





Предварительная обработка речевых сигналов служит различным целям в системах обработки речи. Она включает в себя выделение речи из сигнала, предварительный фильтр сигнала, нарезку сигнала перекрывающимися кадрами, обработку сигнала в окне, спектральное преобразование сигнала и т.д. Из них выделение границы речевого сигнала является важным шагом для таких систем. В работе представлены два метода удаления паузы из речевого сигнала. В первом методе используется уровень кратковременной энергии и число нулей интенсивности сигнала. А второй метод применяется на основе нормального (гауссово) распределения значения отчетов сигнала.
Введение
Выделение речи из исходного сигнала является важным шагом предварительной обработки речевых сигналов. Для вычленения из входного сигнала участков, содержащих только речь, используются следующие характеристики речевого сигнала:
кратковременная энергия речевого сигнала;
число нулей интенсивности (мгновенная частота);
плотность распределения значения отчетов паузы.
Рассмотрим два метода выделения речи на основе этих характеристик.
Кратковременная энергия речевого сигнала и число нулей интенсивности (мгновенная частота)
Кратковременная энергия речевого сигнала и число нулей интенсивности являются основными параметрами речевого сигнала. Параметры речевого сигнала, как правило, быстро меняются с течением времени, поэтому принято снимать их при нарезке речевого сигнала неперекрывающимися кадрами длиной 10–20 мс. Считаем, что сигнал на таком отрезке примерно стационарен (постоянен).
Кратковременная энергия речевого сигнала определяется следующей формулой:
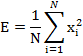
Где N –количество отчетов речевого сигнала,
![]() – значение
i-го отсчета.
– значение
i-го отсчета.
Число нулей интенсивности (мгновенная частота) речевого сигнала определяется следующей формулой:
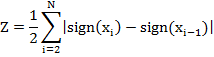
Где
![]() .
.
Кратковременная энергия речевого сигнала и число нулей интенсивности одновременно используются для удаления пауз из входного сигнала. При записи звука первые 150–200 мс речевого сигнала являются паузой. Необходимо вычислить пороги кратковременной энергии и числа нулей интенсивности на отрезке с паузой для сравнения с остальными участками сигнала. Пороги кратковременной энергии и числа нулей интенсивности вычисляются по следующим формулам:
![]()
![]()
Где M – количество первых кадров паузы.
Выполнить вычисление кратковременной энергии и числа нулей интенсивности всех кадров остального участка речевого сигнала. Если эти значения превышают пороги, то кадр соответствует паузе, необходимо удалить его из речевого сигнала. После удаления всех пауз получается результат сигнала без паузы.
Рассмотрим следующий алгоритм.
Шаг 1: Нарезать первые 150 мс речевого сигнала неперекрывающимися кадрами размером 120 (длина кадра 15 мс, количество кадров 10).
Шаг 2: Вычислить кратковременную энергию и число нулей интенсивности всех кадров по формулам.
Шаг 3: Вычислить пороги для кратковременной энергии и числа нулей интенсивности по формулам.
Шаг 4: Накопить следующие отчеты из речевого сигнала в кадр размером 120.
Шаг 5: Вычисление кратковременной энергии и числа нулей интенсивности кадра.
Шаг 6: Если кратковременная энергия больше порога и числа нулей интенсивности меньше порога, то добавить отчеты кадра в результатный сигнал, иначе обновить пороги для кратковременной энергии и числа нулей интенсивности.
Шаг 7: Если конец речевого сигнала, то переход на шаг 8, иначе переход на шаг 4.
Шаг 8: Получить результатный сигнал.
На рис. 1 и 2 показаны исходный и результатный сигнал слова “one” первым методом.
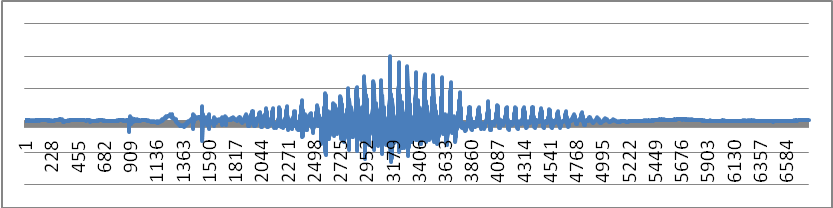
Рис. 1 – Исходный речевой сигнал слова “one”

Рис.2 – Результатный речевой сигналслова “one”первым методом
Нормальное (гауссово) распределение случайной величины
Случайная величина x имеет нормальное распределение, если её плотность распределения определяется зависимостью:
![]()
где μ – среднее значение случайной величины,
σ – нормальное распределение случайной величины.
Среднее значение случайной величины определяется следующей формулой:

Где N – количество случайной величины,
![]() -
случайная величина.
-
случайная величина.
Нормальное распределение случайной величины определяется следующей формулой:
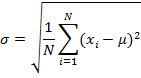
При записи звука первые 200 мс речевого сигнала являются паузой. Значение отчетов паузы оказывается случайной величиной. Плотность распределения значения отчетов паузы используется для выделения речи из входного сигнала. Рассмотрим алгоритм выделения границы речевого сигнала на основе нормального распределения.
Шаг 1: Вычислить среднее значение и нормальное распределение значения первых 1600 отчетов (первые200 мс речевого сигнала)по соответствующим формулам.
Шаг 2: Накопить следующие отчеты из речевого сигнала в кадр размером 80.
Шаг 3: Создать одновременный массив размером 80.
Шаг 4: Вычислить расстояние Махаланобиса от каждого отчета кадра до среднего значения по следующей формуле.
![]()
Шаг 5:Если расстояние больше 3, то добавить единицу в массив (отчет соответствует речи), иначе добавить нуль в массив.
Шаг 6: Вычислить количество нулей и единиц в массиве.
Шаг 6: Если количество единиц больше количества нулей, то добавить единичные отчеты в результатный сигнал, иначе обновить среднее значение и нормальное распределение нулевым отчетом.
Шаг 7: Если конец речевого сигнала, то переход на шаг 8, иначе переход на шаг 2.
Шаг 8: Получить результатный сигнал.
На рис. 3 показан результатный сигнал слова “one” вторым методом.
Рис 3 – Результатный речевой сигнал слова “one” вторым методом
Результаты экспериментальных исследований
В качестве анализируемых использовались речевые сигналы, содержащие числа английского языка. Для оценивания предложен процент правильного выделения речи (ППВ). ППВ вычисляется по следующей формуле:
![]()
Где
![]() – количество отчетов исходного речевого сигнала,
– количество отчетов исходного речевого сигнала,
![]() –количество
отчетов результатного речевого сигнала.
–количество
отчетов результатного речевого сигнала.
Для экспериментальных исследований была надиктована база из 5 слов (числа от “one” до “five”) с произношением диктора.
В таблице 1 показан результат выделения речи двумя методами.
Таблица 1
Результаты экспериментальных исследований
|
|
Первый метод |
Второй метод |
|
“one” |
54,24 % |
41,26 % |
|
“two” |
57,77 % |
32,31 % |
|
“three” |
не выделено |
40,27 % |
|
“four” |
не выделено |
54,90 % |
|
“five” |
59,55 % |
44,42 % |
Из таблицы видно, что метод выделения речи на основе нормального распределения обладает более высоким качеством, чем метод, использующий кратковременную энергию речевого сигнала и число нулей интенсивности.
Заключение
Таким образом, предложена реализация двух алгоритмов к задаче выделения речи из исходного сигнала и проведено её экспериментальное исследование. В результате работы был реализован лучший алгоритм выделения речи – алгоритм на основе нормального распределения.
Литература:
Компьютерное распознавание и порождение речи. [Электронный ресурс]. – Режим доступа: http://speech-text.narod.ru/chap3.html
Корицкий, Д.В. Система распознавания речевых команд. [Электронный ресурс]. – Режим доступа: http://www.nsc.ru/ws/show_abstract.dhtml?ru+130+9365
Нормальное распределение [Электронный ресурс]. – Режим доступа: http://ru.wikipedia.org/wiki/Нормальное_распределение
G. Saha, Sandipan Chakroborty, Suman Senapati, A New Silence Removal and Endpoint Detection Algorithm for Speech and Speaker Recognition Applications.
