





При анализе социальных сетей важно и необходимо рассматривать распространение информации в сети. При возникновении какого-либо события (появление новинки на рынке, политические действия и другое) информация о нем начинает распространяться в социальной сети в разных местах. Она может появиться в разных группах, в записях отдельных агентов сети. Чаще всего такая информация не связана между собой ссылками и находится в разных местах. Необходимо отыскать все «каналы» распространения информации о событии, чтобы оценить какую аудиторию охватило данное событие, кого оно заинтересовало и т. д. Для выполнения поставленной задачи выберем исходное сообщение, характеризующее какое-либо событие, следующим шагом определим ключевые слова и фразы данного сообщения. Далее проведем поиск сообщений по ключевым словам и фразам. Затем необходимо провести классификацию найденных сообщений и проверить их схожесть с исходным. Классификация может осуществляться полностью вручную, либо автоматически с помощью созданного набора правил или с применением методов машинного обучения [1].
Извлечение ключевых слов ифраз
Наиболее простым методом извлечения ключевых слов является построение множества кандидатов ключевых слов путем ранжирования всех словоформ или лексем по частоте. Задается некоторый уровень ключевых слов, далее выбираются наиболее часто употребляемые лексемы в документе. Данный метод рассматривался в работах Г. П. Луна [2] и является первым методом автоматического извлечения ключевых слов. До сих пор актуален и достаточно распространен, что объясняется его простой реализации.
При подсчете частоты употребления ключевого слова учитываются все его словоформы в тексте. Все слова документа нормализуются к одной форме, как правило, к основе или лемме. Для нормализации используется морфологический анализ слов. При морфологическом анализе происходит определение характеристик слова на основе того, как это слово пишется. Морфологический анализ не используется информация о соседних словах. Автоматический морфологический анализ является достаточно сложной задачей.
При статистических подходах к извлечению ключевых слов используются простые эвристические алгоритмы, чаще всего нормализующие словоформу к ее квази-основе, отсекая от словоформы определенное количество букв. Такие алгоритмы называют стемминг-алгоритмами, наиболее известным из которых является стемминг-алгоритм Портера [3]. Нормализованные словоформы ранжируются по частоте и те из них, чья частота выше заданного порога, считаются ключевыми. Ключевые слова, как правило, выдаются в усеченном виде квази-основ. Статистические методы извлечения многокомпонентных ключевых слов в качестве необходимого этапа построения множества кандидатов включают вычисление n-грам [4]. N-грамма представляется собой последовательность из n слов. Данный подход подразумевает частоту встречаемости последовательности из n слов в тексте, а не просто частоту встречаемости отдельного слова.
Преимуществами чисто статистического подхода являются универсальность алгоритмов извлечения ключевых слов и отсутствие необходимости в трудоемких и времязатратных процедурах построения лингвистических баз знаний. Несмотря на указанные преимущества статистических методов извлечения ключевых слов, чисто статистические методы часто не обеспечивают удовлетворительного качества результатов. При этом область их применения ограничена языками с бедной морфологией, такими как английский, где частотность словоформ одной лексемы велика. Чисто статистические модели извлечения ключевых слов, удовлетворительно работающие, например, на материале английского языка, не пригодны для естественных языков с богатой морфологией, в частности, для русского языка, где каждая лексема характеризуется большим количеством словоформ с низкой частотностью в каждом конкретном тексте [5].
Для повышения корректности автоматического извлечения ключевых слов, статистический метод дополняется одной или несколькими лингвистическими процедурами (морфологическим, синтаксическим или семантическим анализом). Такие методы могут требовать или не требовать корпусов текстов (подобранная и обработанная по определённым правилам совокупность текстов, используемых в качестве базы для исследования языка).
Для использования методов, требующих корпус текстов, необходимо определять предметную область. Данная задача является достаточно трудоемкой и требует наличия большого объема корпуса текстов. Если же предметную область выбирать вручную, для использования таких алгоритмов также необходимо заранее построить корпусы текстов по заданным тематикам, что также является нетривиальной задачей. Сами методы основаны на машинном обучении, являются более точными, но затраты времени на обучение достаточно велики (байесовский методы, использование нейронных сетей). В дальнейшем будут рассмотрены алгоритмы, не требующие корпус текстов.
Метод Кена-Баркера относится к методам, не требующим корпус текстов [6], включает поиск в тексте документа базовых именных групп (БИГ) с использованием морфо-синтаксического анализа на основе словарей и вычисление релевантности БИГ. Ключевыми считаются именные группы с показателем релевантности выше заданного порога.
Метод извлечения ключевых именных фраз, разработанный С. О. Шереметьевой [7] для английского языка, не требует наличия корпуса текстов, предусматривает построение множества кандидатов посредством вычисления всех n-грам документа и фильтрацию этого множества с помощью правил удаления n-грам, не являющихся именными фразами, и вычисления релевантности «уцелевших» n-грам-именных групп.
Существуют методы выбора ключевых слов на основе теории графов. Например, метод описанный в работе Д. А. Усталова [8] состоит в построении взвешенного графа, вершинами которого являются лексемы-кандидаты в ключевые слова, а дуги взвешены в соответствии со степенью близости кандидатов вершин. Выборка словосочетаний проводится на основе вершин, имеющих наибольший вес.
Для дальнейшей работы было выбраны два метода, указанные в работах К. Баркера [6] и Д. А. Усталова [8]. Оба метода имеют научное обоснование и кроме статистических методов, основываются на методах морфологического разбора слов. Выбор ключевых слов проводился из трех первых предложений статьи «Методы и модели автоматического извлечения ключевых слов» [5].
Алгоритм, описанный в работе К. Баркера, начинается с того, что из текста удаляются все неинформативные части. Для каждого слова в тексте проводится графематический и морфологический анализ [1]. В ходе обработки отбрасываются все знаки препинания, союзы, частицы, междометия и другие части речи, не несущие для нас смысловой нагрузки. Оставшиеся слова приводятся к «нормальной» (начальной) форме и подсчитывается частота их упоминания. Самые часто упоминаемые слова будем считать ключевыми. Для примера был взят следующий текст «Ключевые слова — это одно- и многокомпонентные лексические группы, отражающие содержание документа. Автоматическое извлечение ключевых слов представляет собой необходимый этап обработки текста в таких важных приложениях как системы автоматического информационного поиска, аннотирования, реферирования и т. д. Однако, несмотря на достаточно большое количество исследований, автоматическое извлечение ключевых слов представляет собой проблему, которая до сих пор не решена. Проблематичным является автоматическое извлечение многокомпонентных ключевых слов, особенно, если делается попытка автоматически извлечь определенные типы лексических групп, например, именные группы» [5]. Результат извлечения ключевых слов указан в таблице 1.
Таблица 1. Ключевые слова и частота их упоминания
|
Ключевое слово |
Частота упоминания (%) |
|
автоматический |
10.0 |
|
ключевой |
10.0 |
|
слово |
10.0 |
|
извлечение |
7.5 |
|
группа |
7.5 |
|
представлять |
7.5 |
|
многокомпонентный |
5.0 |
|
лексический |
5.0 |
Ключевыми фразами будем считать пары и тройки слов, наиболее часто встречающиеся в тексте. Для извлечения ключевых фраз соберем массив, состоящий из соседних пар и троек слов. Аналогичным способом проведем анализ на частоту упоминания таких фраз в тексте. Исходя из предположения о том, что не согласующиеся словосочетания встречаются в тексте реже, чем согласующиеся, будем считать, что полученный набор часто встречающихся фраз является семантически верным. Результат извлечения ключевых фраз указан в таблице 2.
Таблица 2. Ключевые фразы и частота их упоминания
|
Ключевая фраза |
Частота упоминания (%) |
|
ключевой слово |
3.67 |
|
автоматический извлечение |
2.75 |
|
лексический группа |
1.83 |
|
извлечение ключевой слово |
1.83 |
|
автоматический извлечение ключевой |
1.83 |
|
слово представлять |
1.83 |
|
извлечение ключевой |
1.83 |
|
ключевой слово представлять |
1.83 |
Дальше применим к данному тексту алгоритм, основанный на теории графов. Необходимо построить граф ![]() , где
, где ![]() — множество слов,
— множество слов, ![]() — множество связей между ними. Выполнить упорядочивание его вершин и провести составления словосочетаний из вершин, имеющих наибольший вес. В качестве
— множество связей между ними. Выполнить упорядочивание его вершин и провести составления словосочетаний из вершин, имеющих наибольший вес. В качестве ![]() можно принять множество всех уникальных лемм исходного текста, леммами так же будем считать все слова, кроме отброшенных в ходе обработки всех знаков препинания, союзов, частиц, междометий и других частей речи. Множество
можно принять множество всех уникальных лемм исходного текста, леммами так же будем считать все слова, кроме отброшенных в ходе обработки всех знаков препинания, союзов, частиц, междометий и других частей речи. Множество ![]() строится путём последовательного сканирования текста заданным окном из
строится путём последовательного сканирования текста заданным окном из ![]() слов. На каждой итерации для пары слов вычисляется величина связи
слов. На каждой итерации для пары слов вычисляется величина связи ![]() , зависящая от расстояния между словами:
, зависящая от расстояния между словами:
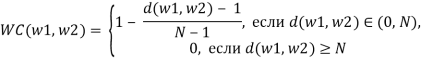
где ![]() слова,
слова, ![]() расстояние между словами,
расстояние между словами, ![]() размер окна. Слова, для которых величина
размер окна. Слова, для которых величина ![]() принимает нулевое значение, не включаются во множество вершин графа. Вычисление величины WC основано на предпосылке, что между двумя соседними словами часто существует семантическое отношение. Чем выше
принимает нулевое значение, не включаются во множество вершин графа. Вычисление величины WC основано на предпосылке, что между двумя соседними словами часто существует семантическое отношение. Чем выше ![]() , тем ниже вероятность существования такого отношения. После тестирования алгоритма на нескольких текстах было найдено оптимальное значение параметра
, тем ниже вероятность существования такого отношения. После тестирования алгоритма на нескольких текстах было найдено оптимальное значение параметра ![]() .
.
После вычисления весов ребер, необходимо провести ранжирование вершин графа. В качестве веса будем использовать величину TextRank – это значение стационарного распределения случайного блуждания для каждой вершины с учетом весов ее ребер[9].
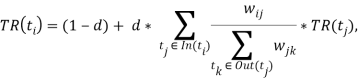
где
Далее необходимо составить множество кандидатов в ключевые слова ![]() . Проведем ранжирование графа на основе вычисленного значения TextRank и отбросим вершины графа, с меньшим весом. Количество отброшенных элементов равняется
. Проведем ранжирование графа на основе вычисленного значения TextRank и отбросим вершины графа, с меньшим весом. Количество отброшенных элементов равняется ![]() количества элементов множества
количества элементов множества ![]() , где
, где ![]() множество всех уникальных лемм исходного текста. Полученный граф изображен на рисунке 1, а результат извлечения ключевых слов отражен в таблице 3.
множество всех уникальных лемм исходного текста. Полученный граф изображен на рисунке 1, а результат извлечения ключевых слов отражен в таблице 3.
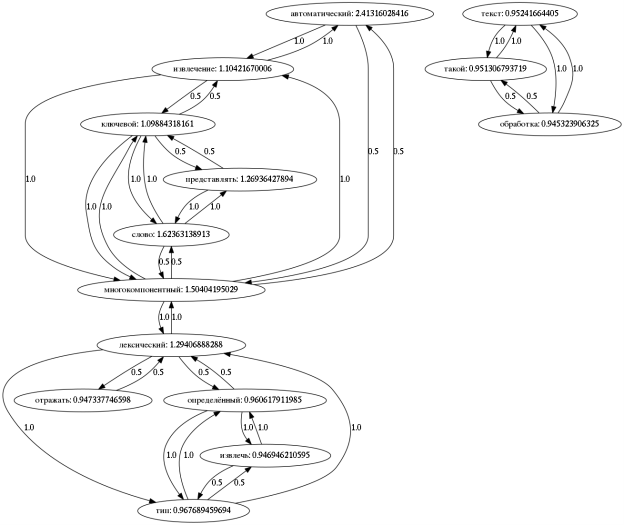
Рис. 1. Граф ключевых слов, выбранной статьи
Таблица 3. Ключевые слова, отобранные из ранжированного графа
|
Ключевое слово |
TextRank |
|
автоматический |
2.41 |
|
слово |
1.62 |
|
многокомпонентный |
1.50 |
|
лексический |
1.29 |
|
представлять |
1.27 |
|
извлечение |
1.10 |
|
ключевой |
1.10 |
|
тип |
0.97 |
|
определённый |
0.96 |
Далее проводится составление словосочетаний. Обходим вершины графа и присоединяем соседнюю вершину, с которой имеем наибольший вес ребра. Словосочетания также сортируются по величине TextRank, для словосочетания она принимается равной сумме всех весов вершин, входящих в него. Полученные словосочетания показаны в таблице 4.
Таблица 4. Ключевые фразы, извлеченные на основе теории графов
|
Ключевая фраза |
TextRank |
|
автоматическое извлечение многокомпонентных лексические типы определенные извлечь |
9.19 |
|
слов представляет ключевых |
3.99 |
|
текста в таких обработки |
2.85 |
Исходя из полученных результатов, можно сделать вывод, что оба алгоритма справились со своей задачей. Алгоритм, основанный на теории графов, более точно определил ключевые слова и составил словосочетания. Для текстов объемом до 1 тысячи слов оба алгоритма срабатывают менее чем за 1 минуту. Для больших текстов (более 200 тыс. слов) статистический алгоритм показывает лучшие результаты по скорости работы. Для примера был взят текст объемом в 300 тыс. слов. Статистический алгоритм обработал текст за 1 минуту 6 секунд, а алгоритм использующий TextRank сработал за 20 минут. Распространяемая информация в сети, чаще всего, не превышает нескольких тысяч символов, поэтому алгоритм, использующий TextRank, можно считать оптимальным.
Классификация документов
Результат поисковой выдачи не всегда может быть точен, в разных системах существуют разные алгоритмы и они не являются совершенными. Поэтому перед тем как добавлять в базу результат поиска необходимо провести обработку полученных данных. Встает задача обнаружения нечетких дубликатов [11]. Необходимо отфильтровать полученные данные и получить документы с высокой степенью повторения искомой информации. В работах [1,11] рассмотрено несколько алгоритмов по классификации текстов и обнаружению дубликатов. В исходной задаче имеется первоначальный документ, с которым необходимо сравнивать остальные документы. Сравнение необходимо проводить попарно только с исходным текстом, т.к. если в автоматическом режиме добавлять в коллекцию найденные документы существует вероятность «расширить» границы поиска и получить в итоге схожие по тематике документы, но не относящиеся к первоначальной теме. Из рассмотренных алгоритмов для задачи сравнения двух документов подходят MD5, TF, TF*IDF, TF*RIDF, Megashingles и Log Shingles. Алгоритмы MD5, Megashingles и Log Shingles подходят для выявления полного совпадения, поэтому при их применении мы получим слишком малую выборку документов. В ходе исследования были протестированы алгоритмы TF, TF*IDF, TF*RIDF.
Алгоритм TF каждому слову ставит в соответствие количество его упоминаний в документе, далее сортируем по частоте и алфавиту.
Алгоритм TF*IDF работает следующим образом. По всей коллекции строится словарь, ставящий каждому слову в соответствие число документов, в которых оно встречается хотя бы один раз (![]() ) и определяется средняя длина документа (
) и определяется средняя длина документа (![]() ). Затем строится частотный словарь документа и для каждого слова вычисляется его «вес»
). Затем строится частотный словарь документа и для каждого слова вычисляется его «вес» ![]() по формуле Okapi BM25 с параметрами
по формуле Okapi BM25 с параметрами ![]() и
и ![]() [12]:
[12]:
![]()
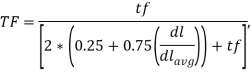
![]()
где ![]() частота слова в документе,
частота слова в документе, ![]() длина документа,
длина документа, ![]() средняя длина документа в коллекции,
средняя длина документа в коллекции, ![]() число документов в коллекции,
число документов в коллекции, ![]() число документов в коллекции, содержащих данное слово.
число документов в коллекции, содержащих данное слово.
Основная идея RIDF (Residual IDF) [13] состоит в сравнении двух способов подсчета количества информации (в смысле определения К. Шеннона), содержащейся в сообщении о том, что данное слово входит в некоторый документ (по меньшей мере один раз). Первый способ, статистический, это обычный IDF = -log(df / N). Второй способ, теоретический, основан на модели распределения Пуассона, предполагающей, что слова в коллекции документов распределяются случайным и независимым образом, равномерно рассеиваясь с некоторой средней плотностью. В этом случае соответствующее количество информации равно ![]() , где
, где ![]() суммарная частота слова в коллекции. Тогда,
суммарная частота слова в коллекции. Тогда,
![]()
показывает прирост информации, содержащейся в реальном распределении слова в коллекции по сравнению с равномерно случайным пуассоновским, т.е. ценность слова. Другими словами значимые слова должны быть распределены неравномерно среди относительно небольшого числа документов, а бессодержательные будут равномерно рассеяны по всей коллекции.
Исходя из результатов работы алгоритма извлечения ключевых слов, был отправлен запрос к поисковой системе. Для исследования возьмем первые 6 вариантов поисковой выдачи, на 1 месте оказался исходный документ, поэтому его мы исключим из выборки, т.к. мы знаем, что данные алгоритмы покажут 100% совпадение. С помощью алгоритмов были получены первых 6 ключевых слов, далее были вычислены их сигнатуры (контрольные суммы, полученные алгоритмом CRC32). После вычисления последовательности сигнатур проведем анализ их совпадения. В таблице 5 указан процент совпадения найденного документа с исходным текстом.
Таблица 5. Поиск нечетких дубликатов.
|
№ документа |
TF (%) |
TF*IDF (%) |
TF*RIDF (%) |
|
1 |
16.67 |
0 |
0 |
|
2 |
83.33 |
0 |
66.67 |
|
3 |
83.33 |
0 |
16.67 |
|
4 |
66.67 |
0 |
16.67 |
|
5 |
66.67 |
0 |
0 |
Алгоритм TF*IDF не подходит для решения исходной задачи, т. к. он учитывает редкие слова и отбрасывает самые часто употребляемые. Алгоритмы TF и TF*RIDF выявили совпадения, но более точные результаты показал алгоритм TF*RIDF. Алгоритм TF выбрал тексты на основании частотного словаря и включил в коллекцию документы далекие по смыслу от исходного. Последний алгоритм TF*RIDF в данной ситуации показал себя наиболее хорошо, поэтому в дальнейшей работе планируется использовать именно его.
Заключение
В ходе исследования были выбраны алгоритмы для извлечения ключевых слов и классификации документов. Все они выполняются за короткое время, поэтому могут использоваться в дальнейшей работе. С помощью данных алгоритмов можно решать следующие задачи:
— поиск распространения сообщений в сети;
— классификация информации распространяемой в социальных сетях;
— поиск агентов, чье мнение совпадает;
— поиск сообществ, которые распространяют однородную информацию.
Решение данных задач может быть применено в маркетинге: поиск клиентов, поиск центров распространения информации, определение направлений распространения информации. Так же данные задачи могут быть актуальны для сферы информационной безопасности: поиск дубликатов, поиск нелицензионных материалов и другое.
Литература:
- Большакова Е. И., Клышинский Э. С., Ландэ Д. В., Носков А. А., Пескова О. В., Ягунова Е. В. Автоматическая обработка текстов на естественном языке и компьютерная лингвистика: учеб. пособие — М.: МИЭМ, 2011. — 272 с.
- Luhn H. P. A Statistical Approach to Mechanized Encoding and Searching of Literary Information. IBM Journal of Research and Development. 1957, vol. 1, no. 4, pp. 309–317.
- Porter M. F. An Algorithm for Suffix Stripping. Readings in Information Retrieval. Morgan Kaufmann Publishers Inc., 1997, pp. 313–316.
- Jiao H. Chinese Keyword Extraction Based on N-Gram and Word Co-occurrence. Proceeding CISW '07 Proceedings of the 2007 International Conference on Computational Intelligence and Security Workshops. Harbin, 2007. pp. 152–155.
- Шереметьева, С. О. Методы и модели автоматического извлечения ключевых слов / С. О. Шереметьева, П. Г. Осминин // Вестник ЮУрГУ. Серия «Лингвистика». — 2015. — Т. 12, № 1. — С. 76–81.
- Barker K. Cornacchia N. Using Noun Phrase Heads to Extract Document Keyphrases. Advances in Artificial Intelligence. 2000, vol. 1822, pp. 40–52.
- . Sheremetyeva S. An efficient patent keyword extractor as translation resource. MT Summit XII: Third Workshop on Patent Translation. Ottawa, 2009. Pp. 25–32.
- Усталов Д. Извлечение терминов из русскоязычных текстов при помощи графовых моделей. http://koost.eveel.ru/science/ CSEDays2012. Pdf (датаобращения: 30.11.2014). [Ustalov D. Izvlechenie terminov iz russkoyazychnykh tekstov pri pomoshchi grafovykh modeley (Term Extraction by Means of Graph Model from Russian texts). Available at: http://koost.eveel.ru/science/CSEDays2012.pdf (accessed: 30.11.2014)]
- S. Brin, L. Page. The Anatomy of a Large-Scale Hypertextual Web Search Engine, 1998
- Mihalcea, R., Tarau, P. TextRank: Bringing Order into Texts. // Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing. — 2004. — Vol. 4. — № 4. — P. 404–411.
- Зеленков Ю. Г., Сегалович И. В. Сравнительный анализ методов определения нечетких дубликатов для Web–документов // Тр. 9-й Всеросс. научной конф. «Электронные библиотеки:перспективные методы и технологии, электронные коллекции». — Переславль-Залесский: Изд-во ИПС РАН, 2007. С. 166–174.
- S. Robertson, S. Walker, S. Jones, M. HancockBeaulieu, M. Gatford. Okapi at trec-3. The Third Text REtrieval Conference (TREC-3), 1995.
- K. Church, W. Gale. Poisson mixtures. NaturalLanguage Engineering, 1995, 1(2):163–190.
