





Метод автоматической классификации документов взадаче профессионального самоопределения
Макарова Мария Юрьевна, кандидат технических наук, доцент,
Самохина Виктория Михайловна, кандидат педагогических наук, доцент,
Технический институт (филиал) Северо-Восточного федерального университета имени М. К. Аммосова в г. Нерюнгри
Статья посвящена описанию метода латентно-семантического анализа для решения задачи профессионального самоопределения. Рассмотрены наиболее популярные методы автоматической классификации документов и обоснован выбор метода латентно-семантического анализа. Представлены результаты реализации данного подхода в информационной системе поддержки принятия решений по выбору профессии, которые подтверждают целесообразность применения метода латентно-семантического анализа.
Ключевые слова: методы автоматической классификации документов, латентно-семантический анализ, профессиональное самоопределение.
Процесс успешного профессионального самоопределения предполагает получение расширенной информации о профессиях, направлениях подготовки и возможных вакансиях. Для решения данной задачи в статье предлагается метод, который позволит оптимальным образом установить соответствия между компетенциями специалиста и соответствующими направлениями подготовки, тем самым повысив удобство и простоту принятия решения по выбору профессии. Поскольку образовательные стандарты и требования работодателей к квалификации соискателей представляют собой текстовое описание, задача установления соответствий между компетенциями и профессиями может быть решена с помощью программной реализации метода автоматической классификации текстовых документов.
Под классификацией текстовых документов подразумевается процедура присвоения текстам соответствующей тематической категории [6, c. 13]. Задача методов классификации состоит в том, чтобы наилучшим образом выбрать отличительные признаки и сформулировать правила по объединению наиболее похожих данных. Рассмотрим наиболее популярные методы автоматической классификации документов.
1. Иерархические методы предполагают получение древововидной структуры кластеров: первоначально все объекты разбиты на кластеры, объединение наиболее похожих данных продолжается до тех пор, пока все объекты не будут составлять один кластер [8, с. 151]. Для объединения кластеров используются следующие методы: метод ближнего соседа, метод наиболее удаленных соседей, метод Варда, метод попарного среднего. Достоинствами данных методов являются их наглядность, логичное представление информации в виде подчиненной структуры и возможность группировки объектов по максимальному количеству признаков. В качестве недостатков можно отметить малую гибкость и трудоемкость при реализации.
2. Метод квадратичной ошибки (метод k-средних) [6, c. 23] представляет собой последовательность следующих действий: выделяются группы, расположенные на возможно больших расстояниях друг от друга; каждый документ присваивается тому кластеру, чей центр является наиболее близким документу; перевычисляются центры каждого кластера и, если достигнуто условие остановки, алгоритм завершается. Исходные центры кластеров выбираются зачастую случайным образом. Достоинствами метода являются простота, понятность и быстрота использования. В качестве недостатков можно отметить следующие: большая чувствительность к «шумам» (ненужной, лишней информации об объекте), которые могут искажать среднее значение; медленная работа на больших объемах информации; необходимость определения количества кластеров.
3. Методы теории графов заключаются в построении минимального остовного дерева (MST, minimum spanning tree) [1]. Все документы представляются в виде графа, у которого вершины — документы, а дуги –пары документов, вес которых равен расстоянию между их векторными представлениями. После построения минимального остовного дерева ребра с наибольшими длинами удаляются, в результате чего образуются более маленькие деревья, из узлов которых и генерируются кластеры. Преимуществом метода является большее количество информации об объектах по сравнению с иерархическими методами. Основным недостатком данного подхода является сложность обновления кластеров при добавлении нового объекта и необходимость составления остовного дерева.
4. Методы, основанные на концепции плотности заключаются в обнаружении кластеров на основе предположения о том, что внутри каждого кластера наблюдается характерная плотность объектов, которая значительно выше плотности объектов за его пределами. Так исследуются все документы, а те объекты, которые не вошли ни в один кластер, признаются «шумом». Преимуществами данного метода являются способность нахождения кластеров произвольной формы и обнаружения «шума». Среди недостатков можно отметить следующие: необходимость «вручную» подбирать приемлемые значения плотности объектов; ошибочное определение объектов как «шум» или объединение всех объектов в один огромный кластер.
5. Нейросетевые методы (самоорганизующиеся карты Кохонена, алгоритмы теории адаптивного резонанса) представляют собой алгоритмы с обучением, основанные на свойствах человеческого мозга [7]. Данный подход имеет следующие достоинства: высокую эффективность работы с большими объемами данных; способность воспроизводить сложные соотношения; отсутствие ограничений на функцию распределения и типы данных; сохранение работоспособности при наличии пропусков в обучающей выборке. Однако метод нейронных сетей является довольно трудоемким при обучении, и результат использования методов напрямую зависит от точности и правильности реализации обучения.
6. Методы понижения размерности пространства (латентно-семантический анализ, метод главных компонент) основываются на том, что группируются документы, содержащие семантически близкие термины. Главным достоинством данных методов является попытка преодоления синонимии и омонимии за счет использования только статистической информации о множестве документов. Недостатком данного метода являются высокие вычислительные затраты, что становится критичным при больших объемах исходных данных.
Применительно к решению задачи профессионального самоопределения необходим метод, который позволит устанавливать соответствия между профессиями, направлениями подготовки и вакансиями на рынке труда. Объемы информации о профессиях (должностные обязанности) и направлениях подготовки (компетенции) не слишком огромны, а устанавливать соответствия между этими данными необходимо не так уж часто: только при добавлении новой записи в базу данных системы. Важным фактором является минимальная обработка данных, простота в реализации, решение проблемы синонимии в текстах, поскольку необходимо учитывать близкие по смыслу термины предметной области, поэтому был выбран метод латентно-семантического анализа.
Латентно-семантический анализ основан на идее, что совокупность всех контекстов, в которых встречается и не встречается данное слово, задает множество обоюдных ограничений, которые в значительной степени позволяют определить похожесть лексических значений слов между собой [2]. В качестве исходной информации используется матрица, содержащая частоты использования каждого терма в документах. Используя разложение матрицы по сингулярным выражениям, каждый терм и документ представляются в виде векторов в общем пространстве размерности. Для определения степени схожести текстовых документов удобнее всего использовать косинусную меру, основанную на вычислении значения косинуса между двумя векторами документов.
Совершенствование метода латентно-семантического анализа применительно к решению задач профессионального самоопределения заключается в предварительной обработке компетенций (выделении блоков общекультурных и профессиональных компетенций) и нормализации исходной информации и предполагает выполнение следующих шагов:
1. Предварительная обработка исходной текстовой информации: исключение стоп-слов (предлоги, союзы, частицы).
2. Проведение операции выделения основы слова с помощью алгоритма Портера [3], то есть получение термов.
3. Исключение термов, встречающихся в блоке текста один раз.
4. Составление частотной матрицы M, в которой строки являются полученными на предыдущем этапе термами, нулевой столбец представляет собой описание профессии, следующие столбцы — сгруппированные компетенции.
5. Нормализация матрицы M для учета важности каждого терма в том или ином блоке компетенций с использованием меры TF-IDF [4], которая позволяет увеличить вес термов с высокой частотой в пределах конкретного блока и с низкой частотой употреблений в других блоках:
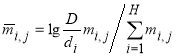 ,(1)
,(1)
где m̅ i,j — элементы полученной нормализованной матрицы ![]()
mi,j — элементы исходной частотной матрицы М, то есть число повторений i-го терма в соответствующем j-м блоке компетенций;
H — общее количество термов;
D — количество блоков компетенций;
di — количество блоков, в которых встречается i-й терм.
6. Реализация сингулярного разложения полученной матрицы ![]() :
:
![]() ,(2)
,(2)
где U— ортогональная матрица;
W— диагональная матрица, которая содержит сингулярные числа;
V— ортогональная матрица, на основе которой делается вывод о степени схожести текстовых документов.
7. Расчет косинусной меры сходства блоков компетенций с нулевым столбцом полученной матрицы V на основе трехмерной декомпозиции. В ходе экспериментов использование первых трех строк матрицы позволяет установить максимальное количество соответствий между исходными элементами, а при большей размерности появляются ошибки в установлении сходств между блоками:
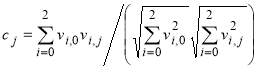 , (3)
, (3)
где cj — коэффициенты сходства компетенций с описанием профессии;
vi,0 — значения нулевого столбца (описание профессии);
vi,j — значения блоков-компетенций.
8. Расчет коэффициента соответствия Kc для компетенций направления подготовки и исходного описания профессии:
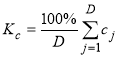 , (4)
, (4)
Максимальное значение коэффициента Kc определяет направление подготовки, наиболее полно соответствующее должностным требованиям к данной профессии и лучше всего подходящее для ее освоения. Для увеличения числа альтернативных решений, которые может принять соискатель в процессе профессионального становления, предложено также устанавливать соответствующие профессиями направления подготовки и вакансии, отличающиеся от максимального значения Kc не более чем на 5 %.
Рассмотренный метод был реализован в информационной системе поддержки принятия решений в процессе профессионального самоопределения [5]. Тестирование разработанного подхода позволило определить направления подготовки и вакансии, соответствующие профессиям рынка труда. В таблице представлен фрагмент полученных результатов:
Таблица 1
Результаты реализации метода латентно-семантического анализа взадаче профессионального самоопределения
|
Профессии |
Возможные вакансии |
Направления подготовки |
|
Менеджер |
Менеджер по персоналу Менеджер по рекламе |
380302 Менеджмент |
|
Системный администратор |
Математик-программист Информатик-аналитик Системный администратор |
010302 Прикладная математика и информатика 020303 Математическое обеспечение и администрирование информационных систем 090303 Прикладная информатика |
|
Программист |
Инженер по автоматизированным системам управления производством Техник-программист |
090301 Информатика и вычислительная техника 090302 Информационные системы и технологии 090304 Программная инженерия |
|
Преподаватель |
Учитель Педагог-психолог |
440302 Психолого-педагогическое образование 440305 Педагогическое образование |
Полученные в ходе тестирования результаты в 92 % случаев совпадают с данными профессиональных стандартов и единого квалификационного справочника должностей, что позволяет говорить о целесообразности применения метода латентно-семантического анализа для решения задач профессионального самоопределения.
Литература:
1. B. Chazelle. A Minimum Spanning Tree Algorithm with Inverse-Ackermann Type Complexity. Journal of the ACM. 2000. — 47 (6). — pp. 1028–1047.
2. Landauer T. K., Foltz P. W., & Laham D. Introduction to Latent Semantic Analysis // Discourse Processes, 1998. URL: http://lsa.colorado.edu/papers/dp1.LSAintro.pdf
3. Lewis, D. D., An evaluation of phrasal and clustered representations on a text categorization task. In Proceedings of SIGIR-92, 15th ACM International Conference on Researchand Development in Information Retrieval (Kobenhavn, DK, 1992), pp. 37–50.
4. TF-IDF:: A Single-Page Tutorial [Электронный ресурс] // Information Retrieval and Text Mining. URL: http://www.tfidf.com/ (дата обращения — 21.02.2015).
5. Макарова М. Ю., Самохина В. М. Информационная система поддержки принятия решений в процессе профессионального самоопределения // Молодой ученый. — 2015. — № 21. — С. 801–805.
6. Пескова, О. В. Методы автоматической классификации текстовых электронных документов // Научно- техническая информация. Сер. 2. — 2006. — № 3. — С. 13–20.
7. Репин, А.И., Смирнов, Н.И., Сабанин, В. Р. Технологии искусственного интеллекта в задачах диагностики информационных подсистем АСУТП // Сборник трудов конференции Control 2005. М.:Издательство МЭИ, 2005. С.19–25.
8. Чубукова, И. А. Data Mining. Учебное пособие. — М.: Интернет-Университет Информационных технологий; БИНОМ. Лаборатория знаний, 2006. — 382 с.
