





В настоящее время в интернете и социальных сетях прослеживается тенденция к передаче и обмену информацией с помощью цифровых изображений. В связи с этим большим спросом пользуются программы, позволяющие среднестатистическому пользователю работать с данными, полученными с изображения.
В данной работе описывается алгоритм распознавания шрифта текста с изображения. Для проведения исследовательской работы была написана программа для мобильных устройств на платформе iOS.
Ключевые слова: компьютерное зрение, распознавание шрифта, контурный анализ, OpenCV, iOS
В настоящий момент развитие цифровых технологий позволяет людям передавать и принимать информацию с большой скоростью. Доступность и развитость современной техники сделало особо распространенным такой вид данных, как цифровые изображения. В связи с этим большим спросом пользуются программы, позволяющие среднестатистическому пользователю получать и работать с данными, полученными с изображения. Эти задачи можно решить с помощью методов цифровой обработки. Первоначально эти методы разрабатывались и исследовались специалистами, работающими в области прикладной математики. Сейчас создано несколько общедоступных библиотек, например OpenCV, позволяющих вести работу с цифровыми данными, однако их использование все еще требует определенного технического образования. Такие библиотеки компьютерного зрения не содержат готовых решений и являются лишь инструментом для создания рабочих алгоритмов.
Алгоритм.
Для распознавания шрифта текста используется методы контурного анализа. Контур буквы или цифры с входного изображения сравниваются с контуром этого же символа в различных шрифтах. Для данной работы первоначально была создана демонстрационная база шрифтов, которая содержит в себе эталонные изображения букв и цифр.
Алгоритм можно поделить на 3 этапа: предобработка изображения, выделение символов текста на изображении и сравнение контуров. Рассмотрим первый этап более подробно:
Предобработка изображения.
- Первым делом входное изображение следует перевести в градации серого. В OpenCV это делается с помощью функции cvtColor().
- Далее используется медианный фильтр, для удаления шумов. Он хорошо справляется с шумами типа «перец и соль», а так же данный фильтр улучшает контур ла (рис. 1), что очень важно для дальнейшего контурного анализа. В OpenCV для этого ис
- Используется функция medianBlur().
- Следующий шаг заключает в себе бинаризацию изображения или перевод изображения в черно-белое (рис. 2) с помощью функции thresholdMat(). Бинаризация проводится по пороговому значению яркости пикселя, которое равняется 127.

Рис. 1. Фильтрация шумов

Рис. 2. Бинаризация изображения
Выделение символов.
На данном этапе происходит выделение каждого символа в отдельное изображение.
- С помощью детектора границ Кэнни, реализованного в OpenCV в виде функции Canny(), на изображении выделяются границы всех объектов (рис.3).

Рис. 3. Выделение границ
- Затем с помощью функции findContours(), можно получить контуры объектов в виде набора точек с координатами. Имея набор точек для каждого контура можно определить наименьший прямоугольник, который будет содержать область внутри контура. Найти прямоугольник можно с помощью функции boundingRect() (рис. 4).

Рис. 4. Выделение контуров
Прямоугольник будет опять же представлен в виде набора точек его контура. Используя эту информацию, выделяем на начальном изображении контур каждого прямоугольника и сохраняем внутреннюю область в виде нового изображения (рис. 5).

Рис. 5. Выделенные объекты
Сравнение контуров.
Контур каждого символа сравнивается с контуром этого же символа в различных шрифтах с помощью функции сomputeDistance() из библиотеки OpenCV. Принцип работы функции следующий: на вход подается два контура, а на выходе численное значение. Чем больше число, тем меньше похожи контура. В основе алгоритма лежит сравнение точек контуров между собой (рис. 6).

Рис. 6. Сравнение контуров
Отыскиваются похожие точки и строится гистограмма различий, по которой считается расстояние. Подробная реализация алгоритма, заложенного в основе функции computeDistance() описана в статье Belongie S., Malik J., Puzicha J. «Shape matching and object recognition using shape contexts» [1].
Рассмотрим результаты полученные при использовании функции computeDistance().  Для примера были взяты изображения трех символов в семи различных шрифтах: Arial, Calibri, Cambria, Candara, JavaneseText, MongolianBaiti, TimesNewRoman (рис. 7–9).
Для примера были взяты изображения трех символов в семи различных шрифтах: Arial, Calibri, Cambria, Candara, JavaneseText, MongolianBaiti, TimesNewRoman (рис. 7–9).
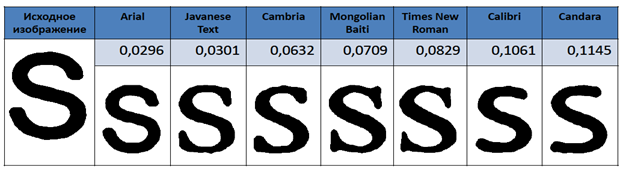
Рис. 7. Результаты для буквы S
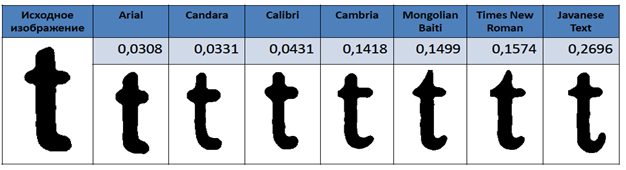
Рис. 8. Результаты для буквы t
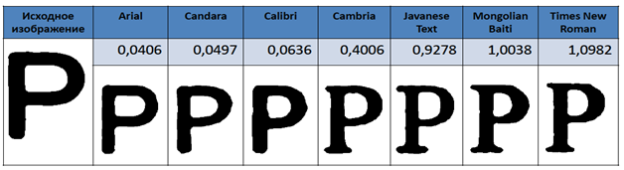
Рис. 9. Результаты для буквы P
На рисунках 7–9 показано, как меняются значения функции computeDistance() от шрифта к шрифту. Не вооруженным глазом видно, что похожие буквы имеют близкие выходные значения функции, и как эти значения увеличиваются с при добавлении различных элементов на букву. Например, буква P имеет характерные засечки в шрифтах Cambria, JavaneseText, MongolianBaiti, TimesNewRoman. Можно наблюдать, что выходное значение делает большой скачок при переходе от шрифта Calibri к Cambria.
Определение шрифта.
Процедура сравнения с эталонными изображениями в различных шрифтах производится для каждого символа. Первые три наилучших шрифта, т. е. имевшие наименьшие выходные значения функции computeDistance(), получают от 1 до 3 баллов соответственно. После того, как контуры всех символов будут сравнены, выбираются три шрифта с наибольшими баллами. Именно эти шрифты выбираются, как наиболее похожие с шрифтом текста с входного изображения.
Выводы.
В ходе экспериментов было установлено, что функция computeDistance() дает достаточно точные результаты и чувствительна только к качеству входного изображения и эталонного изображения символа. К сожалению, существует один значимый недостаток — время работы. Так как сравнение контуров идет попиксельно, при хорошем входном изображении контуры могут достигать размерности от 250 до 500 пикселей. Неоднократный перебор такого массива требует большой вычислительной мощности.
Для исследований данный алгоритм был реализован в виде мобильного приложения для устройств на платформе iOS. Тестирование велось на устройстве iPhone 5s. Его характеристики: 2-ух ядерный процессор AppleA7 64-bit, 1.3 Гц, 1GbRAM. На данном устройстве распознавание шрифта текста на изображении (рис. 1) заняло около 10 секунд.
Литература:
- Garcia G. B., Suarez O. D., Aranda J. L. E. Learning Image Processing with OpenCV. ISBN-13: 978–1-78328–765–9. Birmingham: Packt Publishing, 2015. 319 p.
- Belongie S., Malik J., Puzicha J. Shape matching and object recognition using shape contexts // IEEE Transactions on Pattern Analysis and Machine Intelligence. 2002. Vol. 24. No 4. P. 509–522.
- Dawson-Howe K. A Practical Introduction to Computer Vision with OpenCV. John Wiley&Sons Ltd, 2014. 235 p.
- Suzuki S, Abe K. Topological Structural Analysis of Digitized Binary Images by Border Following // CVGIP. 1985. Vol. 1. P. 32–46.
- OpenCV documentation. htt://docs.opencv.org/.
