение и разработка механизма поиска сходства шаблонизированных строк, в основу работы которого заложены алгоритмы нечеткого поиска дубликатов
Для достижения поставленной цели были поставлены и решены следующие задачи:
1. Анализ существующих систем поиска
2. Анализ алгоритмов определения строк-дубликатов
3. Определение алгоритмов, подходящих для работы с шаблонизированными строками
4. Определение методов работы с алгоритмами
5. Построение автоматизированной системы поиска
Несмотря на повсеместное использование АПС, для локальной задачи поиска сходства строк решения не найдено: системы поиска плагиата — почти все являются платными продуктами со скрытым программным кодом, а такие общедоступные системы, как Google или Яндекс, сложно применить к частной задаче. И, конечно, алгоритм работы ни одна из широко используемых систем не разглашает.
Далее сформируем список алгоритмов нечеткого поиска, которые могут быть использованы в поиске строк-дубликатов: алгоритм шинглов и алгоритм Вагнера-Фишера.
Алгоритм шинглов — алгоритм, разработанный для поиска копий и дубликатов рассматриваемого текста в веб-документе, мощный инструмент, призванный бороться с проявлениями плагиата в интернете.
Уди Манбер в 1994 г. первым в мире выразил идею поиска дубликатов, а в 1997 г. Андрей Бродер оптимизировал и довел её до логического завершения, дав имя данной системе — «алгоритм шинглов».
Этапы, которые проходит текст, подвергшийся сравнению:
- канонизация текста;
- разбиение на шинглы;
- вычисление хэшей шинглов;
- случайная выборка 84 значений контрольных сумм;
- сравнение, определение результата.
Канонизация текста приводит оригинальный текст к единой нормальной форме. Текст очищается от предлогов, союзов, знаков препинания, HTML тегов, и прочего не нужного «мусора», который не должен участвовать в сравнении. В большинстве случаев так же предлагается удалять из текста прилагательные, так как они не несут смысловой нагрузки.
Шинглы (англ. чешуйки) — выделенные в тексте подпоследовательности слов. Необходимо из сравниваемых текстов выделить подпоследовательности слов, идущих друг за другом по 10 штук (длина шингла). Выборка происходит внахлест, а не встык. Таким образом, разбивая текст на подпоследовательности, получается набор шинглов в количестве равному количеству слов минус длина шингла плюс один (кол_во_слов — длина_шингла + 1).
Принцип алгоритма шинглов заключается в сравнении случайной выборки контрольных сумм шинглов (подпоследовательностей) двух текстов между собой.
Проблема алгоритма заключается в количестве сравнений, ведь это напрямую отражается на производительности. Увеличение количества шинглов для сравнения характеризуется экспоненциальным ростом операций, что критически отразится на производительности [2].
Алгоритм Вагнера-Фишера использует одну из наиболее часто применяемых метрик — расстояние Левенштейна. Расстояние Левенштейна (также редакционное расстояние или дистанция редактирования) между двумя строками в теории информации и компьютерной лингвистике — это минимальное количество операций вставки одного символа, удаления одного символа и замены одного символа на другой, необходимых для превращения одной строки в другую [3].
Впервые задачу упомянул в 1965 году советский математик Владимир Иосифович Левенштейн при изучении последовательностей 0–1. Впоследствии более общую задачу для произвольного алфавита связали с его именем. Большой вклад в изучение вопроса внес Дэн Гасфилд.
Расстояние Левенштейна и его обобщения активно применяется:
- для исправления ошибок в слове (в поисковых системах, базах данных, при вводе текста, при автоматическом распознавании отсканированного текста или речи).
- для сравнения текстовых файлов утилитой diff и ей подобными. Здесь роль «символов» играют строки, а роль «строк» — файлы.
- в биоинформатике для сравнения генов, хромосом и белков.
Алгоритм Вагнера-Фишера предложен Р. Вагнером и М. Фишером в 1974 году.
Для нахождения кратчайшего расстояния необходимо вычислить матрицу D, используя формулу:
Пусть 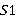 и
и 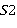 — две строки (длиной
— две строки (длиной 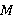 и
и 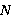 соответственно) над некоторым алфавитом, тогда редакционное расстояние (расстояние Левенштейна)
соответственно) над некоторым алфавитом, тогда редакционное расстояние (расстояние Левенштейна) 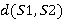 можно подсчитать по следующей рекуррентной формуле
можно подсчитать по следующей рекуррентной формуле
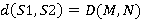 , где
, где
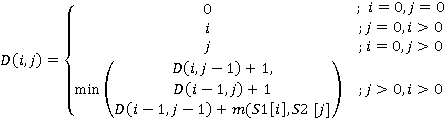 ,
,
где 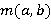 равно нулю, если
равно нулю, если 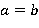 и единице в противном случае;
и единице в противном случае; 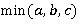 возвращает наименьший из аргументов [4].
возвращает наименьший из аргументов [4].
Далее рассмотрим такое понятие как шаблонизированные строки.
Шаблонизированная строка — строка, атрибуты которой выбираются из списка возможных значений шаблона. Какой шаблон использовать, на сайте частных объявлений, определяется в зависимости от выбранной рубрики. Например, для рубрики «Транспорт» подтянется шаблон с такими атрибутами, как «Марка», «Модель», «Тип кузова» и др., а для рубрики «Работа» — «Должность», «Сфера деятельности», «Отрасль» и т. д. К каждому атрибуту шаблона привязан список всех возможных значений, при выборе которых и сформируется строка.
Исходя из того, что на сайте частных объявлений используются шаблонизированные строки применять алгоритм шинглов в описанной выше последовательности, считаю не совсем подходящим для поставленной задачи: строка объявления — это небольшой текст, который по размерам нельзя сравнить с текстом статьи или текстом html-странички. Поэтому в алгоритм предлагается внести некоторые изменения и реализовать три его вариации:
1. Метод основан на сравнении соответствующих шинглов двух строк. Сначала вычисляется множество 5-символьных шинглов (если в конце строки не хватает символов, берем их с начала). Затем сравниваются полученные шинглы, и по количеству совпавших определяется степень похожести.
2. Второй вариант алгоритма шинглов. Строка объявления — специфическая строка — она состоит из строго определенного набора слов (для объявления пользователь выбирает подходящие слова из предоставленного набора, самостоятельно набирает лишь дополнительную информацию). Для шинглов выбираются слова, соответствующие атрибуты которых участвуют в обеих строках.
3. Метод основан на «шинглировании» логарифмической выборки из исходного множества шинглов, такой, которая оставляет шинглы, делящиеся без остатка на степени небольшого числа. Сначала вычисляется множество всех 2-словных шинглов (слова в конце строки «заворачиваются» на начало). Затем из этого множества отбираются шинглы, делящиеся на степень числа 2.
Для алгоритма Вагнера-Фишера и его вариации отсечения Укконена также принято решение воспользоваться специфичностью строки-объявления: редакционное расстояние будет вычисляться не посимвольно, а поатрибутно.
Результаты исследования будут реализованы в виде модуля (рис.1.).

Рис. 1. Работа модуля поиска сходства
Работа сайта частных объявлений после внедрения модуля будет следующей (рис.2.)
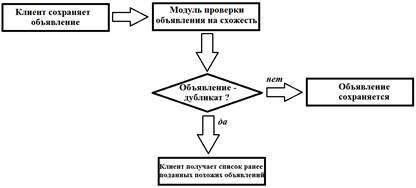
Рис. 2. Алгоритм работы сайта частных объявлений после внедрения модуля
Необходимо отметить, что одной из главных частей работы, является часть, в которой клиенту выдается на обозрение список объявлений, считающихся похожими, то есть ему не просто запретят подавать новое объявление, но покажут причину запрета. Дальше клиенту можно предложить два варианта на выбор, либо он повторяет одно из ранее поданных объявлений, либо, если считает, что список неверен, передает свое новое объявление модератору, который уже сам решит дубликат объявление или нет.
В результате после внедрения модуля сайт приобретет проверку на похожесть подаваемого объявления с ранее поданными, это обеспечит не заполнение базы данных «лишними» строками, пользователи сайта будут видеть только уникальный контент, а те, кто подают объявления, получат удобный сервис по работе с повторяющимися объявлениями.
Литература:
1. Агеева С. П. Автоматизированные поисковые системы // Современные тенденции развития науки и производства: Сб. материалов Международной научно-практической конференции (23–24 октября 2014 года) — в 4-х томах, Том 3, — Кемерово: ООО «ЗапСибНЦ», 2014–164 с. (Сборник)
2. Алгоритм шинглов // Википедия [Электронный ресурс]. — Режим доступа: http://ru.wikipedia.org/wiki/Алгоритм_шинглов
3. Нечёткий поиск в тексте и словаре // Хабрахабр [Электронный ресурс]. — Режим доступа: http://habrahabr.ru/post/114997/
4. Расстояние Ливенштейна // Википедия [Электронный ресурс]. — Режим доступа: http://ru.wikipedia.org/wiki/Расстояние_Левенштейна
