





Bu maqolada biz ma’lumotlarni intelektual taxlilida asosiy masalalardan biri bo’lgan klasterizatsiya masalasi va uni yechishda Weka APIdan foydalanish haqida so’z yuritamiz.
Kirish. Hozirgi kunda axborot kommunikatsion texnologiyalarning tez su’ratlarda rivojlanishi axborot tizimlarining ko’payishi va axborot xajmini keskin tarzda oshib borishiga sabab bo’ldi. Natijada, axborotlarni avtomatik tarzda tahlil qilib, katta hajmdagi axborotni ichindan bilimni aniqlash, ko’rsatkichlarning bir biri bilan bog’liqligi, bashoratlash va xulosalar chiqarish kabi masalalar dolzarb mavzuga aylanib bormoqda. Ma’lumotlarni intelektual tahlilining obyekti aynan shunday masalalarni yechishga yo’naltirilgan bo’lib, o’z ichiga Sinflarga ajratish (classsification), Klasterizatsiya (Clustering), Assosiativ qoidalarni izlash (Searing association rule) va Bashoratlash(Forecasting) kabi masalalarni qamrab oladi.
I. Klasterizatsiya.Klasterizatsiya-bu berilgan obyektlar toplamini xususiyatlari bo’yicha bir-biriga yaqin guruhlarga ajratishdir. Bunda bir biriga o’xshash obyektlar bir guruhga yig’ilishi va bu guruhlar iloji boricha bir biriga o’xshamasligi kerak. Bu guruhlar klasterlar deb ham yuritiladi. Misol uchun, quidagi rasmda berilgan obyektlar to’plamini 4 ta klasterga ajratish mumkin.
1-rasm. Obyektlar va ularni klasterlarga ajratilishi.
Bugungi kunda klasterizatsiya masalasini yechish uchun ko’plab uslublar va ular asosida birnechta algoritmlar ishlab chiqilgan. Lekin bu algoritmlarni hech biri optimal hisoblanmaydi. Ba’zi algoritmlar bir xil masalalarda to’g’ri klasterlarga ajratsa, shu algoritm boshqa masala uchun to’g’ri yechim qabul qila olmasligi mumkin. Mavjud algoritmlarni ishlash uslubiga qarab quidagi sinflarga ajratish mumkin:
Exclusive
Ketma-ketlikka asoslangan(Overlapping)
Daraxtsimon(Hierarchical)
Extimollik bo’yicha(Probabilistic)
Eksklusiv klasterlash algoritmlariga misol qilib k-means algoritmini, ketma-ketlikka asoslangan fuzzy c-means, ierarxik uchun CobWeb, extimollik bo’yicha qidiruvchi algorimlarga esa misol qilib EM algoritmini aytishimiz mumkin.
II. Masalaning qo’yilishi. Bizga katta hajmdagi obyektlar to’plami berilgan bo’lsin. Shu obyektlarni klasterizatsiya qilish uchun qaysi bir klasterizatsiya algoritmni mavjud obyektlar to’plami uchun optimal ekanligini aniqlash masalasi qo’yilgan bo’lsin.
III. Weka API. Yuqorida takidlangab o’tkanimizdek hech qaysi klasterizatsiya algoritmi istalgan obyektlar to’plami uchun eng optimal bo’la olmaydi. Shu sababli biz katta obyektlar to’plamiz ixtiyoriy tanlangan qismini ajratib olgan xolda ular ustida birnechta eng ko’p qo’llaniladigan algoritmlar bilan tajriba o’tkazib ularni solishtrib ko’rishimiz kerak. Buni oson hal qilish uchun Weka API (Application Programming Interface) dan foydalanish ish jarayonini osonlashtiradi.
Weka API Yangi Zerlandiyaning Waikato Universiteti tomonidan Ma’lumotlarni intellectual taxlili masalalarini yechish uchun ishlab chiqilgan bo'lib, sinflarga ajratish, klasterizatsiya, bashoratlash, assotativ qoidalarni qurish va vizualizatsiya masalalarini yechish uchun bir nechta algotirmlarni o’z ichiga oladi. Weka API Java dasturlash tilida yaratilgan. Bu maqolada, algoritmlarni ishlash vaqti, egallaydigan hotira hajmi kabi ko’rsatkichlarini hisoblash maqsadida, undan qo’shimcha kutubxona sifatida foydalanamiz. Wekada klasterizatsiya masalalarini yechish uchun weka.clusterers paketi mavjud. Bu paket o’z ichiga quidagi klasterizatsiya algoritmlarini oladi:
|
CLOPE |
FarthestFirst |
|
Cobweb |
OPTICS |
|
DBSCAN |
SimpleKMeans |
|
EM |
XMeans |
1-jadval- Weka APIdagi klasterizatsiya algoritmlari
Mazkur maqolada yuqorida keltirilgan algoritmlardan eng ko’p ishlatiladiganlari: k-means, CobWeb, EM va DBScan algoritmlarini ko’rib o’tamiz.
IV. Klasterizatsiya algoritmlari.
4.1 K-Means. Ma’lumotlarni intelektual tahlilida k-means klasterizatsiya algoritmi eng sodda, eng tushunarli va eng ko’p ishlatiladigan algoritmlardan biri xisoblanadi. K-means algoritmi berilgan n ta obyektdan iborat toplamni bir biriga o’xshash obyektlardan iborat k ta guruhga ajratadi. Bu algoritm uchun k-guruhlar soni aniq belgilangan bo’lishi kerak. Algoritmning asosiy g’oyasi k ta markazni ushlab olish va obyektlarni shu markazlar atrofiga yig’ib chiqishdan iborat. Bunda obyektlar k ta markazdan qaysi biriga yaqin bo’lsa shu guruhga qo’shib olinadi. K-means algoritmida obyektlar orasidagi masofalarni hisoblash uchun Evklid masofasi, Manhetton masofasi kabilar ishlatiladi. Algoritmni asosiy abzalligi uni ishlash tezligida, k-means boshqa olgaritmlarga qaraganda tezroq ishlaydi. Lekin unga guruh(klaster)lar sonini oldindan ko’rsatish kerak. Bu k-means algoritmini eng katta kamchiligi hisoblanadi.
3.2 EM(Expectation Maximization). EM algoritmi ham k-means algoritmi kabi iterativ usulda klasterlarga ajratishga mo’ljallangan. K-means yaxshi natija ko’rsatadigan barcha to’plamalar uchun EM ham yaxshi natija ko’rsata oladi. Bu algoritm statik ma’lumotlar bazasi uchun mo’ljallangan. EM obyektlarni bir biriga o’xshashligini masofa bo’yicha emas, extimollik orqali hisoblaydi, va bu bazi holatlarda yaxshi natija berishi mumkin. Chiziqli bo’lmagan xolatlarda k-means guruhlarga ajratishda xatolikka yo’l qo’yadi, EM esa bu holatlarda ancha yaxshi natija beradi. EM real ma’lumotlar uchun boshqa algoritmlarga qaraganda yaxshi natija ko’rsatadi. Kamchiligi bir biriga yaqin joylashgan obyektlarni klasterlashda ko’pincha xatolikka yo’l qo’yadi, ishlash tezligi boshqa algoritmlarga nisbatan sekinroq.
3.3 CobWeb. CobWeb algoritmi 1980 yilda yaratilgan. Bu algoritm ierarxik klasterlash algoritmlari qatoriga kiradi. Klassifikatsiya daraxti asosiga qurilgan. Berilgan obyektlarni extimollik bo’yicha qaysi sinfga tegishli ekanligini aniqlab, daraxtga barg sifatida qo’shib qo’yadi. Algoritm k-means, EM algoritmlarida uchramaydigan ko’plab imkoniyatlarga ega. Masalan CobWeb algoritmi dinamik ma’lumotlarni klasterlashda ham ishlatiladi. Yangi obyektni kiritish va uni qaysi sinfga tegishli ekanligini aniqlash uchun update funksiyasi ishlatiladi, va bu amal log(n) vaqtda bajariladi. Klasterlar sonini avtomatik tarzda aniqlaydi. Bundan tashqari so’ngi qo’shilgan obyektlarni o’chirib tashlash ham mumkin. Bir so’z bilan aytganda online tarzda klasterlash uchun CobWeb algoritmi juda samarali. Lekin bu algoritm k-means kabi barcha xolatlar uchun yaxshi yechim topa olmaydi, ko’pincha klasterlarga ajratishda xatoliklarga yo’q qo’yadi. Ma’lumotlarni berilish taribi, klasterlash natijasiga tasir ko’rsatadi.
3.4 DBScan. DBScan algoritmi Martin Ester, Hans-Peter, Jorge Sander va Xiaowei Xu tomonidan 1996 yilda yaratilgan. Bu algoritm zichlikka asoslangan. Klasterlar soni o’zi aniqlab oladi. Obyektlarni berilish tartibini axamiyati yo’q, har qanday tartibda berilganda ham bir xil natija chiqaradi. Bu algoritm bugungi kundagi eng optimal algoritmlardan biri xisoblanadi. Bu algoritmni asosiga OPTICS algoritmi ham qurilgan. Tezkor, klasterlash uchun k-means kabi samarali algoritm. Kamchiligi sifatida bu algoritmni masofani topish bo’yicha ishlashida deb aytish mumkin. Chunki bazi holatlarda masofani Evklid masofasi bo’yicha olgan foydali bo’lsa, bazan Manhetton va shunga o’xshagan masofa formulalari yaxshi samara beradi.
|
1. K-Means |
2. EM |
3. CobWeb |
4. DBScan |
|
|
Natija: |
Klasterlar: 0. 50 ( 33%) 1. 50 ( 33%) 2. 50 ( 33%) |
Klasterlar: 0. 52 ( 35%) 1. 50 ( 33%) 2. 48 ( 32%) |
Klasterlar: 1. 50 ( 33%) 2. 50 ( 33%) 3. 50 ( 33%) |
Klasterlar: 0. 50 ( 33%) 1. 50 ( 33%) 2. 50 ( 33%) |
|
O’rtacha vaqt: |
188,8 ms |
372,6 ms |
197,6 ms |
349,2 ms |
|
O’rtacha xotira: |
3825 kb |
6078 kb |
4214 kb |
5125 kb |
V. Tajriba natijalari. Algoritmlar bilan tajriba o’tirish va natijalarni taxlil qilish uchun eng ko’p ishlatiladigan Iris nomli obyektlar to’plamini olamiz. Bu to’plam iris oilasiga mansub bo’lgan o’simliklar toplamidan iborat bo’lgan to’plam hisoblanadi. Unda jami 3 ta (Iris Setosa,
Iris Versicolour, Iris Virginica) tipdagi gullarning parametrlari berilgan. Jami attributlar soni 5 ta, ularning oxirgisi sinf atributi. Bu yerda jami 150 ta obyekt keltirilgan bo’lib ularning 50 tasi Iris Setosa, 50 tasi Iris Versicolour va qolgan 50 tasi Iris Virginica turiga mansub.
Yuqorida sanab o’tilgan algoritmlar o’zi ichida tasodifiy qiymatlardan foydalanadi shuning uchun ularning aynan bir xil obyektlar to’plamini klasterlarga ajratish uchun ketadigan vaqti va hotirasi xar xil bo’lishi mumkin. Shu sababda ularni ishlash vaqtini va xotira hajmini o’rtacha qiymatlarini olamiz. Quidagi jadvalda olingan natijalar aks etgan:
2-jadval. Tajriba natijalari
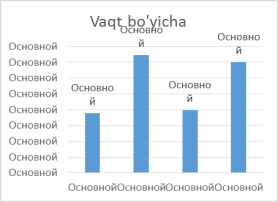
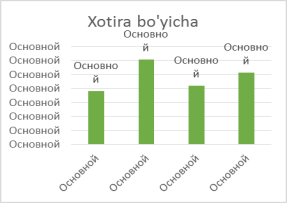
1-rasm. Algoritmlarning ishlash vaqti va xotira hajmlari
V. Xulosa. Iris obyektlar to’plamidan olingan natijalar shuni ko’rsatadiki, vaqt va xotira bo’yicha eng yaxshi algoritm bu k-means. EM algoritmi klasterlarga ajratishda biroz xatolikka yo’l qo’ygan. DBScan va CobWeb algoritmlari klasterlarga to’g’ri ajratgan, k-meansga qaraganda ko’p vaqt va xotira ishlatgan bo’lsada, undagi klasterlar sonini avtomatik aniqlagani uchun bu algoritmlarni ham optimal deb hisoblashimiz mumkin.
Foydalanilgan adabiyotlar
- http://home.deib.polimi.it/matteucc/Clustering/tutorial_html/
