





Алгоритм градиентного бустинга (Gradient Boosting) используется в задачах обучения с учителем. Данный тип задач отличается от задач обучения без учителя тем, что на этапе обучения построенной модели мы имеем метки классов для объектов из обучающей выборки (в задаче классификации), либо числа из множества всех действительных чисел (в задаче регрессии). Обозначим ![]() — объекты обучающей выборки, которые представляют собой вектор конечной размерности, а
— объекты обучающей выборки, которые представляют собой вектор конечной размерности, а![]() — целевая переменная для объекта с индексом
— целевая переменная для объекта с индексом ![]() . Под моделью в задачах обучения с учителем обычно понимают математическую структуру, которая позволяет предсказывать
. Под моделью в задачах обучения с учителем обычно понимают математическую структуру, которая позволяет предсказывать![]() по
по ![]() . Одной из типичных моделей для данного типа задач является линейная модель, в которой предсказанием является линейная комбинация весов элементов объектов обучающей выборки (признаков).
. Одной из типичных моделей для данного типа задач является линейная модель, в которой предсказанием является линейная комбинация весов элементов объектов обучающей выборки (признаков).
![]()
Параметры модели — это переменные, которые участвуют в описании модели и являются ее неопределенной частью. На этапе обучения происходит подбор таких параметров, которые минимизируют функционал качества. Функционал качества состоит из функции потерь (loss) и параметра регуляризации.
![]()
Функция потерь является мерой того, насколько хорошо обученная модель предсказывает целевую переменную на обучающей выборке. Типичными примером функции потерь являются среднекватратичная ошибка (MSE) в задачах регрессии и логистическая функция потерь (logistic loss) в задачах классификации.
![]()
![]()
Параметр регуляризации вводится для того, чтобы построенная модель не переобучалась на обучающей выборке. Основой модели “Экстремального градиентного бустинга” являются наборы классификационных и регрессионных деревьев (CART).).
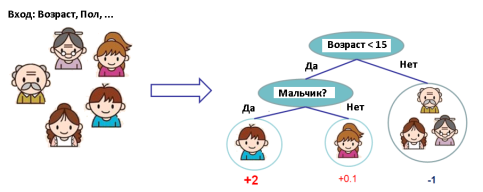
Рис. 1
Рассмотрим работу модели CART на примере классификации того, насколько каждый из членов семью любит играть в компьютерные игры. Мы классифицируем членов семью по различным листьям дерева и назначаем каждому листу числовую метку. Модель CART отличается от модели, построенной на основе решающих деревьев тем, что в CART метки назначаются каждому листу деревьев, что дает лучшую интерпретацию того, как работает классификация в данных задачах. Обычно в моделях используют не одно дерево, а несколько (ансамбль деревьев), так как одно дерево не обладает хорошей обобщающей способностью. Метки, полученные для одних и тех же объектов в разных деревьях, складываются, что дает новую метку для каждого объекта.
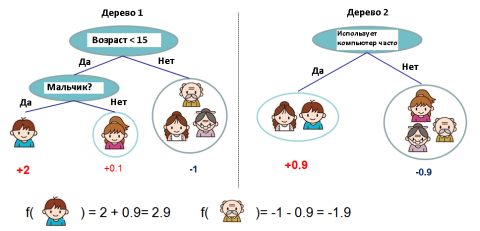
Рис. 2
Если посмотреть на рисунок 2, то можно отметить тот факт, что два дерева дополняют друг друга. Математически это можно записать следующим образом:
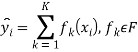
где ![]() — это количество деревьев в модели,
— это количество деревьев в модели, ![]() — функция в функциональном пространстве
— функция в функциональном пространстве ![]() , которое представляет собой набор всех возможных деревьев модели CART. Таким образом, функционал качетва, который необходимо минимизировать в рамках данной задачи имеет вид:
, которое представляет собой набор всех возможных деревьев модели CART. Таким образом, функционал качетва, который необходимо минимизировать в рамках данной задачи имеет вид:
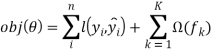
После того как мы определили функционал качества и описали модель необходимо понять, как обучать построенную модель. Решающие деревья обучаются так же, как и другие модели задач обучения с учителем, а именно путем минимизации функционала качества. Пусть мы имеем следующий функционал качества:
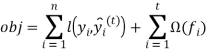
Первым шагом является определение параметров решающих деревьев. Как видно из функционала качества, параметром являются функции ![]() , которые содержат в себе структуру деревьев и меток листьев. Оптимизация введенного функционала качества отличается от задачи традиционной оптимизации, когда можно взять градиент от функции и найти ее минимум методом градиентного спуска. Обучение ансамбля деревьев за один проход является нелегкой задачей. Введем понятие аддитивной стратегии. Зафиксируем, что мы обучили на данный момент, и на каждой итерации будем добавлять одно новое дерево.
, которые содержат в себе структуру деревьев и меток листьев. Оптимизация введенного функционала качества отличается от задачи традиционной оптимизации, когда можно взять градиент от функции и найти ее минимум методом градиентного спуска. Обучение ансамбля деревьев за один проход является нелегкой задачей. Введем понятие аддитивной стратегии. Зафиксируем, что мы обучили на данный момент, и на каждой итерации будем добавлять одно новое дерево.
![]()
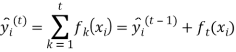
Вопрос состоит в том, какое из деревьев добавлять на каждом шаге. Ответ на этот вопрос очевиден: необходимо добавлять дерево, с учетом которого функционал качества уменьшается. Если рассматривать среднеквадратичную ошибку в качестве функционала качества, она принимает следующий вид:
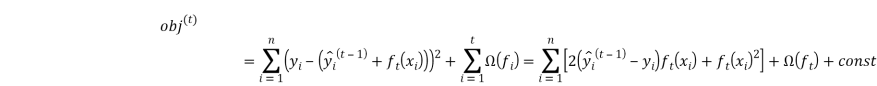
В общем случае, мы применяем разложение в ряд Тейлора функционала качества до второго порядка:
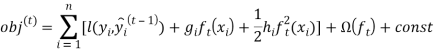
где ![]() ,
, ![]() определяются следующим образом
определяются следующим образом
![]()
![]()
После того, как мы избавимся от всех констант, получаем функцию потерь для шага t. Полученную функцию мы минимизируем для каждого нового дерева, которое добавляется в модель на шаге t.
Рассмотрим работу модели градиентного бустинга, решив задачу прогнозирования сахарного диабета с использованием языка программирования Python и библиотеки XGBoost. Набор данных для обучения, который предоставляет Университет Джонса Хопкинса, состоит из объектов, каждый из которых имеет 8 признаков и одну целевую переменную. Объектами являются женщины в возрасте от 21 года индийского наследия Пима. Признаками объектов являются:
1) Количество беременностей
2) Плазменные концентрации глюкозы в тесте на допустимое отклонение глюкозы
3) Диастолическое артериальное давление
4) Толщина кожи в области трицепса
5) Количество инсулина
6) Индекс массы тела
7) Diabetes pedigree function
8) Возраст
Целевой переменной является метка класса: 0 — прогноз, на предрасположенность к заболеванию сахарным диабетом в ближайшие 5 лет, 1 — прогноз, на не предрасположенность к заболеванию сахарным диабетом в ближайшие 5 лет.
Загрузим наборы данных и подготовим их для обучения и оценки качества с помощью модели XGBoost.
import numpy
import xgboost
from sklearn import cross_validation
from sklearn.metrics import accuracy_score
# load data
dataset = numpy.loadtxt('pima-indians-diabetes.csv', delimiter="«,)
Необходимо разделить столбцы исходного набора данных на обучающую выборку и целевую переменную.
# split data into X and y
X = dataset [:,0:8]
Y = dataset [:,8]
Также необходимо разбить обучающую выборку на две части: первая будет участвовать в обучении модели, а вторая (отложенная выборка) — в оценке качества обученной модели.
# split data into train and test sets
seed = 7
test_size = 0.33
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, Y, test_size=test_size, random_state=seed)
Так как целевая переменная принимает конечное число значений (0 или 1), мы имеем дело с задачей классификации. Для решения подобных задач в библиотеке XGBoost есть класс XGBClassifier, который позволяет решать задачи классификации при помощи метода градиентного бустинга. Метод fit данного класса принимает в качестве входных параметров обучающую выборку и целевую переменную и обучает модель по входным данным.
# fit model no training data
model = xgboost.XGBClassifier()
model.fit(X_train, y_train)
После того как модель обучена, можно делать предсказания по отложенной выборке. Для того чтобы сделать предсказание по отложенной выборке, необходимо ее передать на вход в функцию predict объекта XGBClassifier. Выходным значением функции predict является вектор размерности (1, количество объектов в выборке, которая подается на вход), который содержит в себе вероятности отнесения объекта с индексом![]() , к классу 0. Чтобы получить валидные метки класса (0 или 1) необходимо округлить полученные вероятности до 0 или 1.
, к классу 0. Чтобы получить валидные метки класса (0 или 1) необходимо округлить полученные вероятности до 0 или 1.
# make predictions for test data
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
Для оценки качества построенной модели используется метод accuracy_score из библиотеки sklearn. На вход он принимает полученные предсказания и действительные метки классов, а на выходе мы получаем долю правильно классифицированных объектов.
# make predictions for test data
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
Accuracy: 77.95 %
В итоге мы получили качество 77.95 %, что является хорошим качеством, учитывая тот факт, что мы имеем в наличии небольшой набор данных.
Литература:
1. http://xgboost.readthedocs.io/en/latest
2. Deep Learning (Adaptive Computation and Machine Learning series), Ian Goodfellow, Yoshua Bengio, 2016
3. Python Machine Learning, Sebastian Raschka, 2015.
