





В статье рассматривается система для статического распознавания и верификации рукописной подписи с учетом глобальных особенностей подписи. Распознавание и верификация рукописных подписей осуществляется с помощью искусственной нейронной сети на основе метода обратного распространения ошибки. Анализируется различные показатели эффективности, такие как скорость обучения, ошибки 1-го и 2-го родов. Система была протестирована на 400 тестовых образцах подписей, которые включают в себя как истинные, так и поддельные образцы подписей двадцати человек.
Подпись является доказательством подлинности личности человека в биометрических системах контроля и управления доступом. Основным преимуществом использования распознавания подписи как метода верификации является тот факт, что большинство современных портативных компьютеров и электронных носимых устройств уже позволяют использовать рукописный ввод данных, поэтому нет никакой необходимости создания принципиально новых устройств биометрического сбора информации. В то же время существует очень мало систем для распознавания, которые могут обеспечить достаточно высокую точность распознавания, сохраняя приемлемый уровень эффективности.
Целью распознавания рукописной подписи является идентификация личности с целью распознавания и/или верификации. Распознавание — это идентификация личности владельца подписи. Верификация — это принятие решения, является ли данная подпись истинной или подделкой. Задачи распознавания и верификации имеют важное значение в области судебно-медицинской экспертизы, а также играют ключевую роль в системах безопасности банков и других организаций с повышенными требованиями безопасности к биометрическим системам контроля и управления доступом [1].
Системы для статического распознавания рукописных подписей являются более труднореализуемыми, чем системы с динамическим распознаванием, так как последние обладают дополнительными характеристиками, такими как длительность атомарной операции (например, процесса письма), сила нажатия, вектор направления письма и другими, которые упрощают окончательный процесс идентификации личности. Однако системы статического распознавания обладают одним важным достоинством — они не требуют доступа к дополнительным устройствам обработки поступающей информации (датчики, таймеры и т. д.). Данная статья рассматривает метод распознавания рукописной подписи, который применим в системах статического распознавания.
Высокая производительность метода нейронных сетей в задачах обработки и анализа рукописных подписей позволяет использовать его в решении проблемы распознавания и верификации подписей. Возможности постоянного обучения и обобщения, которыми обладают нейронные сети, позволяют эффективно справляться с проблемами разнообразия и изменчивости рукописных подписей. После первоначального обучения нейронной сети принятие решения о подлинности подписи, поданной на вход в систему, происходит с высокой скоростью, что является важным фактором для систем, обладающих большой базой данных подписей. Нейросетевой подход позволяет продолжать обучение на основе новых данных, введённых в систему и дополнительно эффективно анализировать изменчивость структуры конкретной подписи с течением времени.
В данной статье предложена система распознавания и верификации рукописной подписи, основанная на применении нейронных сетей с использованием метода обратного распространения ошибки. Блок-схема разработанной системы представлена на рисунке 1.
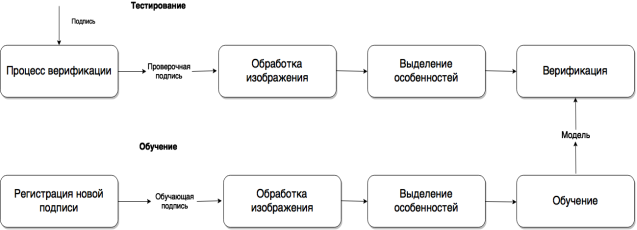
Рис. 1. Алгоритм работы системы распознавания и верификации подписей
Разработка любой системы обычно разбивается на взаимосвязанные логические этапы. Данная система распознавания и верификации подписи относится к системам статистического распознавания и для ее работы, первым этапом, было необходимо создать базу данных подписей.
Для создания базы данных были использованы образцы подписей 20 человек. Каждому человеку было предложено создать образец неперекрывающейся подписи черной ручкой на белом листе бумаги. В общей сложности было собрано 15 образцов подписи каждого человека для воссоздания особенностей индивидуальной вариации процесса создания рукописной подписи. Далее все образцы были занесены в базу данных и помечены как «подлинные». Поддельные подписи были получены от 5 добровольцев, задачей которых была подделка каждой из 20 подписей. Полученные данные были занесены в базу данных и помечены как «подделка». В общей сложности было получено 300 истинных образцов и 100 поддельных. Общий размер обучающей выборки составил 400 образцов.
С целью повышения общей эффективности процесса верификации было предпринято несколько шагов для предварительной обработки данных из обучающей выборки. Эти методы включают в себя нормализацию размера исходного изображения и сглаживание траектории написания. Подписи были получены путем сканирования в режиме «8 бит/300 точек на дюйм». Отсканированные изображения были обработаны в графическом редакторе. В результате были получены изображения исходного размера и ориентации. Поскольку подпись состоит из черных пикселей на белом фоне, изображение меняют, чтобы сделать белую подпись на черном фоне. Когда подпись сканируется, полученное изображение может содержать некоторые компоненты шума, например фоновый шум пикселей. Для удаления импульсного шума используется медианный фильтр. Различные подписи могут иметь персональные и межличностные различия, поэтому размер изображения нормируется по умолчанию. Масштабирование нормализует изображение по отношению и к ширине, и к высоте, однако остается проблема соотношения сторон. В качестве альтернативы, размер подписи может быть нормирован в соответствии с одним из размеров (высота или ширина), который не полностью удаляет размерные характеристики подписи писателя.
После обработки изображения следующим крайне важным в любой системе распознавания образов является этап выбора правильного набора характерных параметров изображения. Выбранные параметры должны позволять создавать эффективные классификаторы, используемые для обучения нейронных сетей.
Существует три типа параметров, применимых к задаче статистического распознавания рукописной подписи:
– глобальные, которые предоставляют информацию об общих случаях, касающихся структуры изображения;
– локальные параметры сетки, которые обеспечивают общую информацию о форме подписи по различным критериям;
– структурные параметры, которые предоставляют информацию о текстуре подписи.
В предложенной системе рассматриваются глобальные параметры и локальные параметры сетки. Глобальные параметры предоставляют информацию о конкретных случаях, касающихся общей структуры подписи. Для получения информации о параметрах сетки и текстуры изображение сегментируется на 96 прямоугольных областей. В каждой зоне используется только область (количество точек подписи) для формирования группы информационных параметров. Для формирования группы текстурных параметров используется более приближенная схема. Изображение подписи сегментируется только на шесть прямоугольных областей, в то время как для каждой области используется информация о переходе (градиент) белых и черных пикселей в четырех различных направлениях распространения.
Глобальные параметры должны определяться только после нормализации и скелетизации исходного изображения.
Параметр, характеризующий область изображения, при отсутствии предварительной обработки изображения, является причиной появления определенного числа черных пикселей на переднем плане изображения. В скелетизированном изображении он представляет собой меру плотности изображения подписи. Общая площадь изображения вычисляется суммированием числа белых пикселей в каждой колонке. Это и есть пиксельная область переднего плана изображения (т. е. область только самой подписи).
Параметр элементарной ширины и высоты определяет ширину изображения после удаления пустого пространства (промежутков) между символами по горизонтали. Высота и ширина подписи определяются как размер изображения после удаления промежутков между символами. Безопасное удаление части изображения достигается последовательным исключением строк (или столбцов) по краям изображения, при условии, что общее количество пикселей в строке (или столбце) меньше, чем два.
Параметр сдвига базовой линии, рассчитываемый как разность вертикального центра между левой и правой половинами изображения, применяется для компенсации изменения наклона изображения.
Параметры вертикального центра изображения Cv и максимальной горизонтальной проекции Pm используются для определения координат базовой линии подписи, и получаются из горизонтальной проекции Ph:
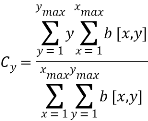
Параметры горизонтального центра подписи Cx и максимальной вертикальной проекции определяются из вертикальной проекции Pv:
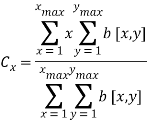
Параметры максимального значения вертикальной и горизонтальной проекций гистограммы принимаются равными значениям максимальных вертикальной и горизонтальной проекций соответственно.
Параметр угла наклона подписи в большинстве алгоритмов, встречающихся в литературе, посвященной распознаванию изображений, определяется только на основании анализа локальных свойств изображения и не учитывает глобальный характер наклона подписи [5]. В данной же системе, разработанной авторами, изображение поворачивается на 30 градусов по часовой стрелке при условии, что у подписи достаточно большой наклон. Затем изображение поворачивается против часовой стрелки на шаг, равный 2 градусам, и после вычисляется горизонтальная проекция изображения. Вращение изображения прекращается, когда горизонтальная проекция достигает своего максимума и угол наклона подписи представляет собой разницу между 30 градусами и углом, при котором горизонтальная проекция изображения является максимальной.
Параметр количества крайних точек изображения определяется по числу пикселей, у которых есть только один непосредственно соседний пиксель. Например, у буквы «T» есть только 3 крайних точки.
Параметр количества точек пересечения определяется по числу пикселей, имеющих три и более соседних пикселя. Например, буква «T» имеет одну точку пересечения.
Параметр числа замкнутых петель изображения может быть рассчитан по формуле:
CL = 1 + (EL — ЕР) / 2, где EP — количество крайних точек, EL — количество дополнительных отступов, которое определяется как разность суммы числа восьми соседей по всем точкам пересечения и двух. Количество замкнутых петель характеризует сложность связей линии подписи.
Для получения информации о параметрах сетки, как было уже сказано выше, скелетонизированое изображение делится на 96 прямоугольных сегментов (12 на 8), и для каждого сегмента вычисляется специальная область (сумма пикселей на переднем плане изображения). Результаты нормируются таким образом, чтобы меньшее значение (для прямоугольника с наименьшим числом черных пикселей) равнялось нулю, а большее значение (для прямоугольника с наибольшим числом черных пикселей) равнялось единице. Полученные 96 значений и формируют вектор характерной особенности сетки.
Представление изображения подписи и соответствующего вектора характерной особенности сетки показано на рисунке 2. Черный прямоугольник указывает на то, что в соответствующей области находится наибольшее число черных пикселей, а белый прямоугольник указывает соответственно на наименьшее число черных пикселей в области.

Рис. 2. Вектор характерной особенности сетки подписи
Описанные выше характерные параметры изображения являются входными параметрами нейронной сети распознавания и верификации подписи.
Первичная нейронная сеть обычно состоит из набора нормированных входных значений, расположенных в массиве, который принято называть входным вектором. Затем сеть обучают выдавать правильный выходной результат на определенные входные последовательности данных. Для повышения производительности дизайн архитектуры нейронных сетей, который включает в себя множество слоев, количество нейронов в каждом слое, начальные значения весов, тренировочных коэффициентов и возможности коррекции, должен быть корректно спроектирован [2].
Наиболее широко используемым алгоритмом для многослойной нейронной сети прямого распространения является алгоритм обратного распространения. Он базируется на Дельта-правиле [3], которое утверждает, что если разность (дельта) между желаемым выходом пользователя и фактическим выходом сети может быть еще минимизирована, то веса должны быть пересчитаны. Результат передаточной функции изменяет дельта-ошибку в выходных значениях. Ошибка в выходных значениях должна быть отрегулирована или полностью зафиксирована, только тогда ее можно будет использовать для коррекции весовых коэффициентов входного значения для достижения желаемого результата. Именно поэтому нейронные сети прямого распространения также часто называются сетями обратного распространения ошибки обучения. Сеть обратного распространения ошибки обучения подвергается контролируемому обучению с конечным числом пар шаблонов, состоящих из входного набора значений и желаемого выходного набора значений. Разработанная нейронная сеть была обучена путем модификации весов между слоями. Для каждой тренируемой итерации (периода обучения) ошибка была вычислена как разность между выходным значением и ожидаемым результатом. О производительности системы можно судить по результатам анализа коэффициентов ложного отказа и ложного распознавания (ошибок 1-го и 2-го родов). Коэффициентом ложного отказа является процент отвергнутых подлинных подписей, а коэффициентом ложного распознавания является процент ложных подписей, принятых за подлинные.
Разработанная авторами система распознавания и верификации подписи состоит из многослойных сетей обратного распространения ошибки. Входной слой состоит из 20 нейронов, каждый из них получает 14 выходных характерных параметра. Эти параметры нормированы средними значениями, вычисленными по 10 образцам подписей каждого человека. Выходной слой состоит из 20-элементноговектора с единицей на позиции конкретного человека и нулями на всех остальных. Сеть представляет собой двухслойный протокол сигмовидной нейронной сети, в которой используется функция передачи сигмовидного протокола, так как ее выходные значения (от нуля до единицы) подходят для обучения выходных булевых значений. Скрытый (первый) слой состоит из 10 нейронов. Каждый экземпляр подается в сеть отдельно и содержит выходные значения, которые сравниваются с ожидаемым результатом, а так же размер вычисленной ошибки. Вес входных значений корректируется таким образом, чтобы ошибка была минимальна. Этот процесс повторяется (многие периоды) до тех пор, пока не будут получены удовлетворительные результаты [4]. Обучение прекращается, когда полученная ошибка будет меньше определенного порогового значения или предела. Среднеквадратическая ошибка, равная 0.001, обозначает, что ошибка является допустимой. Для обучения системы было использовано 80 % от общего числа подписей в базе. Остальные 20 % использовались для тестирования системы распознавания и верификации подписи.
На этапе распознавания в качестве входных значений для нейронной сети использовались характерные особенности из проверочных образцов, и анализировались значения, наблюдаемые на выходе нейронной сети. Если выходное значение было близко к единице на верной позиции, то подпись проходила верификацию. Для распознавания было использовано 5 подлинных образцов подписей и часть образцов из обучающей выборки. Для процесса верификации была использована выборка «поддельных» подписей размерностью 5.
Предлагаемая система распознавания и верификации прошла обучение и тестирование на созданной авторами базе данных подписей. Были взяты 10 образцов подписей от обычных людей, около 12 проверочных образцов и 5 фальсифицированных. Производительность системы была рассчитана с помощью коэффициентов ложного отказа (ошибка 1-го рода) и ложного распознавания (ошибка 2-го рода). Экспериментальные результаты приведены в таблицах 1 и 2. Был получен коэффициент ложного отказа менее, чем 0,1, а коэффициент ложного распознавания был принят равным 0,2. Такие результаты доказывают, что предлагаемая система корректно отметила подлинные и фальсифицированные подписи.
Таблица 1
Результаты распознавания подписей
|
|
Выходное значение |
Образцы для верификации |
Ошибка 1-го рода |
||||
|
1 |
2 |
3 |
4 |
5 |
|||
|
Человек 1 |
1.00 |
0.9941 |
0.9537 |
0.9506 |
0.9783 |
0.9676 |
0.00 |
|
Человек 2 |
1.00 |
0.9972 |
0.9815 |
0.9966 |
0.9955 |
0.9678 |
0.00 |
|
Человек 3 |
1.00 |
1.0000 |
0.8933 |
0.6735 |
0.8770 |
0.9955 |
0.06 |
|
Человек 4 |
1.00 |
0.9354 |
0.9336 |
0.9296 |
0.9104 |
0.8562 |
0.00 |
|
Человек 5 |
1.00 |
0.6402 |
0.7484 |
0.7589 |
0.8529 |
0.3595 |
0.07 |
Таблица 2
Результаты верификации поддельных подписей
|
|
Выходное значение |
Образцы поддельных подписей |
Ошибка 2-го рода |
||||
|
1 |
2 |
3 |
4 |
5 |
|||
|
Человек 1 |
0.4 |
0.2332 |
0.0446 |
0.0227 |
0.0114 |
0.0073 |
0.0 |
|
Человек 2 |
0.4 |
0.2107 |
0.2345 |
0.2222 |
0.2075 |
0.2149 |
0.0 |
|
Человек 3 |
0.4 |
0.0130 |
0.0132 |
0.8481 |
0.0104 |
0.0102 |
0.2 |
|
Человек 4 |
0.4 |
0.0032 |
0.1157 |
0.3909 |
0.7029 |
0.1156 |
0.2 |
|
Человек 5 |
0.4 |
0.0100 |
0.0102 |
0.0103 |
0.0104 |
0.1040 |
0.0 |
Предложенная в данной работе структура системы для устойчивого статического распознавания рукописной подписи и верификации личности человека разработана с использованием нейросетевого подхода. В системе применен метод обратного распространения ошибки и доказана его эффективность при решении задач распознавания и верификации. Разработанная система обладает коэффициентами ложного отказа равным 0,1 и ложного распознавания равным 0,2. Полученные результаты можно улучшить с помощью уточнения и дополнения заданных классификаторов.
Литература:
- Kozin, N. E. Gradual learning the radial neural networks // Computer Optics. — 2004. — № 26. — С. 138–141.
- Cordot H., Revenu M., Victorri B., Revellet M.-J. A Static Signature Verification System Based on a Cooperetive Neural Networks Architecture // Pattern Recog. Artif. Intell. — 1994. — Vol. 8, № 3. — С. 679–692.
- Delta rule // Wikipedia. URL: https://en.wikipedia.org/wiki/Delta_rule (датаобращения: 13.05.2016).
- Ng. Geok See, Ong Hee Seng. A Neural Network Approach for Off-Line Signature Verification // IEEETENCON. — 1993. — Vol. 2. — C. 770–773.
- R. N. Nagel, A. Rosenfeld. Computer Detection of Freehand Forgeries// IEEE Transactions on Computers. — 1977. — Vol. 26, № 9. — С. 895–905.
