





Исследован вопрос выбора среды разработки для RubyonRails проектов. Показано отсутствие готовых полноценных решений. Обосновано преимущество доработки IDENetВeans для формирования готово рабочего места RubyonRails программиста. На примере HAML-плагина раскрыта технология разработки собственных дополнений для IDENetBeans. Описано преимущество полученного полноценного программного решения.
Ключевые слова:RubyonRails, HAML, IDENetBeans, ANTLR, Java, плагин
На сегодняшний день разработка коммерческой информационной системы невозможна без использования фреймворков или аналогичных им программных систем. Для каждого из популярных на сегодняшний день языков построения веб-ориентированных приложений существует целый спектр подобных средств. Например, высокую востребованность имеют следующие фреймворки: ASP.NET MVC Framework для языков программирования семейства .NET (таких, как C#, Visual Basic.NET, JScript.NET), Django для скриптового языка Python, Spring Framework для языка программирования Java, AngularJS для языка JavaScript и другие.
В последнее десятилетие особо активное развитие демонстрирует фреймворк Ruby on Rails [1]. Согласно статистике Австралийского независимого агентства BuiltWith [2], фреймворк Ruby on Rails в той или иной мере лежит в основе десятой части самых посещаемых сайтов Интернета. Работы различных авторов подтверждают популярность данной системы, как за рубежом, так и в нашей стране. Например, перспективы использования Ruby on Rails в своих статьях рассматривают П. Вагстрём (P. Wagstrom) [3] и Д.Ю. Куприянов [4].
Особую популярность данной системы обуславливают три фактора: полноценная реализация MVC (Model-View-Controller) шаблона проектирования, базирование на современном языке программирования Ruby и универсальная поддержка взаимодействия с большинством популярных систем управления базами данных, включая как поддержку реляционных баз данных на уровне объектно-реляционного преобразователя (например, PostgreSQL, Oracle, MySQL и т.д.), так и поддержку NoSQL систем (например, MongoDB).
Системы, базирующиеся на шаблоне проектирования MVC, обычно не ограничены одним языком разработки, а объединяют в своей основе целый пакет языков, начиная с языков разметки и заканчивая языками низкого уровня. В частности, крупное коммерческое Ruby on Rails приложение может включать в себя комбинацию языков SQL, Ruby, С (или C++) на уровне моделей, комбинацию языков Ruby и C (или C++) на уровне контроллеров, и комбинацию целой россыпи языков на уровне представлений (интерфейсной части), в том числе языки: Ruby, ERB, HAML, JavaScript, Sass, CSS, SCSS, CoffeeScript, LaTeX, MarkDown, YAML и т.д. Такое разнообразие программных средств накладывает серьёзные квалификационные требования не только на самих разработчиков, но и на вспомогательные средства разработки. При этом использование несвязанных инструментов, таких как: текстовый редактор, компилятор, отладчик, система контроля версий и т.д., приводит к потерям большого количества времени на переключение между компонентами, и снижению общей эффективности программистов. Оптимизировать процесс реализации проекта позволяет интегрированная среда разработки (IDE).
Сегодня можно выделить ограниченное множество IDE-систем или их близких аналогов, поддерживающих Ruby on Rails. В частности, это бесплатные системы NetBeans от компании Oracle и Aptana Studio (на основе Eclipse), редактор Atom с набором Ruby on Rails плагинов и коммерческая система RubyMine от компании JetBrains. К сожалению, каждая из данных систем имеет ряд недостатков. RubyMine является платной и ориентирована исключительно на Ruby on Rails. Aptana Studio больше не поддерживается на должном уровне. Atom не является IDE в своей основе, что затрудняет работу с ним. NetBeans поддерживает не все современные технологии, так как начиная с версии 7.0 модуль поддержки языка Ruby и фреймворка Ruby on Rails не входит в состав его стандартной сборки, а предоставляется в виде плагина.
С другой стороны, NetBeans является одной из наиболее популярных сред разработки в мире [5]. При этом данная IDE является кросс-платформенной и поддерживает многие языки программирования и веб-технологии, востребованные одновременно с Ruby on Rails в крупных проектах. Причём одной из ключевых особенностей этой среды является возможность написания собственного плагина для добавления ещё не поддерживаемого языка. Всё вышесказанное показывает преимущество использования NetBeans перед другими IDE-системами, но не устраняет её недостатков. Основным из них на сегодняшний день является отсутствие поддержки языка HAML. Разработка данного языкового модуля может значительно повысить востребованность IDE NetBeans в среде Ruby on Rails разработчиков.
Базовые концепции разработки языкового модуля для IDE NetBeans
Для реализации языкового модуля необходимо построить программную реализацию лексического и синтаксического анализаторов [6]. Программная реализация должна быть выполнена на базовом языке IDENetBeans и встроена в полноценный плагин-проект. В следующей части будут раскрыты базовые технологи построения данных компонент, а также рассмотрен процесс их интеграции в единый модуль.
Лексический анализ — это аналитическая обработка входного потока символов для получения потока токенов. Токен представляет собой пару лексема — идентификатор (токена). Лексема — это последовательность символов входного потока, удовлетворяющая шаблону идентификатора токена. Результат работы лексического анализатора является входным потоком для работы синтаксического анализатора.
Синтаксический анализ — это процесс проверки последовательности токенов на корректность их следования в контексте описываемого языка. В случае успешной проверки на корректность синтаксический анализатор строит дерево разбора. Имеется два основных типа синтаксических анализаторов грамматик: восходящие и нисходящие. Нисходящие анализаторы строят дерево разбора сверху вниз, а восходящие снизу вверх. В обоих случаях входной поток сканируется слева направо.
ANTLR как средство анализа
Существуют два способа создания лексического и синтаксического анализаторов: самостоятельное описание алгоритма его работы на языке программирования и автоматическая генерация программного кода на основе формального описания языка с помощью специализированных программных средств. Для написания плагина поддержки языка HAML для NetBeans более приемлема автоматическая генерация анализатора, так как его самостоятельная разработка — процесс излишне трудоёмкий, затраты на который не оправдывают потенциальной выгоды (пользы) от разработанного языкового модуля. В качестве программного средства генерации синтаксического и лексического анализаторов использовался генератор нисходящих анализаторов для формальных языков ANTLR [7]. Такой выбор был сделан по следующим причинам: ANTLR, в отличие от большинства альтернативных продуктов, таких как, например, Flex и Bison, предоставляет возможность генерации обоих анализаторов, и лексического (далее лексера) и синтаксического (далее парсера). Это позволяет использовать одно программное средство для решения обеих задач. Кроме того, одним из возможных целевых языков генерируемого кода ANTLR является язык Java, являющийся основным языком разработки плагины для NetBeans. Не менее важно, что ANTLR является широко используемым программным средством с подробной документацией и большим сообществом.
Для реализации, непосредственно, HAML-плагина был выбран ANTLR версии 3.5.2. На данный момент существует более поздняя версия ANTLR — 4.5.3, но в ней отсутствует поддержка автоматического построения деревьев разбора, что затрудняет её использование для решения поставленной задачи.
ANTLR генерирует код лексера и парсера на основе файла с расширением *.g. Синтаксис подобных файлов довольно прост, что делает их удобными для описания формального языка. Каждый g-файл начинается с ключевого слова grammar, определяющего название грамматики (указывается сразу после него). Название грамматики должно совпадать с названием самого файла. Далее может идти блок опций, начинающийся с ключевого слова options. Доступный для ANTLR версии 3.5.2 ряд опций приведён в таблице 1.
Таблица 1
Опции грамматики для ANTLR версии 3.5.2
|
Опция |
Описание |
|
language |
Целевой язык для генерации. Доступные языки генерации: Java, C/C++, C#, Python, Ruby и другие. При отсутствии данной опции целевым языком является Java |
|
tokenVocab |
Позволяет описывать грамматики лексера и парсера в разных файлах. Опция задает имя грамматики лексера, из которой парсер возьмёт идентификаторы токенов. |
|
output |
Задает тип структуры данных, возвращаемый парсером. Возможные значения: AST или template. |
|
ASTLabelType |
Задает тип возвращаемого парсером дерева разбора. Возможные значения: CommonTree или собственный класс. По умолчанию ANTLR генерирует парсер, возвращающий дерево типа CommonTree. |
|
TokenLabelType |
Задает тип возвращаемых лексером токенов. Возможные значения: CommonToken или собственный класс. По умолчанию ANTLR генерирует лексер, возвращающий токены типа CommonToken. |
|
superClass |
Задает суперкласс для лексического или синтаксического анализаторов. Используется в тех случаях, когда необходимо переопределить стандартные методы класса лексера или парсера. При отсутствии опции лексический анализатор наследуется от класса Lexer, синтаксический анализатор — от класса Parser. |
|
filter |
Предоставляет возможность игнорирования тех конструкций потока символов, которые не определены в описании лексического анализатора. Предпочтительно использовать данную опцию в тех случаях, когда нет необходимости разбирать весь поток символов. При указании filter = true исключена возможность синтаксической ошибки. |
|
rewrite |
Необходим в тех случаях, когда входной поток после работы парсера должен измениться. Значение по умолчанию — false. |
|
k |
Задает ограничение для LL(k)-анализатора на количество токенов, доступных для предварительного просмотра. Опция уменьшает время работы парсера, однако может вызвать его некорректную работу. По умолчанию для предпросмотра доступны все токены, т. е. используется LL(*)-анализатор. |
|
backtrack |
Меняет алгоритм выделения нужной альтернативы в правилах разбора с LL(*)-анализатора, где для однозначного выделения нужной альтернативы поток токенов просматривается вперед на нужное кол-во элементов, на алгоритм с откатами. Возможные значения: true, false. Значение по умолчанию — false. |
|
memoize |
При алгоритме с откатами (backtrack = true) можно включить опцию memoize, которая позволяет запоминать применение правила к определенной позиции, таким образом, одна и та же последовательность токенов не может быть обработана синтаксическим анализатором более одного раза. В некоторых случаях существенно уменьшает время разбора, но требует больших ресурсов памяти. Возможные значения: true, false. Значение по умолчанию — false. |
Пример использования блока options показан на рисунке 1.

Рис. 1. Пример использования блока options
После блока options могут идти блоки @header и @members. В блоке @header располагается код, который будет помещен в начало генерируемого файла. В блоке @members располагается код, который будет помещен в тело классов лексического и синтаксического анализаторов. При помощи конструкции @lexer:: и @parser:: можно задать @header и @members для лексера и парсера раздельно. Пример использования блоков @header и @members показан на рисунке 2.
Блок @rulecatch позволяет заменить стандартное содержимое catch-раздела для каждого правила. Пример использования блока @rulecatch показан на рисунке 3.

Рис 2. Пример использования блоков @header и @members

Рис 3. Пример использования блока @rulecatch
Правила лексического анализатора задаются в верхнем регистре и представляют из себя шаблоны идентификаторов токена. Правила синтаксического анализатора задаются в нижнем регистре и представляют из себя шаблон корректной последовательности токенов. Шаблоны задаются через двоеточие после названия правила, в конце ставится точка с запятой. Их синтаксис во многом основан на регулярных выражениях. При создании плагина использовались конструкции языка ANTLR, показанные в таблице 2.
Таблица 2
Основные конструкции языка ANTLR
|
Обозначение |
Описание |
|
(...) |
Подправило |
|
(...)* |
повторение подправила 0 или более раз |
|
(...)+ |
повторение подправила 1 или более раз |
|
(...)? |
подправило, может отсутствовать или встречаться один раз |
|
{...} |
семантические действия (на языке, использующемся в качестве выходного) |
|
[...] |
параметры правила |
|
{...}? |
условие выполнения |
|
| |
оператор альтернативы |
|
.. |
оператор диапазона |
|
~ |
отрицание |
|
. |
любой символ |
|
= |
присвоение |
Некоторые правила лексера могут начинаться с префикса fragment. Такое правило будет являться вспомогательным и не будет обрабатываться как токен. Пример подобного правила показан на рисунке 4.
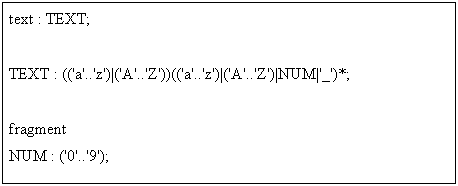
Рис. 4. Пример вспомогательного правила
ANTLR позволяет работать не только с текущим символом или токеном потока, но и предоставляет возможность получения информации о символах и токенах, следующих за ним. Для лексического анализатора существует функция LA(n), которая возвращает символ, стоящий на n позиций впереди текущей. Для синтаксического анализатора есть аналогичная функция LT(n), которая возвращает токен, стоящий впереди текущей позиции на n токенов. Тип возвращаемого данной функцией значения — токен. Для получения идентификатора токена используется функция getType(), для получения лексемы — getText(). Идентификатор токена, находящийся на n позиций впереди текущего, также можно получить с помощью функции LA(n). Тип возвращаемого значения функций LA(n) и LT(n).getType()– целое число, присваиваемое токенам в соответствии с тем, какому правилу они удовлетворяют. Тип возвращаемого значения функции LT(n).getText() — строковая константа (String). Пример использования данных функций показан на рисунке 5.

Рис. 5. Работа с последующими токенами
Завершающей стадией процесса разработки лексического и синтаксического анализаторов является генерация их кода. Она осуществляется командой java (версия может отличаться):
java -jarantlr-3.5.2-complete.jarHaml.g.
После генерации каждому токену будет присвоен числовой идентификатор токена, поэтому понятие идентификатор токена разделяется на два новых понятия: числовой идентификатор и смысловой идентификатор. Последний хранит в себе идентификатор токена, указанный в g-файле.
Этапы создания плагина
На первом этапе происходит создание каркаса плагина. Причём плагин для среды разработки NetBeans создаётся непосредственно в самой среде NetBeans, как проект модуля в категории «Модули NetBeans». После чего в данный проект необходимо добавить поддержку нового типа файла, соответствующего целевому языку. Для языка HAML это файлы с расширением «*.haml». В результате данного действия создаются файлы HamlDataObject.java, HamlTemplate.haml, HamlVisualElement.java, HamlVisualElement.form.
Следующий этап — это создание нового слоя XML, добавление которого повлечёт за собой создание файла layer.xml, в котором позднее будет задана структура проекта.
Третий этап — это подключение ANTLR v.3. Для его корректной работы требуется подключить к проекту последнюю версию соответствующего jar-файла, которая может быть загружена с ресурса [8].
Четвёртый этап — это создание пакета antlr и размещение в нем файлов с кодом грамматики. Кроме того, требуется создать пакет lexer и реализовать в нём классы, показанные в таблице 3.
Таблица 3
Классы пакета lexer
|
Класс |
Описание |
|
HamlTokenId |
Реализует интерфейс класса TokenId пакета org.netbeans.api.lexer. Объекты класса хранят числовой и смысловой идентификаторы токена, а также категорию, к которой он относится. Класс реализует три метода: name(), ordinal(), primaryCategory(), которые возвращают хранимую информацию. Также необходимо создать объект класса Language пакета org.netbeans.api.lexer и присвоить ему “new HamlLanguageHierarchy().language()”. |
|
HamlLanguageHierarchy |
Наследуется от абстрактного класса LanguageHierarchy пакета org.netbeans.spi.lexer. Необходимо реализовать три абстрактных метода: createTokenIds(), createLexer(), mimeType(), а также создать HashMap, в котором ключом является идентификатор токена, а значением — объект класса HamlTokenId. Для получения значения из HashMap по ключу требуется реализовать публичный метод getToken(). |
|
AntlrCharStream |
Реализует интерфейс класса CharStream пакета org.antlr.runtime. В данном классе необходимо реализовать следующие методы: substring(), LT(), getLine(), setLine(), setCharPositionInLine(), getCharPositionInLine(), consume(), LA(), mark(), rewind(), release(), seek(), index(), size(), getSourceName(). Занимается обработкой потока символов. |
|
HamlLexer |
Реализует интерфейс класса Lexer пакета org.netbeans.spi.lexer. В данном классе необходимо реализовать следующие методы: nextToken(), state(), release(). Считывает набор символов и группирует их в токены. |
Последний этап максимально прост и заключается в задании цвета лексем, относящихся к введенным категориям. Для решения данной задачи необходимо создать файл FontAndColors.xml, и установить в нём связи между категориями и цветами.
Заключение
В результате выполненных работ был разработан и успешно протестирован плагин поддержки языка HAML для среды разработки NetBeans. Разработанный плагин в совокупности с другими существующими плагинами поддержки фреймворка Ruby on Rails обеспечивает полноценный инструмент RubyonRails-программиста и позволяет значительно повысить эффективность разработки HAML-программ. Что, в свою очередь, позволяет использовать IDE NetBeans в качестве основной среды разработки веб-приложений на основе фреймворка RubyonRails. Пример работы разработанного плагина показан на рисунке 6.
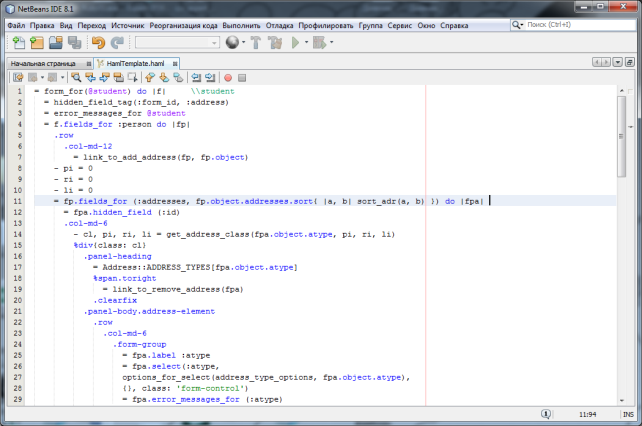
Рис. 6. Пример работы HAML-плагина
Рассмотренные в статье технологии независимы от выбора целевого языка и позволяют разрабатывать собственные языковые модули для широко спектра языков программирования. Что, в свою очередь, позволяет использовать такое мощное средство разработки, как IDENetBeans для большинства современных задач программирования.
Стоит отметить, что используемые программные продукты являются бесплатными и свободными, что позволяет беспрепятственно использовать их в коммерческих продуктах и значительно снижает затраты на разработку в целом.
Литература:
- Hartl M. Ruby on Rails Tutorial: Learn Web Development with Rails. — Addison-Wesley, 2015, — 707 p.
- http://trends.builtwith.com/framework — статистика использования различных фреймворк-технологий в сети интернет по информации компании BuiltWithPtyLtd (дата последнего обращения 07.11.2016).
- Wagstrom, P., Jergensen, C., Sarma, A. A network of rails: A graph dataset of ruby on rails and associated projects // Proceedings of IEEE International Working Conference on Mining Software Repositories, 2013, — pp. 229-232.
- Куприянов Д.Ю., Радыгин В.Ю., Лукьянова Н.В. Применение механизмов RubyonRails для построения информационных систем вуза // Итоги и перспективы интегрированной системы образования в высшей школе России: образование — наука — инновационная деятельность. Труды конференции. — М., МГИУ, 2011 — С237-239.
- http://tagline.ru/ide-rating/ — рейтинг сред разработки (IDE) 2016 по версии кампании tagline (дата последнего обращения 07.11.2016).
- Alfred V. Aho, Monica S. Lam, Ravi Sethi, Jeffrey D. Ullman. Compilers: Principles, Techniques, & Tools, Second Edition, 2007
- Parr, Terence (May 17, 2007), The Definitive ANTLR Reference: Building Domain-Specific Languages (1st ed.), Pragmatic Bookshelf, p. 376
- http://www.antlr3.org/ — официальный сайт ANTLRv.3 (дата последнего обращения 07.11.2016).
