





В настоящее время технологии интеллектуальной обработки данных (ИОД) приобретают все большее распространение: они позволяют извлечь из необработанных данных ранее неизвестные, нетривиальные, практически полезные и доступные интерпретации знания и закономерности. Сфера применения ИОД широка: от биологии и медицины до маркетинга и веб-анализа [1]. В системах, в которых каждый день обрабатываются большие объемы данных, выгодно внедрять методы ИОД.
Для интернет-приложений наибольший интерес вызывают две задачи ИОД: кластеризация (выделение групп данных, или кластеров) и ассоциация (поиск закономерностей между связанными событиями). В область применения кластеризации и ассоциации входят задачи [2] сегментации данных, анализа веб-логов, выявления похожих товаров и покупателей, рекомендации товаров, выделения групп пользователей и анализа их поведения. Поэтому актуальным является внедрение методов ИОД для решения этих задач в интернет-приложениях и системах управления веб-сайтами.
Разрабатываемый программный модуль предназначен для реализации функций кластеризации и ассоциации для системы 1С-Битрикс, занимающей лидирующее место на рынке коммерческих систем управления веб-сайтами. Во-первых, поскольку система применяется для разработки и поддержки крупных веб-проектов, таких как корпоративные сайты и интернет-магазины, то разрабатываемый модуль позволит анализировать поведение покупателей на основе предыдущих покупок и делать интересные покупателям предложения и, следовательно, получить дополнительный доход с проектов за счет увеличения конверсии и среднего уровня продаж. Во-вторых, данный модуль позволит улучшить работу с данными веб-сайта за счет их анализа и дополнительной обработки при помощи методов кластеризации и ассоциации.
Среди существующих решений для системы 1С-Битрикс можно выделить сервис рекомендаций RetailRocket и сервис персонализации «1С-Битрикс BigData».
RetailRocket — это сервис персональных рекомендаций, предназначенный для мультиканальной персонализации пользователей интернет-магазина на основе технологии BigData [3]. Сервис дает персональные рекомендации на основе выявленных потребностей пользователей. К недостаткам сервиса относятся необходимость передачи данных во внешний сервис для получения персональных рекомендаций, а также закрытость программного кода.
«1C-Битрикс BigData» — облачный сервис персонализации, являющийся составной частью платформы «1С-Битрикс» [4]. Использование сервиса нацелено на рост интернет-бизнеса путем создания более персонализированных отношений с клиентами. Сервис повышает качество управления, уровень продаж и конверсию в интернет-магазине. К недостаткам сервиса относится закрытость программного кода, невозможность модификации функций сервиса, а также узкая направленность применения сервиса.
В результате сравнения существующих решений, приведенного в таблице 1, сделан вывод о необходимости авторской разработки программного решения в связи с тем, что существующие аналоги не обладают всей функциональностью, необходимой для эффективной обработки данных методами ИОД, предоставляют лишь ограниченный список функций и не позволяют другим разработчикам расширять или изменять этот список.
Таблица 1
Сравнение программного решения саналогами
|
Параметры |
RetailRocket |
1С-Битрикс BigData |
ПМ ФИО |
|
Наличие кластеризации данных |
- |
- |
+ |
|
Рекомендация товаров |
+ |
+ |
+ |
|
Необходимость передачи данных во внешние сервисы |
+ |
- |
- |
|
Открытость кода, возможность модификации/добавления функций |
- |
- |
+ |
|
Тип лицензирования для интернет-магазинов |
От 1700 руб./месяц |
Включен в состав 1С-Битрикс |
От 1000 руб. |
Целью разработки программного модуля является повышение эффективности обработки данных в системе 1С-Битрикс путем внедрения технологии интеллектуальной обработки данных. Такой инструмент позволит эффективнее использовать информацию, находящуюся в базах данных системы 1С-Битрикс, и извлечь из неё дополнительную выгоду.
Для выполнения поиска похожих товаров и пользователей (т. е. кластеризации) в программном модуле реализован алгоритм нечеткой кластеризации с-means. Данные алгоритм позволяет не только выделить кластеры данных, но и определить, с какой вероятностью данные относятся к тому или иному кластеру [5].
Поиск рекомендуемых товаров (т. е. поиск ассоциативных правил) реализован на основе известного алгоритма Apriori, основанного на выделении кандидатов — часто встречающихся наборов данных [6]. Среди наборов данных идет поиск кандидатов, а затем на основе полученных наборов генерируются ассоциативные правила — т. е. правила, связывающие некоторые данные (например, «из того, что купят товар 1, следует, что купят также товары 2 и 3 с вероятностью 60 %"). Достоверностью правила называют вероятность его выполнения.
В состав модуля, помимо классов реализации алгоритмов c-means и Apriori, входят также следующие компоненты:
‒ компонент похожих товаров;
‒ компонент рекомендуемых товаров;
‒ компонент сегментации клиентов;
‒ компонент анализа веб-логов.
Пользовательский интерфейс компонентов похожих и рекомендуемых товаров изображен на рис. 1.

Рис. 1. Пользовательский интерфейс компонентов похожих и рекомендуемых товаров
Для реализации компонента похожих товаров и компонента похожих пользователей применялся алгоритм кластеризации c-means, а для компонента рекомендуемых товаров — алгоритм поиска ассоциативных правил Apriori.
Настройка модуля и его компонентов происходит из панели администрирования системы 1С-Битрикс (рис. 2).
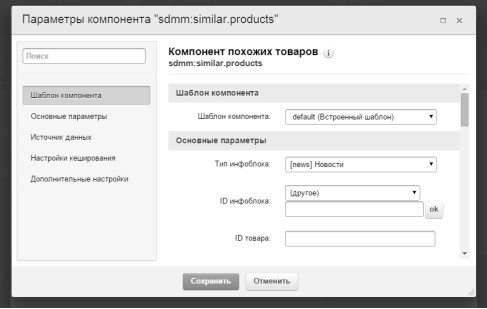
Рис. 2. Пользовательский интерфейс настройки модуля и его компонентов из панели администрирования 1С-Битрикс
Алгоритм предложенного программного решения работает следующим образом. На вход программного модуля поступают данные из компонента. Это могут быть как данные о товарах, так и о покупателях. Далее, в случае выполнения кластеризации, вводятся параметры: число кластеров, степень нечеткости кластеров и минимальный уровень кластеризации. Алгоритм запускает кластеризацию данных, и на выход выдает полученные кластеры данных. Если уровень кластеризации ниже минимального, выдается сообщение об ошибки.
В случае выполнения ассоциации, вводятся параметры: минимальная поддержка правил и минимальная достоверность ассоциативных правил. В полученных наборах данных выделяются кандидаты (т. е. часто встречающиеся наборы), и на их основе генерируются ассоциативные правила. Среди найденных правил выбираются те, чья достоверность превышает минимальную, и результаты возвращаются обратно в компонент. Если таких правил не было найдено, выдается сообщение об ошибке.
Для разработки программного модуля в качестве языка программирования применялся PHP 5.4, среда разработки — NetBeans IDE 8.1.Для отладки и тестирования программного модуля применялся отладчик XDebug.
Далее следует схема алгоритма предложенного программного решения (рис.3).
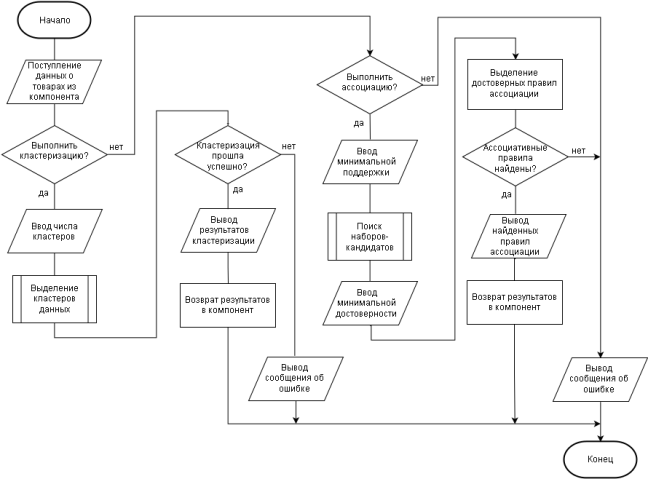
Рис. 3. Схема алгоритма предложенного программного решения
В настоящее время реализована альфа-версия программного модуля, пройдены этапы отладки и тестирования. Программный модуль проходит опытную эксплуатацию.
Литература:
- Коваленко О. С. Обзор проблем и перспектив анализа данных // Информатика, вычислительная техника и инженерное образование. ТТИ ЮФУ, 2011 — № 5 (7).
- Воронцов К. В. Алгоритмы кластеризации и многомерного шкалирования. Курс лекций. МГУ, 2007.
- Сервис рекомендаций RetailRocket // RetailRocket, URL: https://retailrocket.ru/ (Дата обращения: 19.02.2016).
- 1C-Bitrix Big Data // Документация системы 1С-Битрикс, URL: https://dev.1c-bitrix.ru/learning/course/?COURSE_ID=43&LESSON_ID=5282 (Дата обращения: 19.02.2016).
- Мандель И. Д. Кластерный анализ. — М.: Финансы и Статистика, 1988.
- Введение в анализ ассоциативных правил // BaseGroup Labs, URL: https://basegroup.ru/community/articles/intro (Дата обращения: 19.02.2016).
