





Основой для современного подсчета запасов полезных ископаемых (ПИ) является цифровая база данных (БД), создаваемая на основе результатов геологоразведочных работах в период оценочных работ или разведки месторождений, а также на стадии эксплуатации. Осуществляется подсчет запасов в соответствии с требованиями и правилами оформления материалов для подсчета запасов месторождений полезных ископаемых, представляемых на государственную экспертизу. При этом рекомендуется использовать программные комплексы, обеспечивающие возможность просмотра, проверки и корректировки исходных данных, результатов промежуточных расчетов, построений, сводных результатов. Графические материалы и модели представляются в виде форматов, выполненных с помощью геоинформационных систем (ГИС) и горно-геологических информационных систем (ГГИС).
Цифровая база данных может быть представлена в формате таблиц MS Excel или MS Access. Включает в себя несколько структурных элементов (таблиц):
Результатов опробования (ASSAY). Формируется из данных химических, пробирных или иных результатов лабораторных исследований, отобранных из керна скважин или иных горных выработок (шурфов, штреков и т.д.);
Координат выработок (HEADER). Содержит координаты устьев скважин и т.д.;
Отметки литолого-стратиграфических границ или контактов (LITHOLOGY);
Данные инклинометрии (SURVEY).
Однако первичная документация до недавнего времени велась, да и отчасти ведется на аналоговых (бумажных) носителях в виде полевых дневников, журналов и планов опробования. Поэтому на начальном этапе создания БД стоит задача перевода этой информации в формат цифровых таблиц. Осуществляется перевод первичной документации посредством сканирования с последующей оцифровкой и вводом полученной при геологоразведочных работах информации. При этом возможны ошибки, а БД с ошибками не может быть использована при подсчете запасов, в частности с применением геоинформационных систем.
В настоящее время применение специализированного ПО позволяет выявить ошибки в инклинометрии, наличие пересекающихся интервалов, соответствие полей в БД, но не способны устранить ошибки при наборе результатов опробования (опечатки, повторения, пропуски и т.д.). Кроме того, такого рода специализированное ПО существует не на всех предприятиях, а с учетом необходимости привлечения специалистов, знающих данные системы, встает необходимость проверки цифровой БД при помощи доступных средств, к примеру, MS Excel.
Проверка БД на пригодность для использования в геоинформационных системах может производиться двумя методами статистическим (1) или перекрестным (2):
После ввода части информации сверяется 10% введенных данных с первоисточниками. Если ошибки встречаются более чем в 10% записей, то снова проверяется уже 50% введенной информации. Если и в этом случае уровень ошибок превышает допустимый, то перепроверяется уже вся введенная информация, а выявленные ошибки тщательно исправляются.
Данные вводятся двумя операторами, независимо друг от друга. Полученные таблицы сортируются и сравниваются. Отличающиеся строки отбраковываются и снова вводятся одновременно двумя операторами, а затем снова сравниваются. Как правило, количество таких операций достигает трех-четырех. Только после достижения полного соответствия информации, она считается принятой, и может использоваться в дальнейшей работе [1, c. 29].
Мы остановимся на рассмотрении перекрестного метода проверки ошибок, так как считаем его наиболее достоверным и позволяющим достичь максимальной сходимости с исходной информацией.
Возможные ошибки при вводе в цифровые таблицы информации, полученной при геологоразведочных работах, можно разделить на две групп:
ошибки, возникающие при ведении документации, в том числе и первичной;
ошибки, возникающие на этапе ввода данных в цифровые табличные формы.
Первая группа ошибок появляется в процессе работы геологической службы на горнодобывающих предприятиях (месторождениях), выявление которых в процессе создания цифровой базы данных зачастую невозможно. Устранение или существенное их сокращение связано с совершенствованием геологической службы, ее материально технической базы и повышением квалификации специалистов.
Вторая группа ошибок во многом связана с человеческим фактором, в процессе формирования цифровой базы данных, при этом выявленные ошибки могут быть устранены в процессе проверки.
Наиболее типичные ошибки при вводе данных, это:
опечатки (изменение порядка или пропуск цифр);
пропуск отдельных значений или строк;
повторные значения или строки.
Для устранения ошибок можно использовать методику, состоящую из нескольких этапов проверки с использованием программного продукта MS Excel, которая позволяет сократить их объем и обеспечить практически 100% сходимость с первоисточником. Рассмотрим методику на примере ввода данных опробования (ASSAY).
1 этап. Ввод результатов опробования производится в две руки независимыми друг от друга операторами в таблицы, структура которых заблаговременно подготовлена и однотипна. Вводятся следующие данные: номер скважины (HOLEID), номер пробы (SAMPLE), интервалы опробования - от (FROM) и до (TO), выход керна в метрах (CORE_M) и результаты анализов. Столбцы - длина интервалов опробования (LENGTH), выход керна в процентах (CORE_%) рассчитываются по формулам 1.1 и 1.2.
[TO]-[FROM] = [LENGTH] 1.1
[CORE_M]*100/[LENGTH] = [CORE_%] 1.2
Использование формул позволяет уже на стадии ввода, выявлять возможные ошибки и своевременно их устранять. Так, к примеру, ошибка в интервале опробования, при вычислении формулы 1.1, может привести к появлению в столбце (LENGTH) значений, резко отличающихся от принятой на месторождении длины интервала опробования; при вычислении формулы 1.2, приведет к появлению выхода керна более 100%.
Кроме того, при вводе данных рекомендуется структурировать исходную информацию, что значительно облегчит и, что важно, уменьшить затраты времени на проверку в процессе 2-го этапа.
2 этап. Введенные данные проверяются путем перекрёстного сопоставления двух полученных таблиц с использованием идентификатора (ID). ID может формироваться из номера выработки (HOLEID) и начала интервала опробования (FROM) (1.3).
[HOLEID] & "_" & [FROM] 1.3
Для избегания случаев путаницы в случаи присутствия в исходной информации повторных номеров скважин следует дополнить ID, к примеру, номером страницы журнала опробования с которого производился ввод.
Таблицы копируются в один документ MS Excel на отдельные листы (рис. 1). Сопоставление производится с помощью функции ВПР, в схожих по ID строках рассчитывается разница значений одной и второй таблиц. В случае если разница не равна 0, при помощи логической функции, ЕСЛИ в ячейке выводится слово ОШИБКА. В этом случае проверяющий, используя исходную информацию, сравнивает данные цифровых таблиц с оригиналами и исправляет ошибки (рис. 2). Таким образом, можно исправить повторные пробы, пропущенные данные, опечатки и т.д.

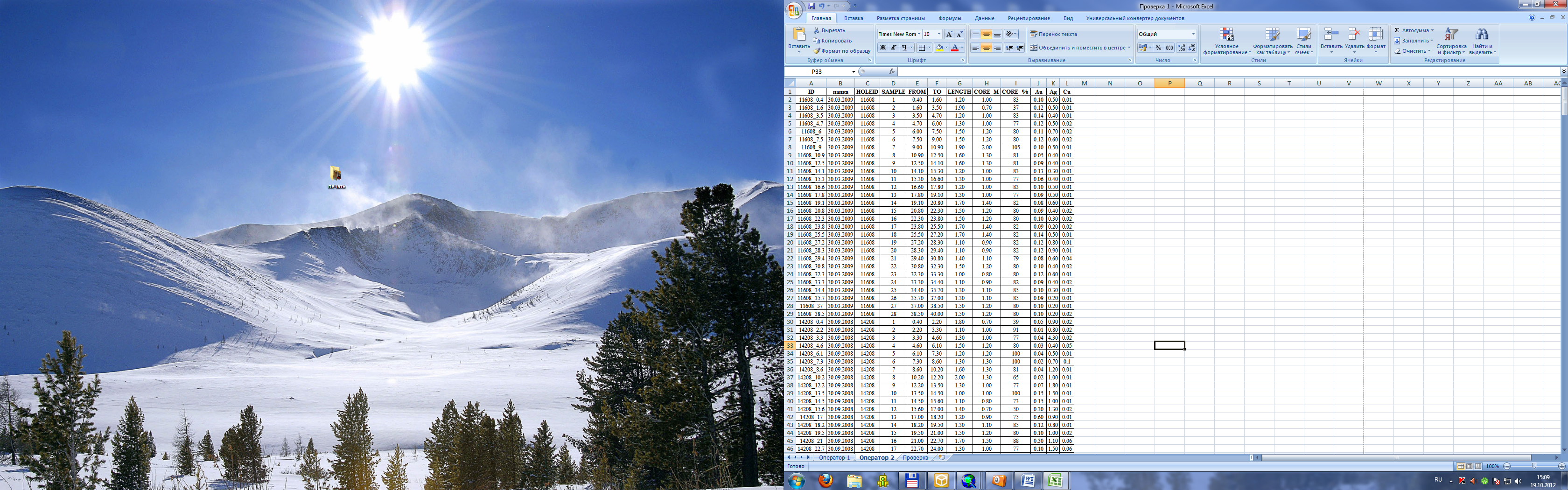
Рис. 1. Таблицы данных опробования, полученные при вводе двумя операторами
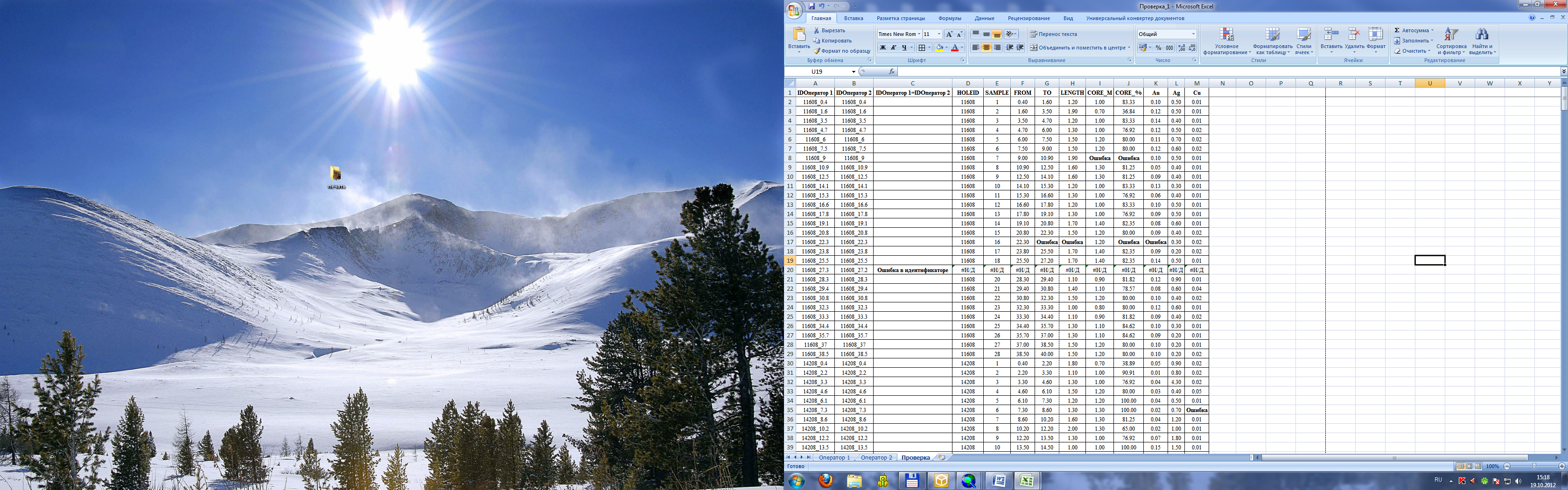
Рис. 2. Проверка на наличие ошибок в таблице 1 и таблице 2 (см. рис. 1)
В завершении проверки производится анализ на присутствие скважин с одинаковыми номерами и в случае их обнаружения, такие данные бракуются, а информация о них высылается или сообщается геологической службе горнодобывающего предприятия.
3 этап. После проверки итоговая таблица сортируется по полям (HOLEID) и (FROM), а данные анализируются на присутствие в опробовании перекрывающихся интервалов или их отсутствие.
Для полной проверки БД в MS Excel проводится сопоставление данных инклинометрии с опробованием и глубиной скважины, выявляются расхождения в глубинах трех таблиц, вносятся соответствующие поправки.
Данная методика проверки подходит для маленьких предприятий, у которых нет возможности приобретения дорогостоящего ПО, позволяющего в автоматической режиме сообщать о имеющихся ошибках, например ГГИС.
Проверенная БД может использоваться для создания блочной модели или для традиционного метода подсчета запасов МПИ.
Литература:
Требования к составу и правила оформления материалов технико-экономических обоснований (ТЭО) кондиций для подсчета запасов месторождений полезных ископаемых, представляемых на государственную экспертизу. М.,2005, с. (Государственная комиссия по запасам полезных ископаемых (ГКЗ) Министерства природных ресурсов Российской Федерации)
Подсчет запасов и геолого-промышленная оценка рудных месторождений. Коган И.Д. М., "Недра", 1971, 296 стр.