





Одним из возможных путей решения проблемы транспортных заторов крупных мегаполисов является использование аэровидеоизображений транспортных потоков, получаемых, к примеру, с помощью квадрокоптеров на различных дорожных участках.
Подобная измерительная системы предполагает наличие единого центра сбора статистических данных о параметрах транспортных потоков, а также несколько периферийных узлов, действующих одновременно в разных контрольных точках пространства. Очевидно, что в подобной системе, с целью уменьшения объёмов информации, передаваемой между отдельными узлами системы в целом, возникает необходимость компрессии видеоизображений [1].
В ходе исследований было выявлено, что наибольшее влияние на процесс кодирования-декодирования квазистационарных видеоизображений, получаемых с помощью квадрокоптеров, сильнее всего влияет наличие или отсутствие компенсатора движения в структуре видеокодека.
Рассмотрим процесс компенсации движения более подробно [2,3]. Для каждого подвижного блока изображения, на которые оно разбивается предварительно, ищется наилучшее совпадение этого блока в небольшой поисковой области предыдущего кадра (рис. 1).

Рис. 1. Принцип блочной компенсации движения в современных видеокодеках
В качестве критерия поиска обычно служит среднее абсолютное отклонение между сигналами этих блоков:
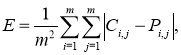
где: E — значение критерия сходства блока и его прогноза; Ci,j, Pi,j — значения яркости пикселов блока и его прогноза; m — размерность блоков в пикселах; i,j — индексы пикселов блока.
При этом может использоваться как одна матрица изображения (например, яркостная), так и несколько матриц. В последнем случае представленная формула усложняется и учитывает дополнительно количеств опорных матриц, используемых для сличения фрагментов изображений.
Поисковая область сканируется попиксельно. По окончанию поиска сигнал найденного прогнозного блока вычитается из сигнала исходного блока. Тем самым формируется разностный остаток для блока. Процесс повторяется для каждого блока, в котором присутствует движение.
Далее, разностные остатки (имеющие малые абсолютные значения по уровню), а также векторы смещения блоков, передаются декодеру. Тот, в свою очередь, по вектору смещения сразу определяет положение прогнозного блока в предыдущем кадре и выполняет обратную операцию сложения сигналов пришедшего декодированного разностного остатка и сигнала прогнозного блока, на который указывает вектор смещения, и так для всех подвижных блоков (признаки движения блоков также передаются декодеру).
В ходе исследований был предложен и проверен ряд методов, учитывающих наилучшие достижения в области видеокодирования со спецификой рассматриваемой прикладной задачи. При проведении сравнительного анализа различных моделей видеокодеков использовался один и тот же кадровый поток из 10 кадров разрешением 800×400 пикселов в системе Y,Cr,Cb с одним яркостным и двумя цветоразностными сигналами.
В качестве базовой модели был выбран видеокодек формата MPEG-4 базового профиля. В качестве показателей эффективности работы каждой модели видеокодека использовались три параметра: время кодирования- декодирования T, объём кода кадрового потока V, а также качество декодированного изображения (оно характеризовалась ошибкой декодирования изображения E, которая, в свою очередь рассчитывалась как среднее абсолютное отклонения между видеосигналами кодируемого и декодированного кадровых потоков)
Результаты исследования этой базовой модели подтвердили, что процесс компенсации движения является наиболее времязатратным (рис. 2). Стоит отметить, что на процесс кодирования-декодирования десятка изображений, данная исходная модель потратила примерно полторы минуты.
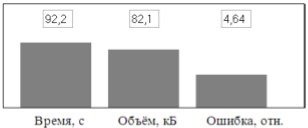
Рис. 2. Результаты моделирования работы видеокодека с применением компенсации движения
Далее была проверена также модель, из которой компенсатор движения был исключен вообще. По сути, все 10 изображений здесь кодировались как фотографии, по отдельности друг от друга. Результаты анализа такой модели приведены ниже (рис. 3).
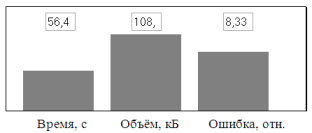
Рис. 3. Результаты моделирования работы видеокодека без применения компенсации движения
Судя по экспериментальным данным, сразу можно отметить, что время, затраченное на кодирование-декодирование без компенсатора движения сразу уменьшилось почти вдвое, но зато, вследствие квазистационарного характера входных изображений, объём кода возрос, а качество изображения сильно ухудшилось.
Таким образом, возникла необходимость разработки комбинированных методов, учитывающих специфику рассматриваемой задачи.
В этой связи, был предложен метод, который может использоваться для кодирования изображений, начиная с того момента, когда на приёмной стороне сформирован фон и начат процесс распознавания асфальтового покрытия. В данном случае модель кодировала только половину изображения, ту, которая содержит проекцию асфальтового покрытия.
Анализ соответствующей модели кодека показал, что время обработки и объём кода, как и ожидалось, сократились примерно наполовину от исходных значений, а качество изображения осталось примерно на том же уровне (рис. 4).
Рис. 4. Результаты частичной компрессии изображений
Далее, был также предложен метод, который можно применять для кодирования изображений уже непосредственно во время статистического анализа, то есть тогда, когда начинают распознаваться прямоугольные контуры проекций автомобилей. В этом случае, компенсатор движения отсутствует вообще, кодируются только части изображений, заключённые внутрь указанных прямоугольников, а на приёмной стороне декодированные проекции накладываются на уже имеющийся к этому моменту времени фон изображений.
Результаты анализа модели кодека, использовавшей такую контурную компрессию, свидетельствуют о сокращении времени кодирования и объёма кода на порядок (рис. 5).
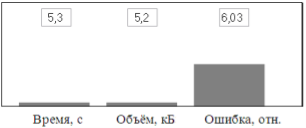
Рис. 5. Результаты контурной компрессии
Наконец был также предложен метод на тот случай, если на приёмной стороне требуется знать только координаты автомобилей, но совсем не обязательно видеть на экране сами автомобили. В этом случае в качестве кодов передаются только координаты прямоугольников автомобильных проекций, а также индексы автомобилей. Естественно, что при таком «слепом» подходе время кодирования и объём кода для соответствующей модели кодека снова значительно уменьшились (рис. 6). В поле ошибки на указанном рисунке стоит прочерк, так как изображения автомобилей здесь не передаются (а значит, и сравнивать нечего).
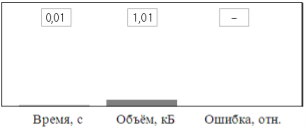
Рис. 6. Результаты численно-контурной компрессии
Таким образом, преимущество совместного использования архитектуры современного видеокодека со спецификой работы методики статистического анализа транспортных потоков было подтверждено экспериментально.
Литература:
- Ричардсон Я. Видеокодирование. Н.264 и МРЕG-4 — стандарты нового поколения. — М.: Техносфера, 2005. — 368с.
- Минаков Е. И. Калистратов, Д. С. Режимы формирования кадровых прогнозов в компенсаторах движения видеообъектов / Е. И. Минаков, Д. С. Калистратов // Известия ТулГУ. Технические науки. Вып.11 Ч. 2. Тула: Изд-во ТулГУ, 2012. С. 188–193.
3. Патент на изобретение № 2552139. Способ компенсации движения в цифровых динамических видеоизображениях / Минаков Е. И., Калистратов Д. С. Приоритет от 16.12.2013, опубл. 29.04.2015.
