





Данная работа посвящена исследованию в области агентных технологий. В работе рассмотрены подходы к разработке алгоритмов планирования поведения агентов. Разработана модель инвариантного поведения агента в среде. Приведены подходы реализации команды агентов-игроков в керлинг в мультиагентной системе.
Введение
Современные реальные задачи часто имеют сходство с видением мира, состоящего из множества взаимодействующих агентов различной природы. Подобная методология является не только весьма перспективным, но и даёт универсальный, мощный и эффективный подход к решению современных задач самой различной природы. Вот некоторые задачи, решение которых возможно с применением мультиагентного подхода: моделирование развития экономики предприятия в условиях конкуренции с другими фирмами; организация поведения группы боевых единиц (например, танков) на поле боя; использование роботов для работы в условиях неблагоприятных и недопустимых для человека; другие задачи, требующие работы интеллектуальных агентов.
1. Агенты. Общие понятия
Агенты являются автономным объектами, их поведение управляется целями, и у агентов есть знания о том, как эти цели достичь [5]. Для реализации своей автономности агенты обладают способностью реагировать на события, принимать и пересматривать решения и взаимодействовать с другими агентами [4]. Задача позиционирующего движения состоит в доставке агента в заданную целевую позицию или состояние [3]. На сегодняшний день актуальным является решение следующих проблем: задача согласующего движения; модель представления данных агентом; алгоритм планирования поведения агентов.
Данная работа посвящена исследованию в области агентных технологий. Целью моей работы является разработка инвариантного алгоритма планирования поведения агентов. Для достижения поставленной цели требуется решить следующие задачи:
- изучить существующие подходы к разработке алгоритмов планирования поведения агентов;
- построение инвариантной модели поведения агента;
- определение требований к алгоритму;
- разработка алгоритма планирования поведения агента в соответствии с составленной моделью.
2. Подходы к реализации алгоритма поведения агентов
В настоящее время существует 2 архитектуры алгоритмов поведения агентов: обобщающая архитектура и трехуровневая архитектура [2]. Обобщающая архитектура представляет собой инфраструктуру для сборки реактивных контроллеров из конечных автоматов. В гибридных архитектурах реакции объединяются с алгоритмическими вычислениями. Одним из видов гибридной архитектуры является трехуровневая архитектура, которая состоит из реактивного, исполнительного и алгоритмического уровней. Реактивный уровень обеспечивает низкоуровневое управление роботом. Исполнительный уровень (или уровень упорядочения) служит в качестве посредника между реактивным и алгоритмическим уровнями. На алгоритмическом уровне вырабатываются глобальные решения сложных задач с использованием методов планирования.
Я считаю, что в любых методах и алгоритмах планирования поведения агентов можно выделить две составляющие: данные, с которыми работает алгоритм, и, собственно, алгоритм. Проблема создания инвариантного алгоритма планирования поведения агентов является неразрешимой в принципе. Почему? Рассмотрим ответ на данный вопрос на примере. Имеется некоторое предприятие в конкурентном сегменте рынка. Его целью является повышение прибыли. Естественно описать практически все возможности предприятия в математической форме и решить классическую задачу с ограничениями. А если в качестве агента будет выступать сложный робот? Общие его действия еще можно будет описать в виде сложной системы уравнений. Но как решать такую сложную систему? Такие вопросы актуальны и для математических наук. Применим к планированию поведения робота механизмы нейронных сетей. При достаточном обучении мы получим хорошо адаптированного к некоторым условиям робота. Но есть ли смысл применять теорию нейронных сетей к экономике предприятия? Ответом будет только «нет», потому как гораздо точнее будут результаты решения математической задачи. Следовательно, алгоритм будет очень сильно привязан к предметной области. Именно поэтому на мой вздляд не стоит разрабатывать некоторый «инвариантый» алгоритм. Поэтому меня заинтересовала возможность создания инвариантной модели поведения агента.
3. Инвариантная модель поведения агента
Как я уже упоминал, у агента есть внутреннее представление о мире и своих действиях. Это представление называется пространство конфигураций или пространство состояний. Модель динамического пространства состояний представлена на рисунке 1. В некоторый момент времени агент будет находиться в определенном состоянии St (State). Агент знает, что среда находтся в состоянии Et (Environment), но знает он об этом не напрямую, а через наблюдаемую информацию Ot (Observation) посредством сенсоров и датчиков. Естественно, эта информация может быть неточной. Кроме наблюдаемой информации из среды агент может получить данные от других агентов Ct (Communication) как локальное подкрепление, целеуказание, уточнение информации о среде и т.п. Базируясь на полученных данных, собственном представлении ситуации в окружающей среде, цели и возможностях агент выполняет некоторое действие At+1 (Action), результат выполнения которого агент «увидит» не раньше, чем в следующий момент времени t. В свою очередь действие агента воздействует не только на внешнюю среду, но и может повлиять на восприятие агента.
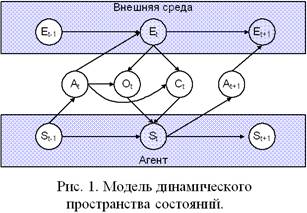 Назовем прогоном rt (run) последовательность состояний среды и действий агента.
Назовем прогоном rt (run) последовательность состояний среды и действий агента. 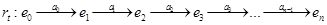 Пусть Rt – множество возможных конечных последовательностей r к моменту времени t. Пусть множество RAct – подмножество Rt, последний элемент которого действие агента. Обозначим множество REt – подмножество Rt, элементы которого оканчиваются состоянием среды.
Пусть Rt – множество возможных конечных последовательностей r к моменту времени t. Пусть множество RAct – подмножество Rt, последний элемент которого действие агента. Обозначим множество REt – подмножество Rt, элементы которого оканчиваются состоянием среды.
Что есть действие агента в среде? Это есть результат «размышлений» агента над последовательностью воспринятых состояний среды и собственных действий (или состояний), выраженный в действии. 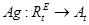 По сути, действия агента в среде есть трансформация состояний среды. Обозначим за Tt (transformation) воздействие агента на среду.
По сути, действия агента в среде есть трансформация состояний среды. Обозначим за Tt (transformation) воздействие агента на среду. 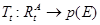 . p(Et) – закон изменения среды в состоянии Et. Формально окружающая среда есть кортеж
. p(Et) – закон изменения среды в состоянии Et. Формально окружающая среда есть кортеж 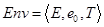 .
.
4. Пример агента. Керлинг
Пусть, например, в роли агента выступает робот-игрок в керлинг. Суть этой зрелищной игры сводится к следующему. Игроки соперничающих команд поочередно запускают по гладкому льду двадцатикилограммовые дископодобные камни, снабженные ручкой, стремясь попасть в центр «дома», образованного в конце ледовой полосы четырьмя концентрическими окружностями диаметром от 6 дюймов (15 см) до 6 футов (182 см). В команду входят четыре игрока – «скип», «первый», «второй» и «вице-скип». Каждый из них выполняет свои собственные обязанности. «Скип» – лидер команды, ее главный стратег и тактик. Во время бросков он стоит в площади «дома», указывая концом, куда именно, с его точки зрения, следует попасть битой. Дело в том, что каждой команде приносят очки только те биты, которые оказались к центру «дома» ближе, чем биты соперников. Поэтому расставить биты своей команды таким образом, чтобы удержать достигнутое преимущество, помешать противнику сделать результативный бросок или толчком своего камня выкатить из «дома» биту противника – дело весьма важное и непростое. Более того, «скип» постоянно оценивает качество льда и на основании этой оценки дает рекомендации игрокам о том, каким способом следует бросать камень, как «подметать». Право выбора очередности броска определяется перед началом игры с помощью подброшенной монеты. Последний бросок имеет определенные стратегические преимущества, поэтому угадавший обычно выбирает «последний камень».
Робот может совершать следующие основные действия: бросок камня в некотором направлении с некоторой начальной скоростью; натирание выбранной щеткой поверхность льда перед камнем. Как упоминалось ранее, в систему входят 2 команды агентов по 4 агента в каждой команде: скип, вице-скип, первый, второй. Каждый агент выполняет определенную роль в команде.
Внешняя среда состоит из ледяного поля для игры со специальной разметкой, описанной выше, шестнадцати камней (по 8 для каждой команды). Камни могут взаимодействовать при соударении. Цель игры – получение максимума очков. Очки считаются по количеству камней, попавших в целевой круг на поле.
Опишем возможные стратегии действий команды агентов. Существуют 2 стратегии действия команды агентов: оборона и нападение. Имеются 3 типа броска камней: защита (расположение камня перед целевыми положениями для предотвращения удара по камням, находящимся в целевых позициях), цель (расположение камня в доме), удар (сильный бросок камня для выбрасывания за пределы мешающихся камней (камни противника в доме, защитники и т.п.)). Команда может выбрать стратегию поведения до начала игры, но так как ситуация в игре меняется динамически и сильно зависит от игры команды противника, стратегию которой команда не знает, стратегия может быть изменена в процессе игры.
Перед каждым ходом скип оценивает игру для выбора цели броска. Возможны следующие варианты:
- если команда опережает противников по количеству очков, то следует применить стратегию защиты и использовать бросок-защитник;
- если команда уступает противнику по количеству очков, то возможно применение двух стратегий:
o стратегия защиты: выполнение броска-защитника, чтобы помешать противнику делать броски-цели и выполнять на следующем ходу атаку;
o стратегия атаки: выполнения броска-удара, чтобы выбить максимальное количество камней противника за пределы дома. Необходимо учесть следующий фактор: если удар по камню противника повлечет за собой выбивание собственных камней, следует сделать бросок-цель и тем самым предотвратить вылет своих камней за пределы дома;
- в случае равенства текущих очков, оценить расположение камней:
o если невозможно сделать бросок-удар таким образом, чтобы перевес очков был в пользу команды, то лучше сделать бросок-защиту или бросок-цель;
o если имеется возможность без потери собственных очков выбросить камень (камни) противника за пределы дома, выполнить бросок-удар.
Естественно, это не все возможные случаи. Подобных случаев может быть бесчисленное множество. Как отличить их? Мной разработан аналитический расчет. Его основа в оценке позиции каждого камня. Оценка заключается в следующем: анализ доступности камня в диапазоне позиций броска. На рисунке 2 показан пример определения диапазона видимости камня с позиции броска в случае перекрывания полного диапазона видимости. Таким образом, оценив доступность камня и его позицию, можно предположить возможный результат выбранного действия. Для примера на рисунке 2 исход броска ясен: камень слева от линии броска отлетит вправо и вполне вероятно будет задет камень слева от линии броска, его скорее подтолкнут к оцениваемому камню.
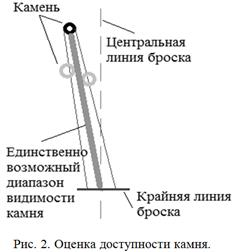 Окончательный выбор действий команды агентов определяется в соответствии со сценарием поведения по цели броска, а также как наибольшая оценка доступности плюс сложность броска (в случае необходимости закручивания бросок считается сложным) в соответствии с выбранным сценарием поведения. Это позволяет выбрать наиболее подходящий вариант броска в текущем положении игры
Окончательный выбор действий команды агентов определяется в соответствии со сценарием поведения по цели броска, а также как наибольшая оценка доступности плюс сложность броска (в случае необходимости закручивания бросок считается сложным) в соответствии с выбранным сценарием поведения. Это позволяет выбрать наиболее подходящий вариант броска в текущем положении игры
Заключение
В результате проделанной работы предложена инвариантная модель поведения агента в среде. Разработана реализация модели в применении к игре керлинг. Так же в настоящий момент разрабатывается агентный подход поиска в базе данных с нечеткими семантическими запросами. Данный подход будет реализован в системе SAP R/3 с целью добавления адаптивного поиска по базе данных. Подходит к завершению реализация системы моделирования мультиагентных систем в системе SAP R/3, которая позволит моделировать полностью игру керлинг для двух команд агентов. Также планируется разработать алгоритм действий боевой машины (например, танка) на поле боя.
Список литературы
1. Vidal, Jos’e M. Fundamentals of Multiagent Systems / Jos´e M. Vidal. – 2007. – 157 с.
